深度学习损失函数解析:BCELoss与交叉熵
版权申诉
24 浏览量
更新于2024-08-11
1
收藏 286KB PDF 举报
"本文深入分析了深度学习中的几种损失函数,包括二分类交叉熵损失BCELoss、BCEWithLogitsLoss以及HingeEmbeddingLoss。重点探讨了BCELoss的原理及其在二分类问题中的应用。"
在深度学习中,损失函数是评估模型预测与真实结果之间差异的关键工具,它直接影响着模型的训练效果和优化过程。本章主要关注的是二分类问题中的损失函数,特别是二分类交叉熵损失BCELoss。
**二分类交叉熵损失BCELoss**
BCELoss主要用于二分类问题,其工作流程是首先通过sigmoid函数对模型的输出进行归一化,然后利用交叉熵来计算损失。Sigmoid函数,或称逻辑函数,具有(0,1)的输出范围,可以将任意实数值映射到这个区间,从而适用于二分类任务。它的数学形式为:
\[ \sigma(x) = \frac{1}{1 + e^{-x}} \]
Sigmoid函数的导数有助于梯度下降法的优化,但其计算量较大,且在输入接近正负无穷时导数接近0,可能导致梯度消失,这在深层网络中可能成为问题。
交叉熵是衡量两个概率分布之间的差异的一种方法,对于二分类问题,其公式为:
\[ BCE = -\sum_{i} y_i \log(p_i) + (1 - y_i) \log(1 - p_i) \]
其中,\( y_i \)是真实类别标签(0或1),\( p_i \)是模型预测的概率。BCELoss的目标是减小模型预测与实际标签之间的差异。
通过Python代码我们可以实现BCELoss的计算,首先对模型输出应用sigmoid函数,然后按照上述公式计算损失。在实践中,通常会使用PyTorch等深度学习框架中的内置函数如`torch.nn.BCELoss()`来实现。
**BCEWithLogitsLoss**
BCEWithLogitsLoss是BCELoss的一个变体,它结合了sigmoid和交叉熵损失,直接处理未经过sigmoid的模型输出。这样做的好处是避免了单独应用sigmoid带来的数值稳定性问题,并且在计算中减少了一步,可以更有效地防止梯度消失。
**HingeEmbeddingLoss**
HingeEmbeddingLoss常用于支持向量机(SVM)等最大间隔分类模型,它衡量的是预测得分与阈值之间的差距是否超过某一 margin。对于二分类问题,如果模型正确分类,损失将是0;否则,损失将是目标类别分数与非目标类别分数之差减去margin。
总结来说,选择合适的损失函数对深度学习模型的性能至关重要。BCELoss和BCEWithLogitsLoss在二分类问题中广泛应用,而HingeEmbeddingLoss则更适合于最大化边距的分类任务。理解这些损失函数的原理和特点,有助于我们更好地设计和优化深度学习模型。
深度学习损失函数原理分析(三)
上⼀章主要介绍了L1_loss、L2_loss、SmoothL1三个函数,本章主要介绍⼆进制交叉熵损失 BCELoss、BCEWithLogitsLoss、
HingeEmbeddingLoss三个损失函数
2.7 ⼆分类交叉熵损失BCELoss
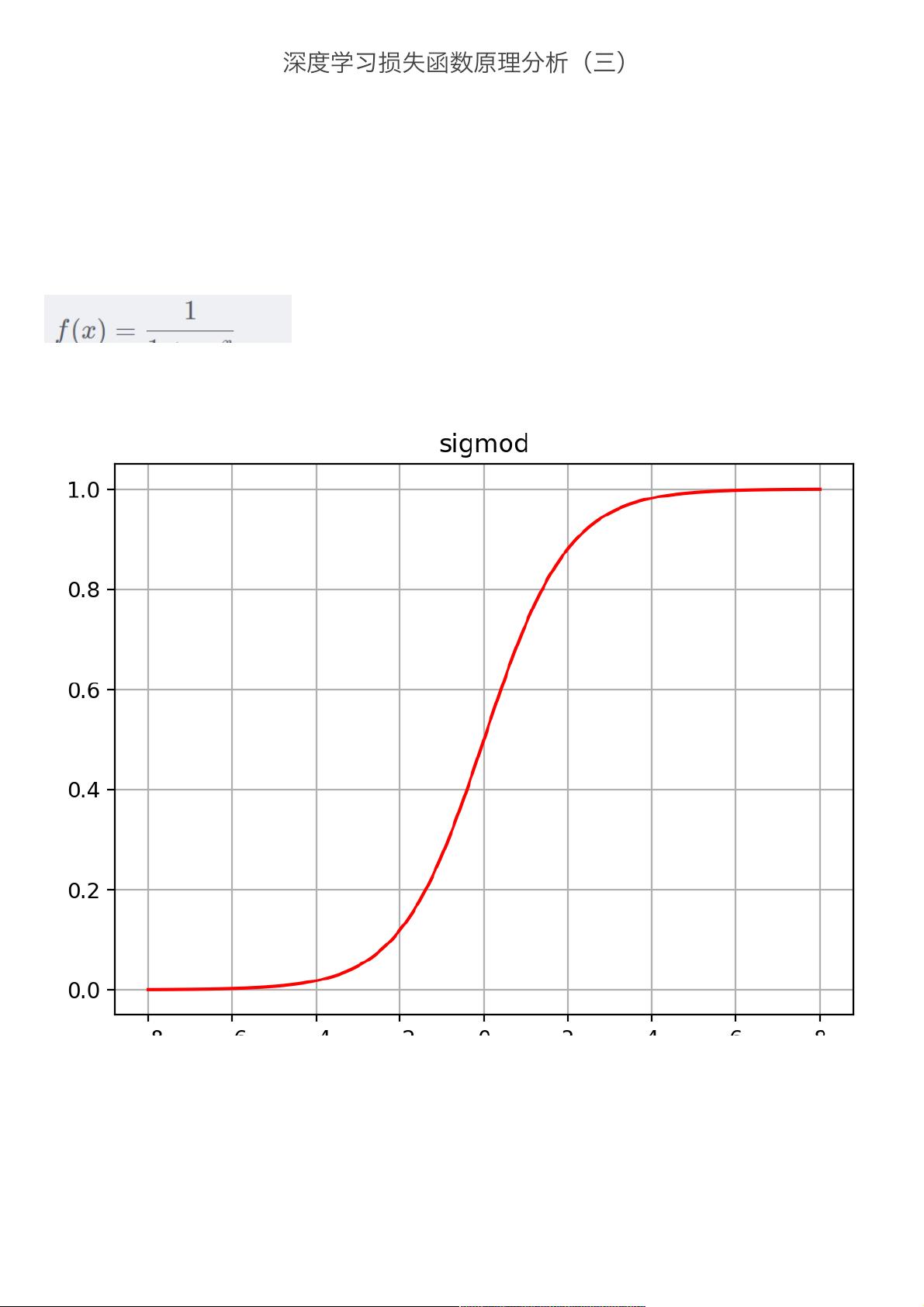
BCELoss主要⽤于⼆分类的损失函数,先对参数进⾏sigmod函数归⼀化,在采⽤交叉熵求损失,过程Sigmoid-BCELoss。
sigmod函数:
sigmod函数也叫Logistic函数,⽤于隐层神经单元输出,取值范围(0,1),他可将⼀个实数映射到(0,1)的区间,⽤作⼆分类。在特征
相差⽐较复杂或者相差不是特别⼤的时候效果⽐较好。
定义:
图形:
下载后可阅读完整内容,剩余5页未读,立即下载
2021-01-06 上传
2022-04-13 上传
2022-04-13 上传
2022-04-13 上传
2022-04-13 上传
2024-07-21 上传
2022-04-13 上传

_webkit
- 粉丝: 31
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全新PHP网址缩短防封短网址生成系统
- Almayce Video Handler-开源
- NotaFiscalNet:.NET电子发票生成
- 武汉医保读卡DLL动态库.rar
- Ziplyne Player prod-crx插件
- RestWithSpringBootMath
- ZoomTest.rar_FlashMX/Flex源码_FlashMX_
- Weinview触摸屏-OMRON_CJ1CS1PLC连接说明书
- quantcs-impl:量化类约束的实现
- Luiz_Henrique_Souza_JAMStackAlura
- paixu.rar_汇编语言_Asm_
- Learn-wp-cli:命令行,WP-CLI和自定义WP-CLI命令入门
- Ledavio Image Importer-crx插件
- The-ABM-in-Archaeology-Bibliography:有关考古中基于代理的模型(ABM)的文献的完整列表。 由Iza Romanowska和Lennart Linde维护和创建
- HubCollections.3okat1n89t.gaJP44e
- flexx:用纯Python编写桌面和Web应用程序
