




利用长短期记忆与深度神经网络提升电力元件识别效率
81 浏览量
更新于2024-08-25
收藏 2.04MB PDF 举报
本文主要探讨了在电力巡检图像处理中的一个关键挑战:如何提高电力组件识别的准确性,尤其是在存在大量干扰物体的复杂场景下。作者针对这一问题提出了一种创新的方法,结合了长短期记忆(Long Short-Term Memory, LSTM)网络和深度神经网络(Deep Neural Network, DNN)技术。
首先,作者利用LSTM网络的优势在于其能够捕捉和理解长期依赖性,这对于处理图像中的上下文信息至关重要。在传统的卷积神经网络(Convolutional Neural Network, CNN)基础上,LSTM被用于合成和整合图像的全局和局部特征,增强模型对电力组件识别的鲁棒性。这与传统的识别方法有所不同,后者可能无法充分挖掘图像的全面信息。
接下来,作者构建了一个名为Mask LSTM-CNN的模型,该模型融合了现有的Mask R-CNN方法,即一种流行的区域卷积神经网络,专门用于目标检测。通过Mask LSTM-CNN,模型可以更好地定位和区分电力组件,同时利用LSTM处理动态序列数据的能力来增强对象识别的精度。
然后,为了进一步优化模型性能,作者设计了一种特定的特征提取算法,该算法专注于提取电力组件特有的视觉特征。这种方法有助于降低噪音干扰,提高模型对于目标组件的识别能力。此外,作者还针对Mask LSTM-CNN模型的参数进行优化,以确保在训练过程中达到最佳性能。
最后,研究结果表明,这种结合了长短期记忆和深度学习的电力组件识别方法在实际应用中表现出强大的竞争力,不仅提高了识别准确率,而且在面对复杂环境时展现出更好的鲁棒性。这一研究成果对于提升电力设备维护和故障诊断的效率具有重要的理论和实践价值。这篇研究论文在图像处理领域为电力组件的智能识别提供了一种新的、高效的解决方案。
Lei et al. EURASIP Journal on Image and Video Processing
(2018) 2018:122
Page 3 of 14
Fig. 2 The structure of R-FCN
lower efficiency. This process significantly improves the
detection speed of the entire model. However, it can only
determine the target’s general location instead of the spe-
cific power component’s position. Overall, this model has
a low recognition rate when the power components are
occluded. Thus, it cannot meet the on-site requirements
for power component identification.
2.2 Power station identification based on R-FCN method
The target detection of the regional-based full convolu-
tional network [22] is divided into two steps: position-
ing a target and then classifying the target to a specific
category. First, R-FCN model uses a rudimentary con-
volutional network to generate a feature map. Then, the
regional feature map is used to generate the feature map
before and after the full map is constructed. The model
determines the target’s outline by searching and filtering
[23] scene images through these feature maps. Finally, the
classification framework recognizes the target.
Figure 2 demonstrates the structure of R-FCN model.
The target image is passed through a basic convolutional
network to generate feature maps and input these feature
maps into a full-volume network to generate a score bank
of position-sensitive score maps. The results of the basic
convolutional network go through the RPN network to
generate RoI. For a RoI of size w × h (obtained by the RPN
network), the target frame is divided into k × k subar-
eas, each subarea is of size w × h/k2. For anyone subarea
bin
i, j
, j ≤ k − 1, define a location-sensitive pooling
operation:
r
c
(i, j|∇) =
(x,y)∈bin(i,j)
1
n
z
i,j,c
(x + x
0
, y + y
0
|∇) (1)
where r
c
(i, j|∇) isthepooledresponseofsubareabin(i, j)
to c categories and z
i,j,c
stands for a location-sensitive
score map corresponding to subarea bin(i, j). x
0
+ y
0
represents the coordinates of the upper left corner of
the target candidate box, n isthenumberofpixelsin
subarea bin(i, j),and∇ represents all the learned param-
eters of the network. The model calculates the average
of pooled response output r
c
(i, j|∇) for k × k sub-
regions and uses the softmax regression classification
method to obtain the probability that it belongs to each
category.
R-FCN integrates the target’s position information into
ROI pooling by position-sensitive score map, which solves
the problem that the ROI pooling of Faster-RCNN net-
work has no translation invariance. Thus, this model
improves the accuracy of target detection and classifi-
cation so that the operating efficiency of the model is
significantly superior. However, it is evident that the R-
FCN model still cannot detect the specific location of
the target and lacks the robustness to the scene of power
components with many interfering objects.
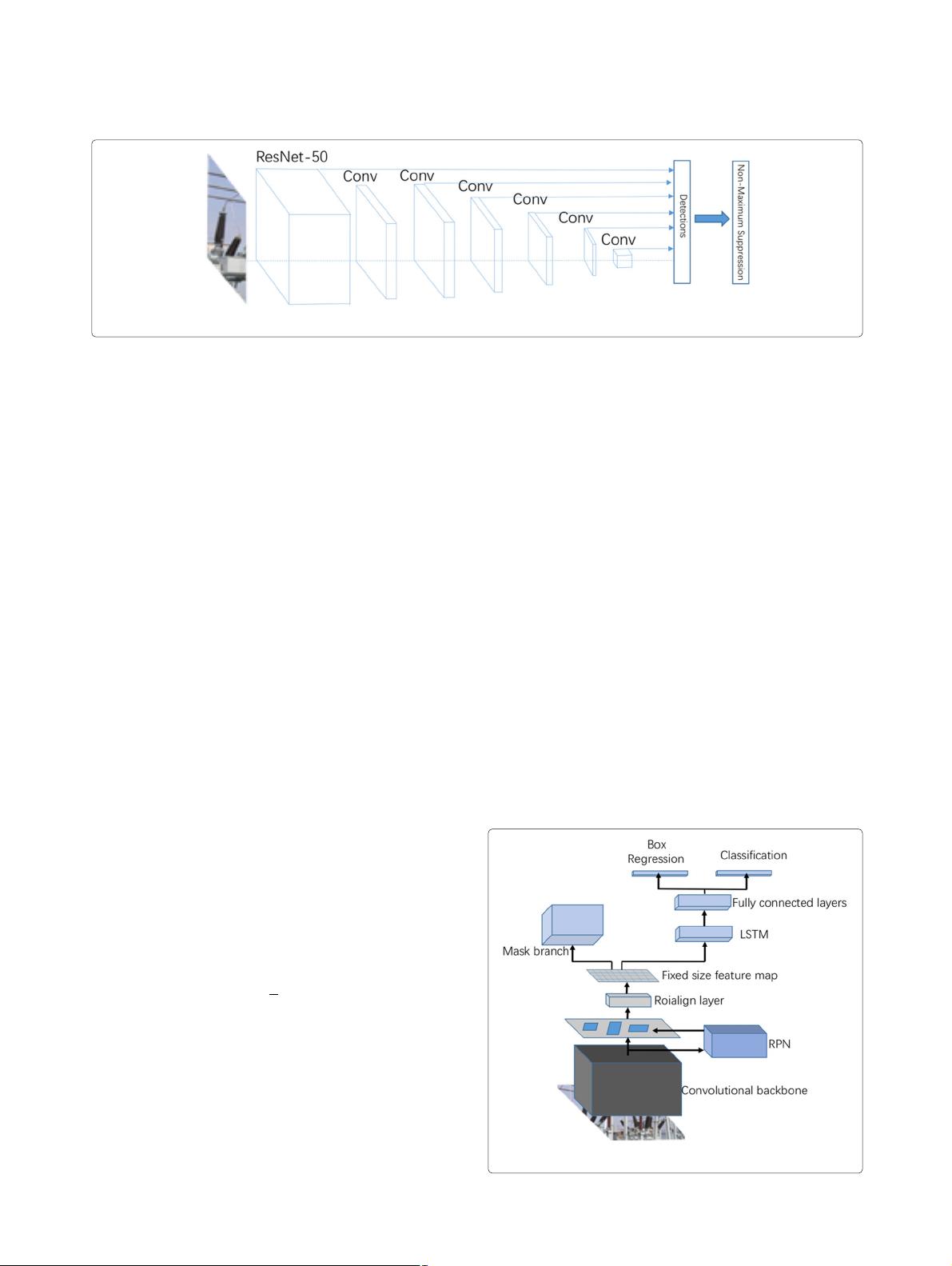
3 Recognition of power components based on
Mask LSTM-CNN
Although the Faster-RCNN and R-FCN methods improve
the processing speed and accuracy of part identification
models, they cannot refine the specific contours of power
components so that live working robots cannot accurately
identify components’ orientations through such methods.
Fig. 3 The structure of Mask LSTM-CNN
下载后可阅读完整内容,剩余13页未读,立即下载
107 浏览量
2025-01-12 上传
532 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38703277
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开








最新资源
- C#网络编程全面教程:概念、实例与进阶
- Struts标签库使用手册:全面解读与应用指导
- JSP许愿树与许愿墙源码分享
- CADlsp编程资源包:高效设计必备工具集
- SONY GC85边缘网络驱动下载
- AutoLyric5.6.0:foobar最佳歌词插件,透明效果,支持自定义
- 网易新闻客户端仿项目源码解析及功能介绍
- C++无线通信系统仿真源代码详解
- JBuild2005开发的C/S固定资产管理项目接近完美
- 服务器端完美实现在线压缩解压功能
- 国防工业出版社第六版通信原理课件下载
- CodData: 构建使命召唤业余项目的数据理论工具
- 安卓记事本应用源码发布:简约温馨UI设计
- 272个超酷经典JavaScript代码精选
- Infragistics NetAdvantage for ASP.NET 2008 Vol 2源码深度解析
- 新版ERP进销存系统V8多仓库版发布与图片上传错误修复






















