利用因果推理构建稳健、可靠和负责任的自然语言处理
需积分: 5 104 浏览量
更新于2024-06-19
收藏 45.02MB PPTX 举报
"这篇资源主要讨论了因果推理在构建稳健、可靠且负责任的自然语言处理(NLP)系统中的重要性。随着大型语言模型(LLMs)如ChatGPT和GPT-4等的出现,它们正在渗透到医疗、教育等多个领域,并展现出了在一般性问题解答等任务上的出色能力。然而,这些模型也存在盲目跟从模板、过度依赖训练数据的问题,导致其在应用中可能缺乏鲁棒性和可靠性,成为潜在的风险。文章强调了理解模型的因果关系对于提高其性能和责任性的必要性,并对比了LLMs与人类解决问题的不同方式。"
在当前的自然语言处理领域,因果推理已经成为一个关键的研究方向,旨在增强模型的稳健性和可靠性。随着大规模语言模型的崛起,如GPT系列,它们在市场预测中占据重要地位,并广泛应用于各个行业,包括但不限于医疗保健和教育。这些模型展示出在通用问答等任务上的惊人能力,能进行复杂的对话和信息检索。
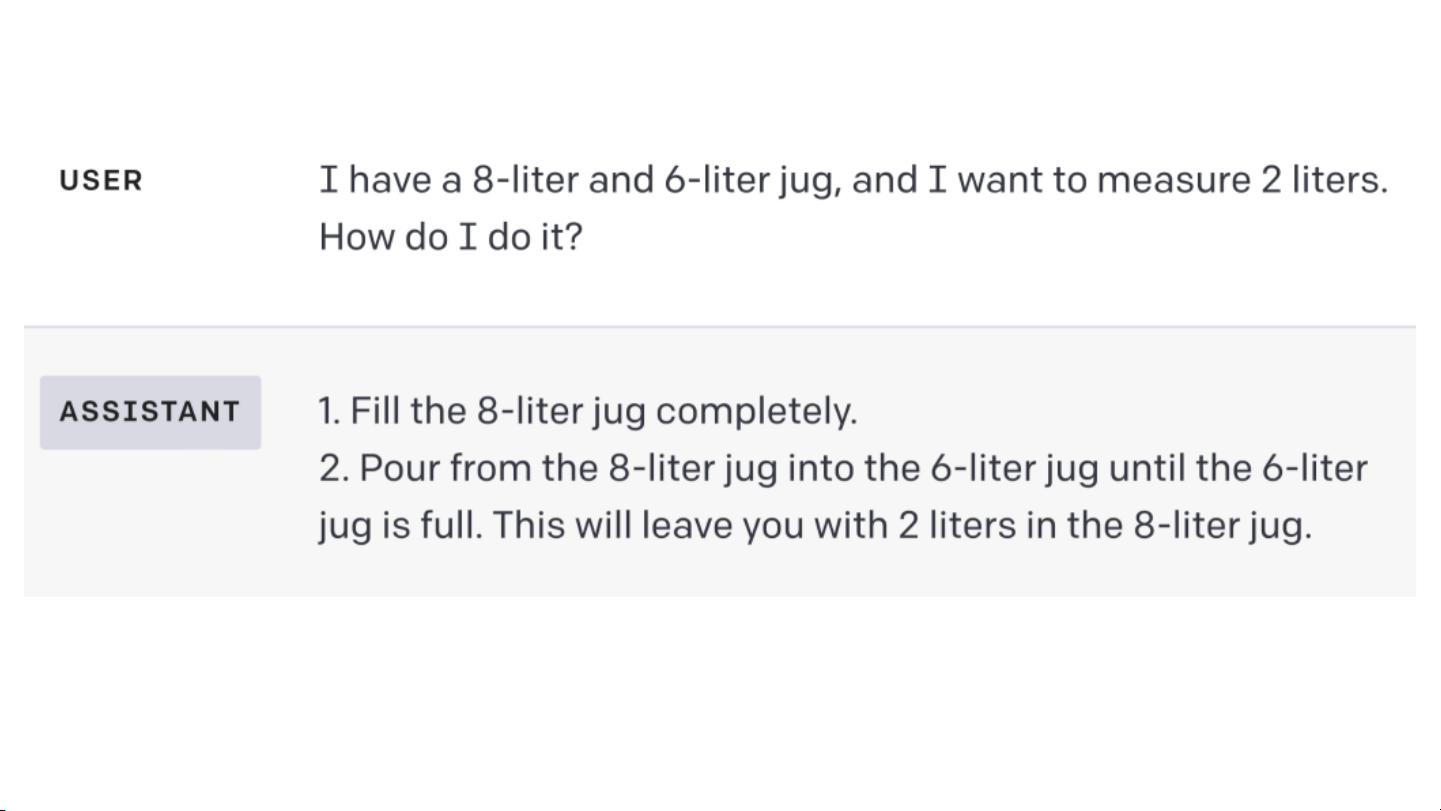
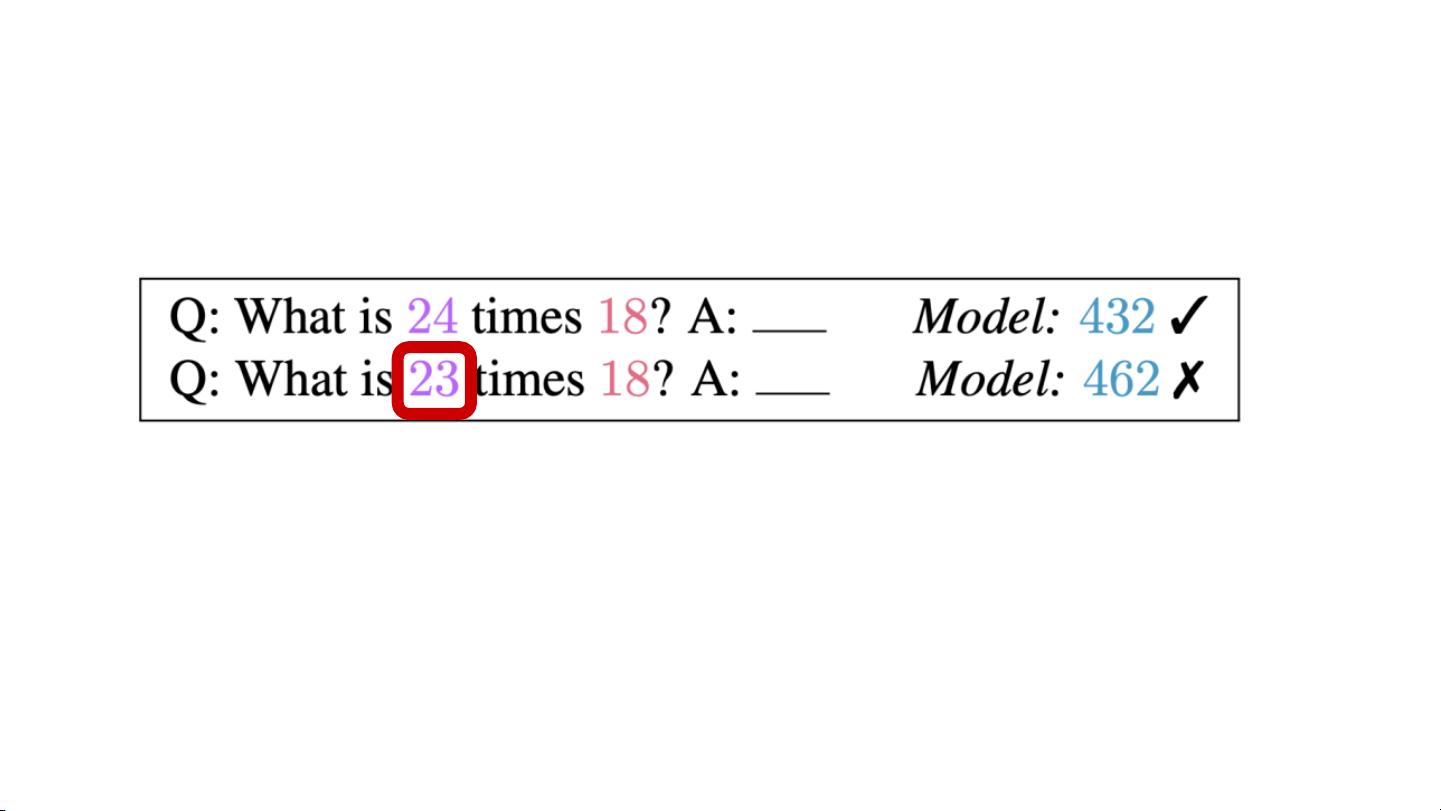
然而,这些模型并非无懈可击。研究表明,LLMs很大程度上依赖于训练数据中的模式,这可能导致它们盲目地遵循已知的模板,而不是真正理解问题并进行创新性回答。这种现象在某些情况下可能会引发错误或误导性的输出,从而对用户造成影响。因此,缺乏鲁棒性和可靠性被认为是LLM应用中的一个“定时炸弹”。
为了建立更负责任的NLP系统,理解因果关系至关重要。因果推理允许我们探究模型如何基于输入信息做出决策,以及这些决策是否真实反映了现实世界的因果关系。通过因果建模,可以更好地评估模型的局限性,避免简单地复制训练数据中的模式,从而提高模型的泛化能力和适应性。
对比人类,LLMs在解决问题时通常缺乏深度理解和情境意识。人类能够结合背景知识和经验来推理,而LLMs往往只能基于其训练数据中的关联性进行响应。通过引入因果推理,NLP研究者可以指导模型学习更深层次的逻辑,减少对表面模式的依赖,以提高其在现实世界环境中的表现。
这篇资源突显了在NLP发展中引入因果推理的紧迫性,以确保模型不仅在技术上先进,而且能够在实际应用中表现出稳健性、可靠性和道德责任感。这需要研究人员不断探索新的方法,以使模型更加理解世界,减少依赖训练数据中的偏差,从而为用户提供更为准确和安全的服务。

2021-05-18 上传
134 浏览量
2023-12-24 上传
2022-01-04 上传
2023-08-21 上传
2019-04-01 上传
2021-01-07 上传
2023-09-30 上传

softshow1026
- 粉丝: 1095
- 资源: 254
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
