BERT:NLP预训练模型的革新
版权申诉
47 浏览量
更新于2024-08-04
1
收藏 1.04MB PDF 举报
NLP领域正在经历一场深刻的变革,从传统的基于规则的方法逐渐转向预训练模型的时代。论文《NLP进入预训练模型时代:从word2vec, ELMo到BERT》概述了这一转变的关键里程碑,特别是word2vec、ELMo和BERT这三大模型的发展与影响。
word2vec, 由Google在2013年推出,是一个革命性的模型,它通过构建一个线性语言模型,将词向量的学习与线性语义运算相结合,极大地简化了NLP任务。它的核心在于使用“负采样”技术,这是一种创新的优化策略,替代了传统softmax方法,有效解决了大规模词汇表带来的计算难题。尽管起初被视为预训练的辅助手段,word2vec因其高效性和广泛的应用,在早期的NLP中占据了重要地位。
紧接着,ELMo(Embeddings from Language Models)在2018年进一步提升了预训练的影响力。ELMo引入了上下文感知的词嵌入,即同一个词在不同上下文中可能有不同的含义,通过捕捉词语在句子中的动态语境,使得模型能够更好地理解和处理复杂的语言结构。ELMo的出现标志着预训练模型开始从任务特定网络的附属角色转向核心地位。
然而,BERT(Bidirectional Encoder Representations from Transformers)的发布真正开启了预训练模型的新篇章。BERT是基于Transformer架构的双向Transformer模型,它在大规模文本数据上进行无监督预训练,然后在各种下游任务中微调,显著提高了NLP任务的性能。BERT的特点在于其双向上下文理解能力,不仅考虑当前词的前后文,还能捕获更丰富的语言信息。BERT的出现不仅改变了NLP领域的研究方向,还推动了迁移学习和无监督学习在NLP中的广泛应用。
总结起来,word2vec、ELMo和BERT这三个模型代表了NLP预训练模型发展的三个阶段:词向量的初步探索、上下文敏感性的提升和深度双向模型的革新。它们不仅提升了NLP任务的准确性和效率,也重塑了研究者对NLP游戏规则的理解,预训练模型已经成为现代NLP不可或缺的基石。随着技术的进步,未来的预训练模型可能会更加智能和灵活,进一步推动NLP技术的革新与发展。
NLP的游戏规则从此改写?从word2vec, ELMo到BERT
原创
⼣⼩瑶
2018-10-23⼣⼩瑶的卖萌屋
来⾃专辑
卖萌屋@⾃然语⾔处理
前⾔
还记得不久之前的机器阅读理解领域,微软和阿⾥在SQuAD上分别以R-Net+和SLQA超过⼈类,百度在MS MARCO上凭借
V-Net霸榜并在BLEU上超过⼈类。这些⽹络可以说⼀个⽐⼀个复杂,似乎“如何设计出⼀个更work的task-specific的⽹络"变
成了NLP领域政治正确的研究⽅向。⽽在这种⻛向下,不管word2vec也好,glove也好,fasttext也好,都只能充当⼀个锦上
添花的作⽤。说好的迁移学习、预训练呢?在NLP似乎始终没成主⻆。
⼩⼣写这篇⽂章时也有点惭愧,搞了好⼀段时间的表⽰与迁移,虽然早在直觉上感觉这应该是NLP的核⼼问题,但是也没做
出⼀些令⾃⼰满意的实验结果,直到⼏天前的BERT出来,才感觉是贫穷限制了我的想象⼒╮( ̄▽ ̄””)╭(划掉),才感觉
⾃⼰着眼的点还是太窄了。
每个⼈对于BERT的理解都不⼀样,本⽂就试着从word2vec和ELMo的⻆度说说BERT。下⾯先简单回顾⼀下word2vec和
ELMo中的精华,已经理解很透彻的⼩伙伴可以快速下拉到BERT章节啦。
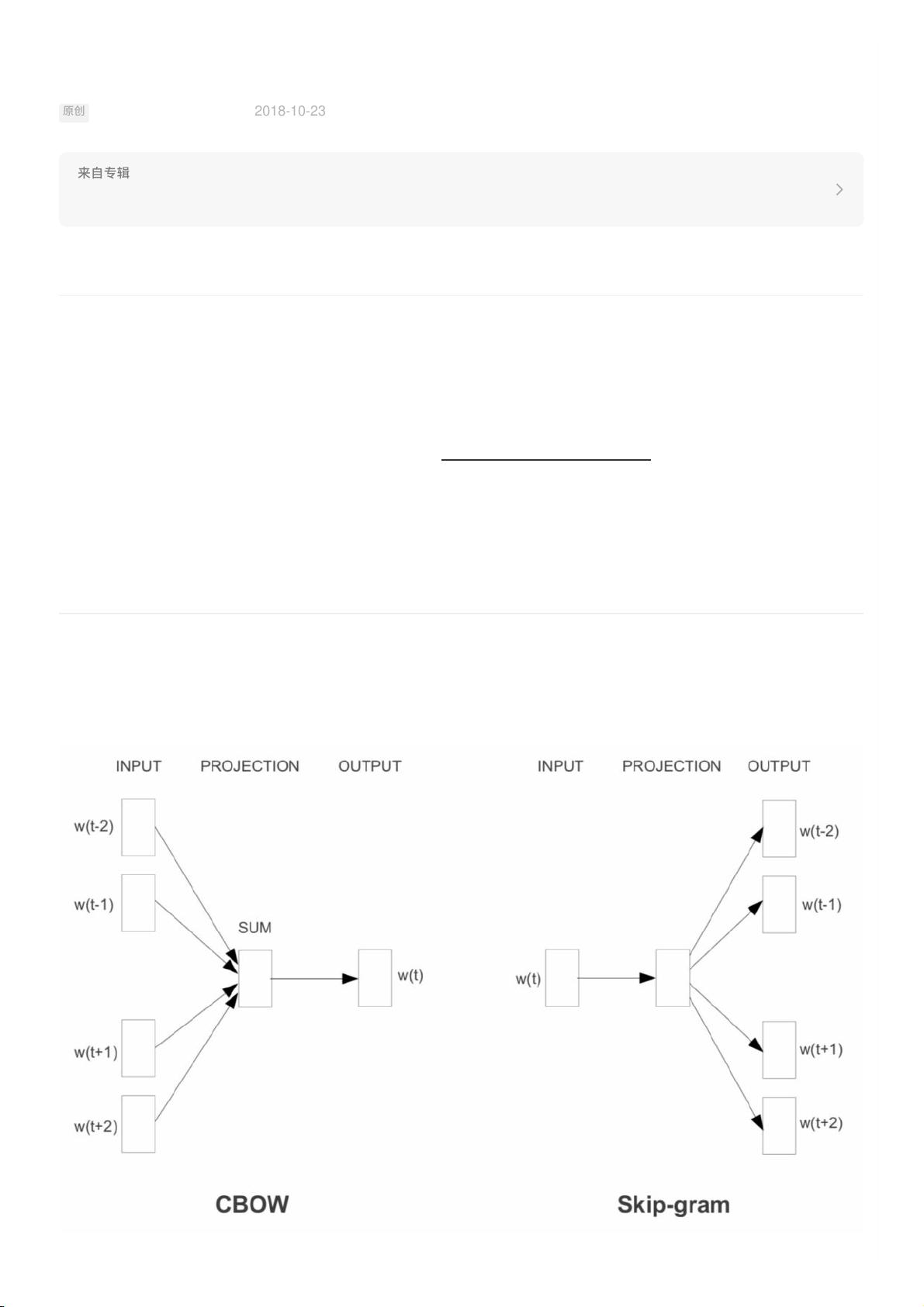
word2vec
说来也都是些俗套⽽乐此不疲⼀遍遍写的句⼦,2013年Google的word2vec⼀出,让NLP各个领域遍地开花,⼀时间好像不
⽤上预训练的词向量都不好意思写论⽂了。⽽word2vec是什么呢?
模型
下载后可阅读完整内容,剩余8页未读,立即下载
2023-10-18 上传
2023-10-18 上传
2021-09-01 上传
2023-08-21 上传
2023-07-17 上传
2023-12-14 上传
2023-02-06 上传
2023-06-02 上传
2023-07-17 上传

普通网友
- 粉丝: 1272
- 资源: 5619
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
