深度学习计算机视觉:五大核心技术详解与应用
版权申诉
深度学习在计算机视觉领域扮演着核心角色,其主要技术包括图像分类、对象检测、目标跟踪、语义分割和实例分割。本文将逐一探讨这些关键概念。
首先,计算机视觉是指通过分析和理解数字图像,为图像中的客观对象构建有意义的描述,实现对三维世界特性的计算,以及基于感知信息做出有用决策的技术。例如,人脸识别技术在Snapchat和Facebook中用于用户身份验证,图像检索则依赖于Google Images的图像内容分析,而立体视觉技术如微软Kinect在游戏和控制应用中发挥重要作用。
针对计算机视觉的五大技术:
1. **图像分类**:这是基础任务,涉及对一组已知类别标签的图像进行预测,应用于新图像的类别识别。挑战包括处理视点变化、尺度变化、类内差异、图像变形、遮挡、光照和背景噪声。通过数据驱动的方法,如使用卷积神经网络(CNN),训练集包含N张图像和K个类别,通过学习每个类别的特征,最终对新图像进行分类并评估准确性。
2. **对象检测**:这项技术不仅要识别图像中的物体,还要确定其位置,对于自动驾驶、安防监控等领域至关重要。它克服了图像分类的局限性,能在图像中找到并定位特定对象。
3. **目标跟踪**:跟踪一个或多个目标在视频序列中的运动,是实时视觉系统的关键组成部分。目标跟踪需要处理运动模糊、遮挡和环境变化等问题,常见的方法有卡尔曼滤波和深度学习模型。
4. **语义分割**:区分图像中的像素属于哪个类别,每个像素都有其对应的类别标签,有助于理解和解析复杂场景。在医疗图像分析、地图制作等应用中,语义分割非常重要。
5. **实例分割**:在此基础上更进一步,不仅识别出像素所属的类别,还区分出同类中不同的实例。这对于识别多辆相似汽车或不同个体的人脸非常关键。
卷积神经网络(CNN)作为当前主流的图像分类架构,通过卷积层、池化层和全连接层等结构,有效地提取图像特征,使得计算机能够对图像进行更精细的分析和识别。
总结来说,深度学习在计算机视觉中的五大技术互相支持,共同推动了人工智能在诸多领域的应用进步,从日常娱乐到工业生产,它们都在发挥着不可或缺的作用。随着技术的不断发展,我们可以期待计算机视觉在未来的更多可能性。
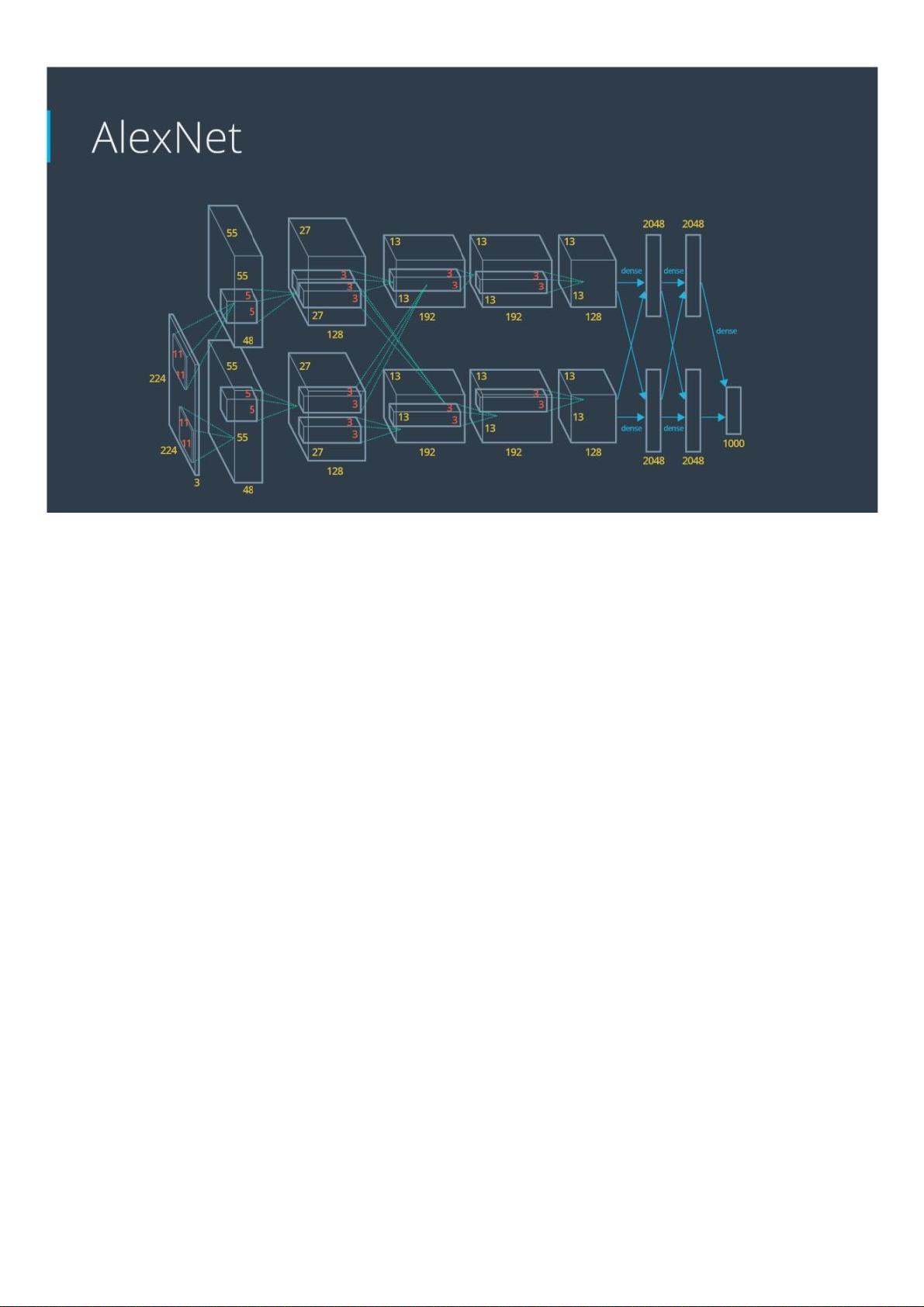
就硬件要求⽽⾔, Alex 在 2 个 Nvidia GTX 580 GPU (速度超过 1000 个快速的⼩内核)上实现了⾮常⾼效的卷积⽹络。 GPU ⾮常适
合矩阵间的乘法且有⾮常⾼的内存带宽。这使他能在⼀周内完成训练,并在测试时快速的从 10 个块中组合出结果。如果我们能够以⾜够快
的速度传输状态,就可以将⽹络分布在多个内核上。
随着内核越来越便宜,数据集越来越⼤,⼤型神经⽹络的速度要⽐⽼式计算机视觉系统更快。在这之后,已经有很多种使⽤卷积神经⽹络作
为核⼼,并取得优秀成果的模型,如 ZFNet(2013),GoogLeNet(2014), VGGNet(2014),
RESNET(2015),DenseNet(2016)等。
对象检测
在对象检测中,你只有 2 个对象分类类别,即对象边界框和⾮对象边界框。例如,在汽车检测中,你必须使⽤边界框检测所给定图像中的
所有汽车。
这不同于分类/定位任务——对很多对象进⾏分类和定位。
剩余12页未读,继续阅读
5195 浏览量
850 浏览量
3669 浏览量
2024-02-19 上传
2021-08-18 上传
2024-02-14 上传
349 浏览量
2024-07-27 上传
108 浏览量

_webkit
- 粉丝: 31
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握PerfView:高效配置.NET程序性能数据
- SQL2000与Delphi结合的超市管理系统设计
- 冲压模具设计的高效拉伸计算器软件介绍
- jQuery文字图片滚动插件:单行多行及按钮控制
- 最新C++参考手册:包含C++11标准新增内容
- 实现Android嵌套倒计时及活动启动教程
- TMS320F2837xD DSP技术手册详解
- 嵌入式系统实验入门:掌握VxWorks及通信程序设计
- Magento支付宝接口使用教程
- GOIT MARKUP HW-06 项目文件综述
- 全面掌握JBossESB组件与配置教程
- 古风水墨风艾灸养生响应式网站模板
- 讯飞SDK中的音频增益调整方法与实践
- 银联加密解密工具集 - Des算法与Bitmap查看器
- 全面解读OA系统源码中的权限管理与人员管理技术
- PHP HTTP扩展1.7.0版本发布,支持PHP5.3环境
