大数据分析师竞赛理论试题与解析
需积分: 5 164 浏览量
更新于2024-07-09
1
收藏 1.27MB PDF 举报
"这份资料是2021年大数据分析师竞赛的理论试题,涵盖了大数据、数据分析竞赛相关的知识,包括数据挖掘、SQL操作、统计分析方法、机器学习算法等多个方面。"
1. Apriori算法是一种经典的关联规则学习算法,用于在交易数据中找出频繁项集。它使用"最小支持度(MinimumSupport)"这一指标来筛选项目集,剔除不满足支持度阈值的项。
2. 在SQL语言中,若要删除一个表的所有数据但保留表结构,应使用`TRUNCATE`命令,而非题目中的选项。但提供的选项中没有`TRUNCATE`,最接近的是`DELETE`,但它通常会删除数据并记录日志,效率较低。
3. 变量的量纲,即单位,会影响统计分析中的某些方法。例如,量纲不同的变量在进行方差分析(ANOVA)时需要进行标准化或归一化处理,以免单位差异影响结果。而回归分析、聚类分析和主成分分析在一定程度上对量纲不敏感。
4. 分类算法是一种预测建模技术,如C4.5决策树算法,用于将数据分为预定义类别。DBSCAN是一种聚类算法,K-Mean也是聚类算法,而EM是期望最大化算法,常用于混合高斯模型的参数估计,不属于分类算法。
5. 分析顾客消费行为以推荐服务是关联规则挖掘的问题,通过发现商品间的购买关联,实现个性化推荐。
6. 关联规则的评价指标通常包括支持度和支持度,以及置信度。这些指标衡量了规则的频繁程度和可信度。均方误差等是回归模型的评估指标,Kappa统计和显著性检验适用于分类任务。
7. 回归分析的首要任务是建立回归模型,确定解释变量和被解释变量之间的关系,以便预测或解释被解释变量的变化。
8. K均值聚类算法需要预先指定聚类个数,而层次聚类、基于密度的聚类和基于网格的聚类则可以不指定。
9. 描述的聚类方法是系统聚类(Hierarchical Clustering),通过合并最近的类逐步构建层次结构。
10. 当数据量较大时,快速聚类算法如k-means较适合,因为它具有较高的计算效率。
11. KDD全称为数据挖掘与知识发现(Knowledge Discovery in Databases),是数据科学中的重要过程,旨在从大量数据中发现有价值的信息和知识。
12. DBSCAN算法适合处理非凸形状的数据分布,如SS形(可能表示为“星形”或“丝带形”),它能发现任意形状的聚类且不需要预先指定聚类数量。
13. Naive Bayes算法是一种分类方法,基于贝叶斯定理和特征条件独立假设。
14. Apriori算法和FP-Tree算法是关联规则学习中的算法,用于发现项集之间的频繁模式。而决策树、对数回归、K均值法、SOM神经网络、RBF神经网络等属于其他类型的算法。
以上知识点详细解析了大数据分析师竞赛中的理论题目,涵盖了数据挖掘、数据库操作、统计分析和机器学习等多个核心领域。
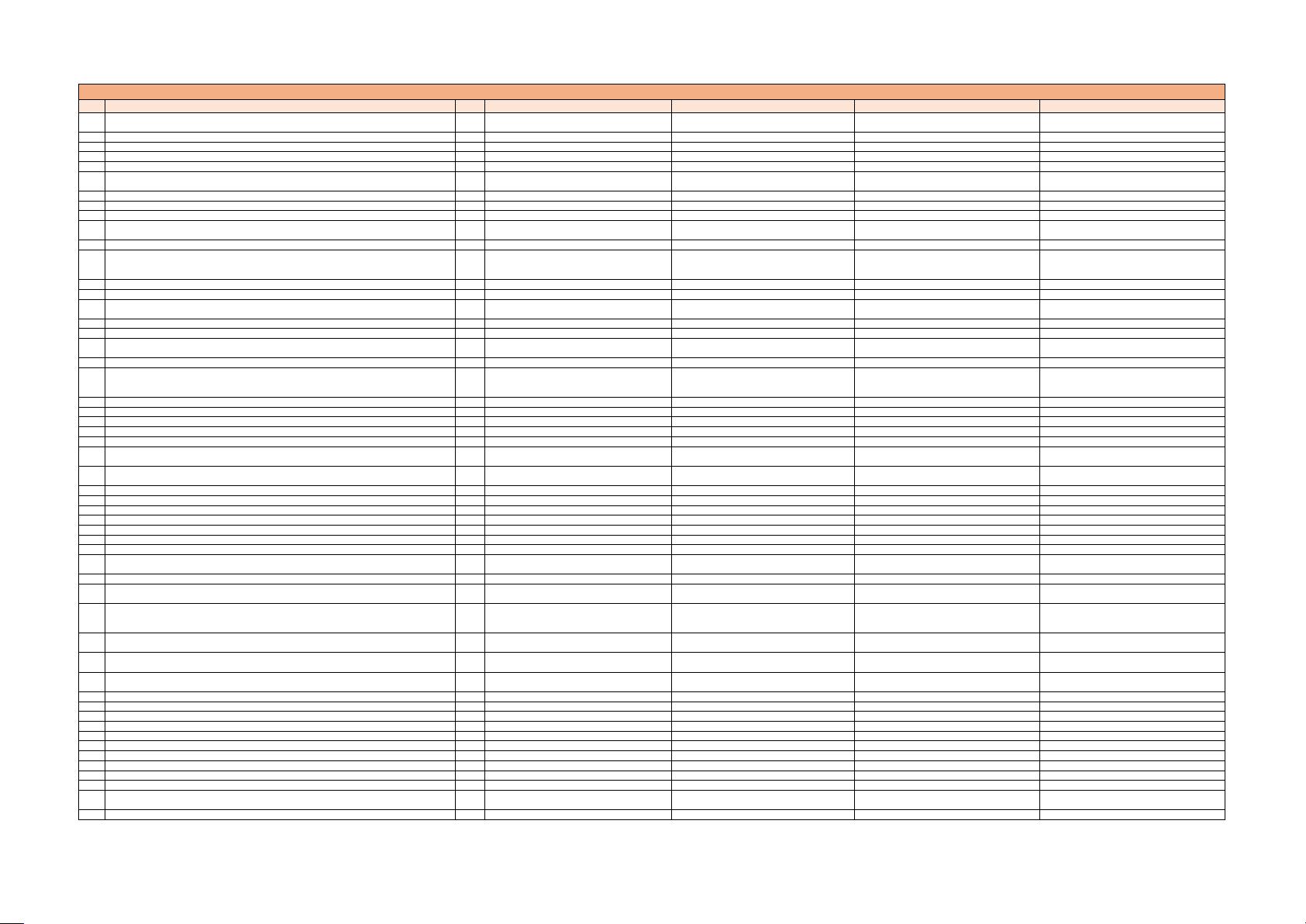
序号 题干 题型 选项A 选项B 选项C 选项D
大数据分析师赛项——理论题库(1000道)
149 以下有关主成分分析,正确的是( )。 单选题
保留多少个主成分取决于累计方差在方差总和中所
占百分比
一般选择 50%以上 选择前两个就可以 选择的数目和变量的个数一致
150 在 ID3算法中信息增益是指( )。 单选题 信息的溢出程度 信息的增加效益 熵增加的程度最大 熵减少的程度最大
151 指数平滑法中,下面哪个指标可以反映对时间序列资料的修正程度?( ) 单选题 平滑常数 季节指数 跨越期 指数平滑数初始值
152 Hbase中的Compaction过程发生在什么时候?( ) 单选题 MemStore发生flush的时候 HLog大小达到一定阈值的时候 StoreFile文件个数达到一定阈值的时候 HFile写入HDFS的时候
153 Hbase中以下对于LSM的描述正确的是( )。 单选题 LSM的读操作和写操作是独立 LSM的读操作和写操作不是独立 LSM并不区分读和写 LSM中读写是同一种操作
154 如果要给队列QueueA设置容量为30%,应该设置哪个参数( )? 单选题
yarn.scheduler.capacity.root.QueueA.minimum-
user-limit-percent
yarn.scheduler.capacity.root.QueueD.user-
limit-factor
yarn.scheduler.capacity.root.QueueA.capacity yarn.scheduler.capacity.root.QueueA.state
155 Spark是用以下哪种编程语言实现的( )? 单选题 C C++ JAVA Scala
156 关于Hive中的桶说法不正确的是( )? 单选题 每个桶是一个目录 建表时指定桶个数,桶内可排序 数据按照某个字段的值Hash后放入某个桶中 对于数据抽样、特定join的优化很有意义
157 哪一项不属于Hive的流控特性( )? 单选题 已经建立的总连接数阈值控制 某个特定用户已经建立的连接数阈值控制 每个用户已经建立的连接数阈值控制 单位时间内所建立的连接数阈值控制
158 下面对Streaming中基础概念说法不正确的是( )? 单选题 Topology是streaming中运行的一个实时应用程序 Nimbus负责资源分配和任务调度
Spout是在一个topology中接受数据然后执行处理
的组件
Worker运行具体处理组件逻辑的进程
159 Flume支持多级级联的sink类型是( )? 单选题 hdfs sink avro sink file roll sink hbase sink
160 关于Kafka的基本概念描述错误的是( )? 单选题
Kafka集群包含一个或多个服务实例,这些服务实例
被称为Broker
每条发布到Kafka集群的消息都有一个类别,这个
类别被称为Topic
每个Consumer属于多个的Consumer Group
Kafka将Topic分成一个或者多个Partition,每个
Partition在物理上对应一个文件夹,该文件夹下存
储这个Partition的所有消息
161 如下哪项不是ZooKeeper的关键特性( )? 单选题 最终一致性 延时性 可靠性 等待无关性
162 下列选项中无法通过大数据技术实现的是?( ) 单选题 商业模式发现 信用评估 商品推荐 运营分析
163
假设每个用户最低资源保障设置为yarn,scheduler,capacity,root,QueueAminimum-user-
limit-percent=24,则以下说法错误的是?( )
单选题
第3个用户提交任务时,每个用户最多获得33.33%
的资源
第2个用户提交住务时,每个用户最多获得50%的资
源
第4个用户提交任务时,每个用户最多获得25%的资
源
第5个用户提交任务时,每个用户最多获得20%的资
源
164 Spark自带的资源管理框架是?( ) 单选题 Standal one Mesos YARN Docker
165 关于RDD,下列说法错误的是?( ) 单选题 RDD具有血统机制(Lineage) RDD默认存储在磁盘 RD是一个只读的,可分区的分布式数据集 RD是Spark对基础数据的抽象
166 关于Hive 在Fusioninsight HD 中的架构描述错误的是?( ) 单选题
只要有一个Hiveserver 不可用,整个Hive 集群便不
可用。
Motastore 用于提供元数据服务,依赖于
DBService
在同一时间点,HiveServer 只要一个处于Active 状
态,另一个则处于Standby 状态
Hiveserver 负责接收客户端请求,解析,执行 HQL
命令并返回查询结果
167 大数据时代, 数据使用的关键是( ) 单选题 数据收集 数据存储 数据分析 数据再利用
168 下列关于数据交易市场的说法中, 错误的是( ) 。 单选题 数据交易市场是大数据产业发展到一定程度的产物
商业化的数据交易活动催生了多方参与的第三方数
据交易市场
数据交易
市场通过生产数据、 研发和分析数据, 为数据交易
提供帮助
数据交易市场是大数据资源化的必然产物
169 在Fusioninsiehtaanarer 界面中,对Loader 的操作不包括下列哪个选项?( ) 单选题 切换Loader 主备节点 启动Loader 实例 配置Loader 参数 查看Loader 服务状态
170 创建Loader 作业中,可以在以下哪个步骤中设置过滤器类型?( ) 单选题 输入设置 转换 基本信息 输出
171 kafka-cluster mirroring 工具可以实现以下那些功能?( ) 单选题 kafka 集群数据同步方案 kafka 单集群内数据备份 kafka 单集群内数据恢复 以全部不对
172 以下关于Kafka Partition 偏移量的描述不正确的是?() 单选题 每条消息在文件中的位置称为offset(偏移量) 消费者通过( offset/.partition. topic)跟踪记录 唯一标记一条消息 Offset 是一个String 型字符串
173 RDD 有Transformation 和Action 算子,下列属于Action 算子的是?( ) 单选题 map saveASTexFile Filter reducebykey
174 以下关于Hive SQL 基本操作描述正确的是?( ) 单选题 创建外部表必须要指定Location 信息
创建外部表使用external 关键字,创建普通表需要指
定internal 关键字
加教数据到Hive 时源数据必列是HDFS 的一个路径 创建表时可以指定列分割符
175
在Zookeeper 和Yarn 的协同工作中,当Active Resourcemanager 产生故障时, Standby
Resourcemanager 会从以下哪些目录中获取Application 相关信息?( )
单选题 metastore Statestore Statestore Warehouse
176 HDFS 的副本放置策略中,同一机架不同的服务器之间的距离是( ) 单选题 3 2 1 4
177 Zookeeper 的Scheme 认证方式不包括以下哪项?() 单选题 digest sasl auth world
178 下列选项中适合Mapreduce 的场景( ) 单选题 实时交互计算 迭代计算 流式计算 离线计算
179 下列哪个命令是从HDFS 下载日录/文件到本地的?( ) 单选题 dfs -put dfs -cat dfs -get dfs -mkdir
180 Hbase 的主Master 是如何选举的? 单选题 由Regionserver 进行裁决 Master 为双主模式,不需要进行裁决 通过Zookeeper 进行裁决 随机选举
181 关于Hive 与Hadoop 其他组件的关系。以下描述错误的是?( ) 单选题 Hive 最终将数据存储在HDFS 中 Hive 是Hadoop 平台的数据仓库工具 HQL 可以通过Mapreduce 执行任务 Hive 对Hbase 有强依赖
182 Hbase 的Region 是由哪个服务进程来管理的?( ) 单选题 HRegionserver Zookeeper HMaster DataNode
183 以下关于Flink 关键特性描述不正确的是? 单选题 Sparkstreaming 与Flink 相比,时延更低
F1ink 流式处理引擎能够同时提供支持流处理和批
处理应用的功能
与Fusioninght HD 中的Streaming 相比,FIink 具
有更高的吞吐量
checkpoint 实现了Flink 的容错
184 Kafka Cluster Mirroring 工具可以实现以下哪项功能? 单选题 Kafka 跨集群数据同步方式 Kafka 单集群内数据备份 Kafka 单集群内数据恢复 以上全不正确
185 Fusion insight 产品中,关乎Kafka 说法不正确的是? 单选题 Kafka 强依赖Zookeeper Kafka 的服务端可以产生消息 Kafka 的部署的实例个数不得小于 2
Consumer 作为Kafka 的客户端角色专门进行消息
的消费
186
为了提高Kafka 的容错性, Kafka 支持Partition 的复制策略,以下关于Leader Partition和Follow
Partition 的描述错误的是( )
单选题
Kafka 针对Partition 的复制需要选出一个Leader。
由该Leader 负责Partition 的读写操作。其他的副本
节点只是负责数据同步
由于Leader Server 承載了全部的请求压力。因此
从集群的整体考虑, Kafka 会将Leader.均衡的分散
在每个实例上,来确保数据均衡
一个Kafka 集群各个节点间不可能互为Leader 和
Flower
如果Leader 失效。那么将会有其他fol lower 来接
管(成为新的Leader)
187 下列关于Flink barrier 描述错误的是? 单选题
一个barrier 将本周期快照的数据与下ー个周期快照
的数据分隔开来
barrier 是F1ink 快照的核心 在插入barrier 的时候,会暂时阻断数据流
barrier 周期性插入到数据流中,并作为数湉流的一部
分随之流动
188 关于fusion Insight HD Streaming 的Supervisor 描述正确的是? 单选题
Supervisor 是在Topology 中接受数据然后执行处
理的组件
Supervisor 负责接受Nimbus 分配的任务,启动和
停止属于自己管理的Worker 进程
Supervisor 负责资源分配和任务调度 supervisor 是运行具体处理逻辑的过程
189
Hadoopz中yarn.scheduler.capacity. root. Queueafinim. m-user-limit-percent设置为 50,下面
说法错误的是?
单选题
一个用户提交任务,可以使用Queue 的 100%的资源
。
如果Queue 中已经有 2 个用户的任务运行,这时第
3 个用户提交的任务需要等待释放资源。
Queue 中必须保障毎个用户至少得到 50%的资源 ueuea 中的每个用户最多只能获得 50%的资源
190 Streaming 主要通过zookeeper 提供以下的哪项实现事件侦听? 单选题 分布式锁机制 Watcher Checkpoint
191 Zookeeper 在分布式应用中主要的作用不包括以下哪些选项? 单选题 选举Master 节点 保证各节点上数据的 分配集群资源 存储及群中
192 HDFS 中Name node 的主备仲裁,是由哪个组件控制的( ) 单选题 HDFS Client Nodemanager Resourcemanager Zookeeper Failover Controller
193 安装fusioninsight HD 的Streaming 组件是, Nimbus 角色要求安装几个节点? 单选题 4 3 2 1
194 Fusioninsight HD 系统审计日志不可以记录下面哪些操作? 单选题 手动清除告警 启停服务实例 查询历史监控 除服务实例
195 Flink 的数据转换操作在以下哪些环节中完成( )? 单选题 channel Transformation sink source
196 Fusioninsight Manager 用户权限管理不支持哪个配置? 单选题 给用户配置角色 给用户组配置角色 给角色配置权限 给用户组配置权限
197 以下哪个不属于Hadoop 中Mapreduce 组件的特点? 单选题 高容错 良好的扩展性 实时计算 易于编程
198 Hbase 的某张表的Rowkey 划分splitkey 为 9.E.a.2.请问表里面有几个Region? 单选题 6 3 5 4
199 为了保障流应用的快照存储的可靠性,快照主要存储在哪里? 单选题 jobmanager 的内存中 可靠性高的单机数据库中 本地文件系统中 hdfs 中
200 在fusionlnsigh 产品中,关于kafka 的 topic.以下描述不正确的是? 单选题 topic 的partition 数量可以创建时配置 每个topic 只能被分成一个partition 区
每条发布到kafka 的消息都有一个类别,这个类别被
称为topic.也可以理解为一个存储消息的队列
每个partition 在存储层面对应一个 1og 文件,10g
文件中记录了所有的消息数据
201 Kafka 集群在运行期间,直接依赖于下面哪些组件? 单选题 spark zookeeper hdfs hbase
剩余18页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-09-27 上传
2022-10-13 上传
2021-07-07 上传
2024-04-12 上传
2022-10-22 上传
2021-07-05 上传

weixin_44472788
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- serial_s3c.rar_Linux/Unix编程_Unix_Linux_
- CsharpStrukturyGeneryczne
- MakeANewFri:
- rdn-upload:Zend Framework 3模块可轻松安全地管理文件上传
- 多域:该插件可让您在一个WordPress安装中拥有多个域
- vscoq:Coq的Visual Studio代码扩展[maintainers = @ maximedenes,@ fakusb]
- data-structure
- IIRfilterdesign.rar_matlab例程_LabView_
- ctfcode:收集一些对CTF事件有用的资料
- 将数据粘贴到WPF DataGrid中的替代实现
- cachify:针对WordPress的智能但高效的缓存解决方案。 使用DB,HDD,APC或Memcached存储您的博客页面。 使WordPress更快!
- PyPI 官网下载 | telnet2-1.1.2.tar.gz
- mips_to_c:MIPS反编译器
- rds-tools:用于RDS的CDK构造
- Arduino:Arduino的代码,包括接口
- matlab-a-c.rar_matlab例程_matlab_
