分布式追踪系统:Zipkin与TDist实现解析
124 浏览量
更新于2024-08-27
收藏 304KB PDF 举报
"分布式追踪系统是现代微服务架构中不可或缺的一部分,它帮助开发者理解复杂的分布式系统中的请求流程和性能瓶颈。本章主要介绍了一个具体的分布式追踪系统架构与设计,包括选用的工具、数据模型以及实现细节。"
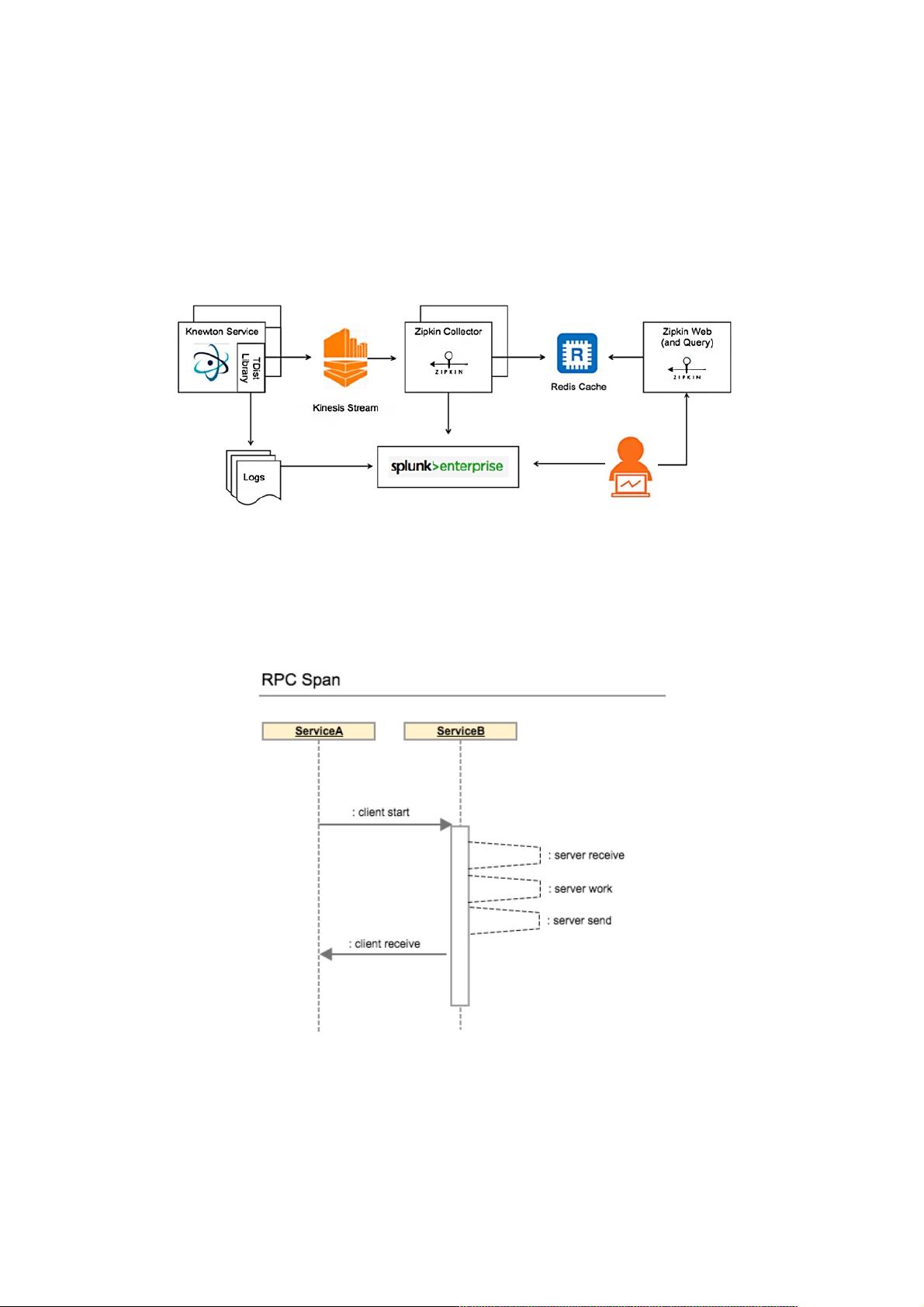
在分布式追踪系统架构与设计中,首要任务是确保所有服务能够有效地集成到追踪库中。文中提到了一个解决方案,即在每个服务中嵌入追踪库,并分配内存来存储和查看追踪数据。这里选择了Zipkin作为基础,因为它是Twitter开发的一个可扩展的开源追踪框架,特别适合存储和展示追踪信息。尽管Zipkin通常与Finagle一起使用,但为了避免与现有基础设施的冲突,文中并未采用这种方式。
Zipkin的数据模型借鉴了Dapper的设计,将追踪信息表示为一系列的跨度(span)。每个跨度代表了从服务器接收请求到发送响应的过程,这其中包括了服务器间的通信。一个完整的追踪树是由多个跨度组成的,每个跨度都有自己的标识(SpanID),并可能有父跨度标识(ParentSpanID),共同组成一个TraceID,使得整个调用链路可被追踪。这种数据模型清晰地展现了请求在系统中的流转路径。
Knewton开发的TDist库是针对其特定需求的一个实现。TDist是一个Java库,它可以跨多种协议(如Thrift、HTTP和Kafka)追踪应用程序,并且能追踪注解过的Guice方法调用。通过在每个线程中分配和传播跨度,TDist可以在后台处理追踪数据。当接收到请求或准备发出请求时,追踪信息会被放入内部队列,由工作线程消费并发布到追踪消息总线。线程局部存储(JavaThreadLocal)在这里起到了关键作用,允许在不同线程间安全地传递追踪数据。
总结来说,分布式追踪系统的核心在于收集、存储和分析跨越多个服务的调用链路信息。Zipkin提供了数据模型和存储机制,而TDist则是一个实际应用的例子,展示了如何在Java环境中实现这一目标。通过对请求流程的可视化,开发者可以更好地诊断问题,优化性能,从而提升整体系统效能。
分布式追踪系统架构与设计分布式追踪系统架构与设计
这个章节将会更加深入探讨技术细节,我们如何实施分布式追踪系统的。
总体结构与追踪数据管理
我们的方案分为两大部分:所有服务集成到追踪库中,分配一个内存块来存储与查看追踪数据。我们选择Zipkin,在Twitter开
发的一个可扩展的开源追踪框架,用于存储与查看追踪数据。Zipkin通常以Finagle对的形式出现,但是,像上一节提及的一
样,我们排除了与我们现有基础设施冲突的并发症。Knewton构建追踪库,称为TDist,从地面起,开始作为公司“黑客日”的实
验。
追踪数据模型
就我们的方案而言,我们选择使用Zipkin来匹配数据模型,轮流从Dapper大量借入。一个追踪树由一系列的跨度组成。跨度代
表一个特殊的呼叫从服务器接收开始,到服务器发送,最后是客户端接收。举个例子,在服务器A和服务器B之间的呼叫与响
应将会作为一个简单的跨度:
Trace ID:一个轨迹中所有的跨度(span)共享同一个Trace ID。
Span ID:用以标示不同的跨度(span)。Span ID与Trace ID不一定相同。
Parent Span ID: 只有子跨度持有这个ID,根跨度没有Parent Span ID。
下面的图展示了在一个树结构的调用中,上面三个ID是如何应用的。注意在整个树结构中Trace ID是一致的。
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-10-14 上传
2018-11-06 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38706055
- 粉丝: 5
- 资源: 908
 我的内容管理
展开
我的内容管理
展开







最新资源
- 虚拟人中台相关方案文档
- unity 3D文字系统源码VText.zip
- madgrad:MADGRAD的JAX实现
- SimpleHUD:SimpleHUD是一款易于使用但美观的Android HUD(或对话框)
- 汇编语言程序设计(资料+视频教程).rar
- 信呼协同办公OA系统 v2.1.8
- meelouth.github.io:网站
- bank-java:一个用 Java 编写的带有 GUI 的基本银行程序
- 亚马逊交易-crx插件
- stylex
- Data-Analysis-Project-in-Python:Python中Fifa 18数据集的数据分析。 该项目包括可视化和用于预测目的的机器学习
- glslmath:C ++仅限头文件的库,可模拟GLSL数学-开源
- TongYWPF.Template.NumberOne202303DemoK
- 剁手党买家秀助手-crx插件
- ExpandTabView-master
- React
