深入解析Apache Spark编程:分布式数据集与pySpark实战
需积分: 10 102 浏览量
更新于2024-07-19
收藏 597KB PDF 举报
"Apache Spark是大数据处理领域的重要工具,它提供了高效的分布式数据处理能力。本资源主要涵盖了Apache Spark编程的基础知识,包括Resilient Distributed Datasets (RDDs)的概念、Spark编程模型、以及如何使用Python接口(pySpark)进行Spark编程。通过讲解,将帮助读者理解Spark的工作原理和应用方式,特别强调了Spark程序的驱动程序和工作程序结构,以及SparkContext在集群环境中的作用。"
Apache Spark 是一个开源的并行计算框架,专为大规模数据处理而设计。它支持批处理、交互式查询(例如,通过Spark SQL)、实时流处理和机器学习等多种计算任务。Spark的核心概念是Resilient Distributed Datasets (RDDs),这是一个不可变、分区的数据集,可以在集群中的多个节点上分布式存储和处理。
创建RDD:RDD是Spark的基本操作单元,可以通过从现有数据源(如HDFS、HBase等)加载数据或通过Spark API创建。RDD具有两个关键特性:一是分区,即数据被分割成多个部分;二是弹性,即在节点故障时可以自动恢复。
Spark Transformations和Actions:Transformations是对RDD进行操作但不立即执行的函数,如map、filter、reduceByKey等。它们返回一个新的RDD,而真正计算会在action触发时进行,如count、saveAsTextFile等。
Spark Programming Model:Spark模型采用数据并行和任务并行的策略,允许用户通过简单的API定义计算任务,然后由Spark自动调度执行。PySpark为Python开发者提供了一种简洁的接口,使得Spark的使用更为便捷。
Spark Driver and Workers:Spark程序分为两部分——驱动程序(driver program)和工作程序(worker programs)。驱动程序负责创建SparkContext,定义任务逻辑,而工作程序在集群节点上运行,执行实际的计算任务。SparkContext是Spark程序的入口点,它连接到集群,并管理所有计算资源。
Spark Executor:Executor是在每个工作节点上运行的进程,负责执行任务并管理内存。它们负责运行应用程序代码,缓存数据,以及执行transformations和actions。
数据存储:Spark可以读取多种存储系统,如Amazon S3、HDFS或其他分布式存储,用于数据输入和输出。
SparkContext的创建:SparkContext是启动Spark程序的关键,它告诉Spark如何连接到集群。在Databricks Cloud和pySpark shell中,sc变量会自动创建,而在iPython或自定义程序中,需要通过构造函数显式创建。
总结来说,Apache Spark编程详解资源旨在深入解析Spark的编程原理,特别是通过pySpark进行的Python编程,以及Spark如何管理和执行分布式任务,对于理解和掌握大数据处理有极大的帮助。
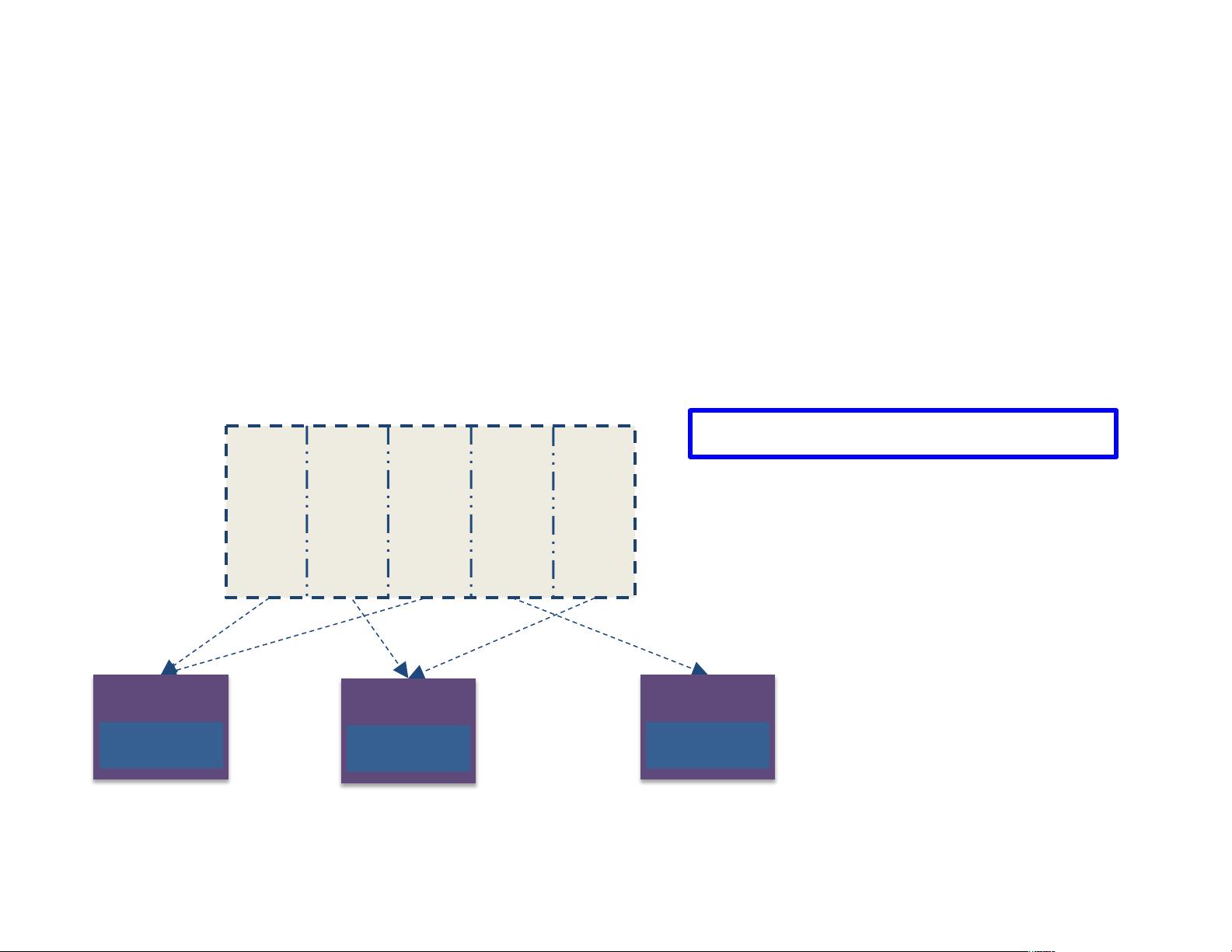
• Programmer specifies number of partitions for an RDD"
item-1"
item-2"
item-3"
item-4"
item-5"
"
item-6"
item-7"
item-8"
item-9"
item-10"
"
item-11"
item-12"
item-13"
item-14"
item-15"
"
item-16"
item-17"
item-18"
item-19"
item-20"
"
item-21"
item-22"
item-23"
item-24"
item-25"
"
RDD split into 5 partitions"
more partitions = more parallelism"
RDDs"
Worker"
Spark
executor"
Worker"
Spark
executor"
Worker"
Spark
executor"
(Default value used if unspecified)"

剩余42页未读,继续阅读
2017-08-09 上传
2024-12-29 上传
2024-12-29 上传
2024-12-29 上传
2024-12-29 上传
2024-12-29 上传









