淘宝海量数据产品技术架构解析
需积分: 0 58 浏览量
更新于2024-09-12
收藏 1.51MB DOC 举报
"淘宝技术架构主要探讨了其在海量数据处理和数据产品开发中的技术解决方案,包括数据源、计算层、存储层、查询层和产品层的架构设计。"
淘宝作为一个大型电商平台,其数据量巨大,每日有数十亿的店铺浏览记录、十亿级别的在线商品数量以及海量的交易、收藏和评价数据。为了从这些数据中提取商业价值,淘宝数据平台与产品部开发了一系列数据产品,如量子统计、数据魔方和淘宝指数。这些产品虽然在业务层面看似简单,但在处理海量数据时,计算、存储和检索的挑战显著增加。
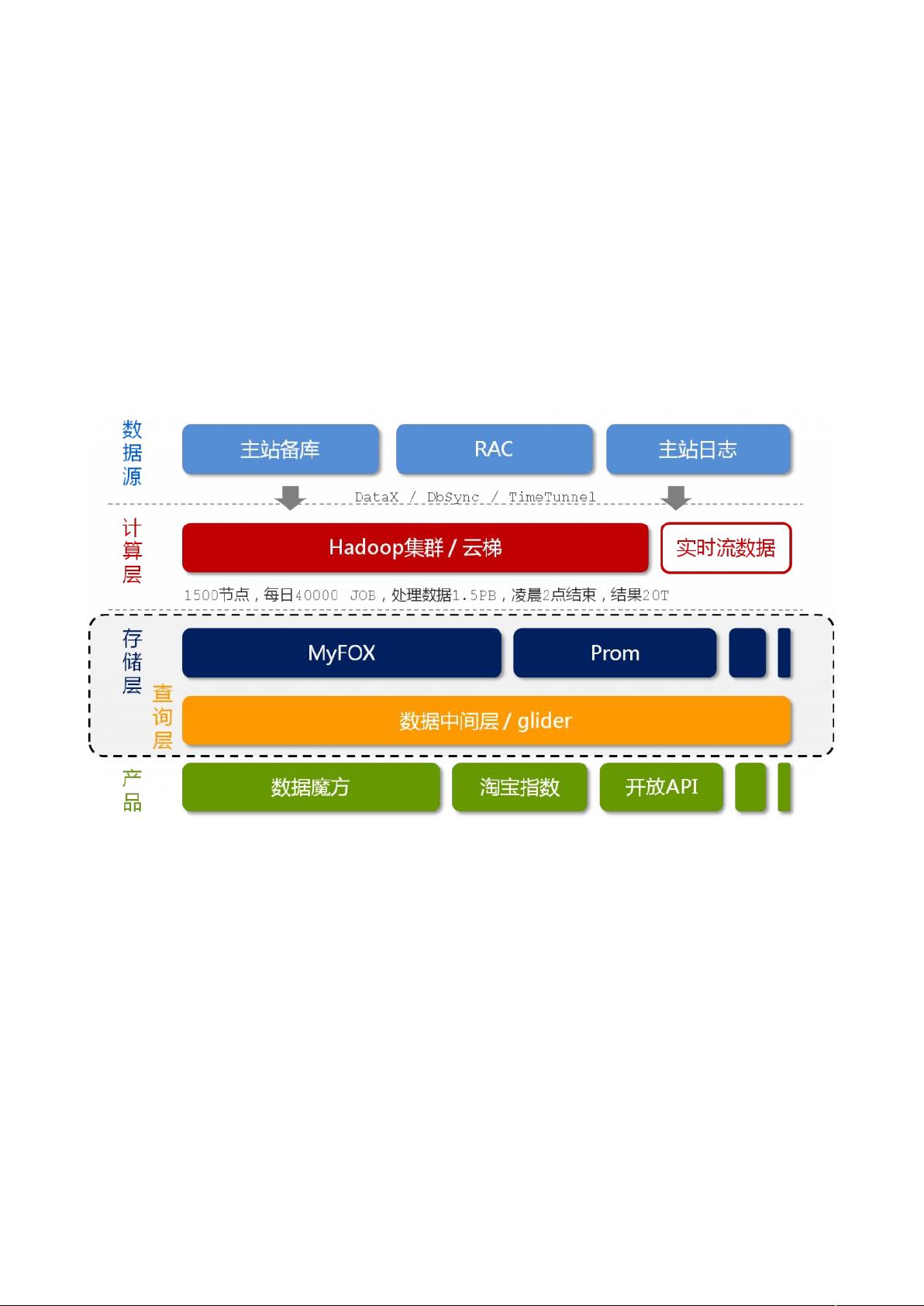
首先,淘宝数据产品技术架构的核心特点是数据的非实时写入,使得系统在一段时间内可以视为只读,便于利用缓存策略。整个架构分为五个层次:
1. 数据源层:包含淘宝主站的用户、店铺、商品和交易数据库,以及用户行为日志等。这些数据通过DataX、DbSync和TimeTunnel等工具实时传输至Hadoop集群“云梯”。
2. 计算层:“云梯”是一个由1500个节点组成的Hadoop集群,每天执行大约40000个MapReduce作业,处理约1.5PB的原始数据,通常在凌晨两点前完成计算。
3. 存储层:计算结果可能是一个中间状态,用于平衡数据冗余与前端计算的需要。部分数据需要更高的实效性,这就引入了实时计算平台——“银河”。
4. 查询层:“银河”是一个分布式系统,接收实时消息并在内存中进行计算,快速将结果更新到NoSQL存储,以满足前端产品的需求。
5. 产品层:最后,这些经过处理和计算的数据会被整合进各种数据产品,供淘宝、商家和消费者使用,帮助他们进行数据分析和决策。
淘宝的技术架构充分考虑了数据处理的效率和实时性,利用分布式计算和存储解决方案来应对大数据挑战。通过“云梯”处理批量数据,结合“银河”实现流式数据的实时分析,确保了数据产品的多样性和及时性。这种架构设计为其他大规模数据处理提供了借鉴,展示了如何有效管理和利用海量数据以驱动业务增长。
淘宝数据魔方技术架构解析
淘宝网拥有国内最具商业价值的海量数据。截至当前,每天有超过 30 亿的店铺、商品浏览记录,10
亿在线商品数,上千万的成交、收藏和评价数据。如何从这些数据中挖掘出真正的商业价值,进而帮助
淘宝、商家进行企业的数据化运营,帮助消费者进行理性的购物决策,是淘宝数据平台与产品部的使命。
为此,我们进行了一系列数据产品的研发,比如为大家所熟知的量子统计、数据魔方和淘宝指数等 。
尽管从业务层面来讲,数据产品的研发难度并不高;但在“海量”的限定下,数据产品的计算、存储和检索
难度陡然上升。本文将以数据魔方为例,向大家介绍淘宝在海量数据产品技术架构方面的探索。
淘宝海量数据产品技术架构
数据产品的一个最大特点是数据的非实时写入,正因为如此,我们可以认为,在一定的时间段内,
整个系统的数据是只读的。这为我们设计缓存奠定了非常重要的基础。
图 1 淘宝海量数据产品技术架构
按照数据的流向来划分,我们把淘宝数据产品的技术架构分为五层(如图 1 所示),分别是数据源、
计算层、存储层、查询层和产品层。位于架构顶端的是我们的数据来源层,这里有淘宝主站的用户、店
铺、商品和交易等数据库,还有用户的浏览、搜索等行为日志等。这一系列的数据是数据产品最原始的
生命力所在。
在数据源层实时产生的数据,通过淘宝自主研发的数据传输组件 DataX、DbSync 和 Timetunnel 准实
时地传输到一个有 1500 个节点的 Hadoop 集群上,这个集群我们称之为“云梯”,是计算层的主要组成部分。
在“云梯”上,我们每天有大约 40000 个作业对 1.5PB 的原始数据按照产品需求进行不同的 MapReduce 计算。
这一计算过程通常都能在凌晨两点之前完成。相对于前端产品看到的数据,这里的计算结果很可能是一
个处于中间状态的结果,这往往是在数据冗余与前端计算之间做了适当平衡的结果。
不得不提的是,一些对实效性要求很高的数据,例如针对搜索词的统计数据,我们希望能尽快推送
到数据产品前端。这种需求再采用“云梯”来计算效率将是比较低的,为此我们做了流式数据的实时计算平
台,称之为“银河”。“银河”也是一个分布式系统,它接收来自 TimeTunnel 的实时消息,在内存中做实时计
下载后可阅读完整内容,剩余7页未读,立即下载
385 浏览量
2012-03-08 上传
122 浏览量
2012-06-20 上传
142 浏览量
2013-06-09 上传
160 浏览量

xing2540
- 粉丝: 3
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- 自动抄表系统中几种传感器的应用
- Vxworks入门实验
- Spring框架的简要分析.doc
- Operating System(Chapter 1)
- RDP协议详解(remote desktop protocol)
- Resin_brochure
- eclipse中文文档
- ASP.NET 不仅仅是 Active Server Page (ASP) 的下一个版本;它还提供了一个
- C#和.Net的优点研究了一下C#和.Net,有很多体会,好的不好的都有。随便谈谈,供大家参考。
- 深入理解计算机系统(英文版)
- Practical UML Statecharts in C,C++, Second Edition.pdf
- JSP 实用教程 (第二版) 代码
- 经典c程序编程100例
- 常用DIV+CSS网页制作布局技术技巧
- scilab 软件的帮助说明
- PowerPCB教程.pdf
