大数据入门:VirtualBox安装Ubuntu与单节点Hadoop教程
需积分: 14 124 浏览量
更新于2024-07-15
1
收藏 5.7MB DOCX 举报
"本教程详细介绍了如何在VirtualBox上安装Ubuntu并配置Hadoop单机环境,适用于初学者,旨在帮助学习者逐步理解大数据框架结构和底层组件原理。"
在大数据领域,动手实践是学习的关键步骤之一,而本教程正是为此目的设计的。它涵盖了从安装虚拟机到配置Hadoop单机环境的全过程。首先,我们需要下载必要的软件:VirtualBox作为虚拟机软件,以及Ubuntu操作系统的镜像文件。VirtualBox可以从其官方网站下载,安装过程简单,只需按照提示进行。Ubuntu镜像文件可以在Ubuntu官网下载,选择适合的版本,推荐下载14.04版本。
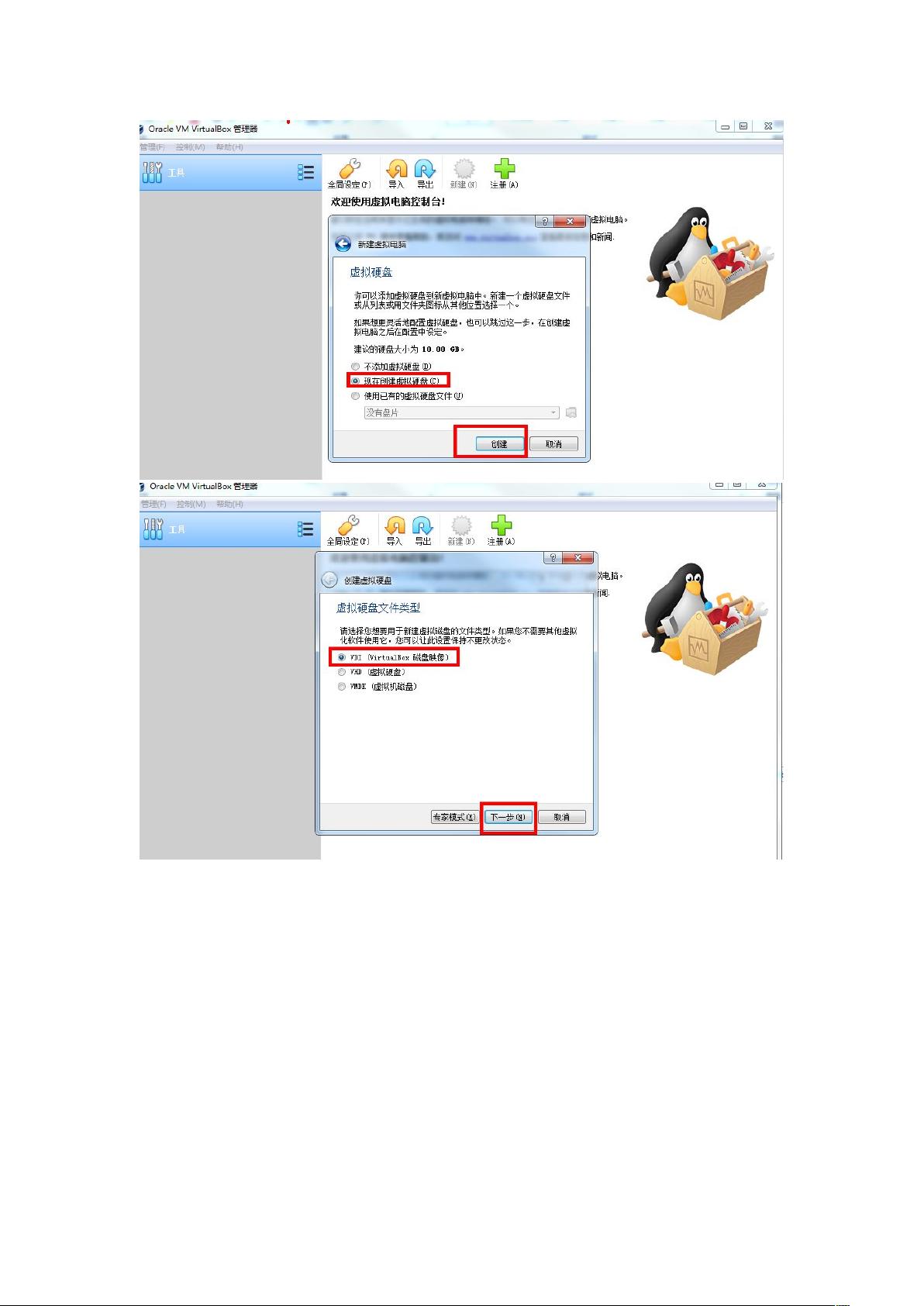
接下来是虚拟机的创建与设置。在VirtualBox中新建虚拟机,并指定Ubuntu的ISO文件作为安装源。安装过程中需按照屏幕指示进行,直到系统安装完毕并首次启动。安装完成后,为提升用户体验,可以安装VirtualBox的增强功能,这将允许在Windows和Linux之间无缝复制和粘贴内容。
然后,我们进入Hadoop的安装阶段。Hadoop是大数据处理的核心组件,这里我们建立一个单机集群。首先确保安装了JDK,可以通过`sudo apt-get install default-jdk`命令来安装,并验证安装成功。接着,安装SSH和rsync以实现无密码登录,通过生成SSH密钥并将其添加到authorized_keys文件中。这样,我们可以无需每次输入密码就能远程登录。
最后,下载并安装Hadoop。Hadoop的二进制包通常从Apache的FTP服务器获取,然后解压缩并移动到/usr/local目录下,以便系统全局访问。至此,Hadoop的基础环境已搭建完成。
这个教程不仅提供了详细的操作步骤,而且对于每个环节都做了简要的解释,适合大数据初学者跟随操作,逐步熟悉大数据环境的搭建。通过这样的实践,学习者可以更好地理解大数据框架的运作机制,为后续深入学习Hadoop及其生态系统打下坚实基础。
剩余29页未读,继续阅读
2017-11-01 上传
2013-06-07 上传
2024-04-29 上传
2019-03-05 上传
2024-04-12 上传
点击了解资源详情
2023-03-16 上传

sun_com1984
- 粉丝: 15
- 资源: 17
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
