MapReduce程序打包与部署指南:从创建JAR到Hadoop运行
需积分: 0 65 浏览量
更新于2024-08-04
收藏 398KB DOCX 举报
在Hadoop环境下进行MapReduce程序的打包与运行是数据处理的重要步骤。本文将详细讲解这一过程。
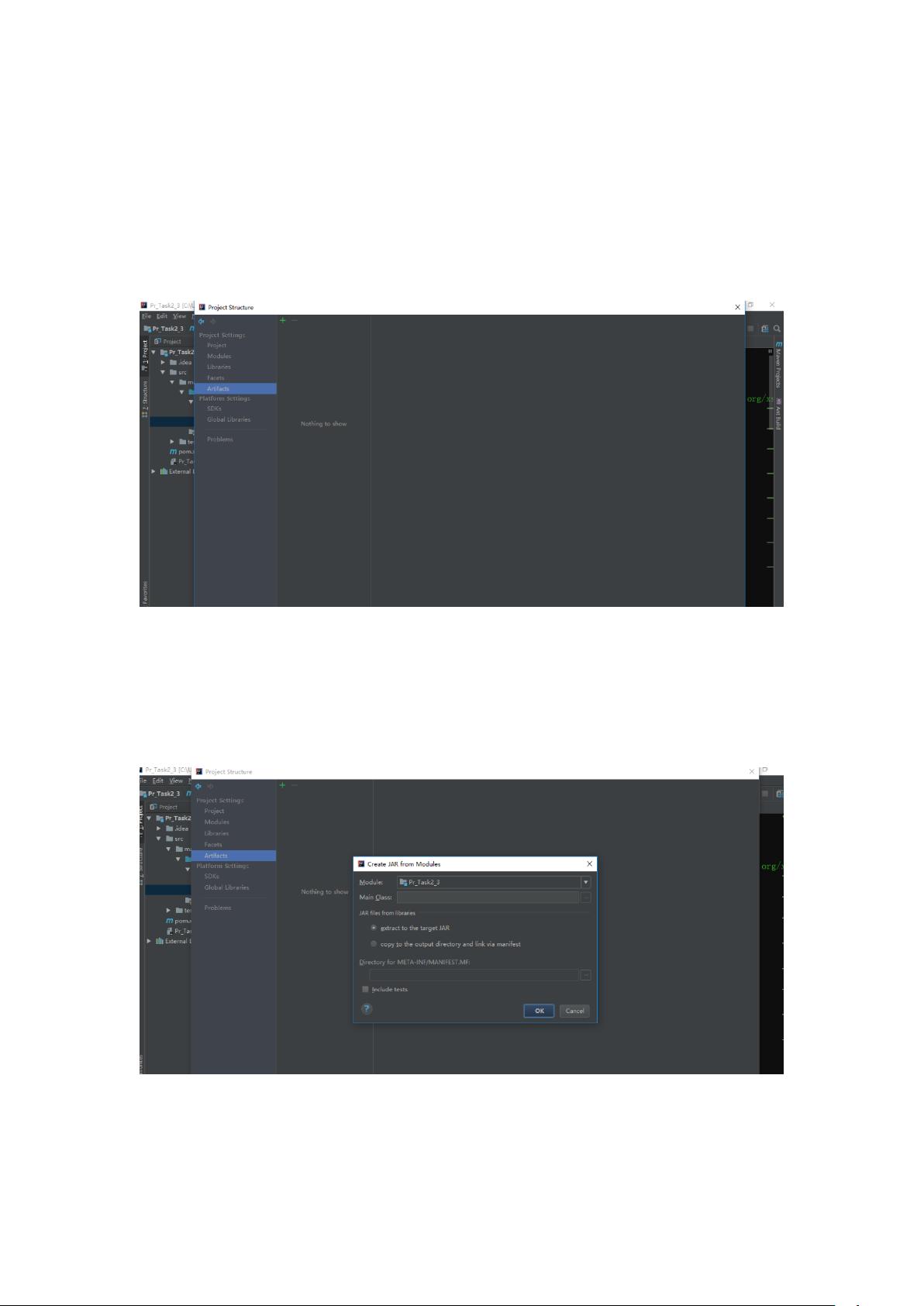
首先,我们从创建MapReduce项目的结构开始。在IDE(如IntelliJ IDEA)的主界面,通过“File”菜单中的“Project Structure”命令打开项目结构管理器。在这个界面中,用户可以通过点击"+"号,选择“JAR”->“From modules with dependencies”来创建一个新的JAR文件。这个选项允许你从当前项目模块中选取所需的依赖项一起打包,确保程序的完整性和正确执行。
接下来,用户需要指定主类。在弹出的“Create JAR from Modules”窗口中,找到并点击“MainClass”后面的选项按钮,然后在新窗口中选择要作为主入口的驱动类,例如这里的“test”包下的“Drive”类。确认选中后,点击“OK”返回到Project Structure界面,可以看到已创建的jar包,比如名为“Pr_Task2_3.jar”。
打包完成后,通常会在项目的“out”目录下生成一个包含所需文件的jar包。这时,可以通过“Build/Build Artifacts”来进行构建操作,这会进一步生成最终的Pr_Task2_3.jar文件。
将生成的jar包传输到Hadoop集群的Master节点上至关重要。通过命令行工具scp(Secure Copy Protocol),将jar包复制到远程主机的指定路径,例如:`scp -r /home/developer/Desktop/src/out/Pr_Task2_3.jar root@192.168.3.100:/home/`。这里,用户需要替换实际的本地路径和远程主机地址。
最后,运行MapReduce程序是在Hadoop集群上执行的。通过Hadoop的jar命令,指定jar包的路径以及其中的主类,格式为:`Hadoop jar /home/Pr_Task2_3.jar Phone_MR.Phone_Drive`。这里,`Phone_MR.Phone_Drive`是用户编写的MapReduce程序的名称和驱动类名。
总结来说,从创建项目结构、打包jar包、上传到Master节点,再到在Hadoop上运行,每一个环节都紧密相连,确保MapReduce任务能够顺利地在分布式环境中执行。理解并熟练掌握这些步骤对于开发和维护大型分布式计算系统至关重要。
- 1 -
1 MapReduce 程序的打包流程
1.1在主界面中,依次选择“File/Project Structure”命
令,可以打开 Project Structure 界面
1.2在 Project Structure 界面中,点击“+”,并依次选
择 JAR->From modules with dependencies,可以
打开 Create JAR from Modules 窗口
下载后可阅读完整内容,剩余4页未读,立即下载
2023-06-10 上传
2024-06-04 上传
2010-05-27 上传
2022-08-08 上传
2022-08-08 上传

weixin_35780426
- 粉丝: 26
- 资源: 286
 我的内容管理
展开
我的内容管理
展开







最新资源
- Vue_frontend_for_Laravel_rest_api
- react_calculator:react_calculator
- Smartclient-Top-Cases:基于 JavaFX Java Swing 的应用程序显示按类型分组创建的顶级案例
- Data-Mining
- php-cartography.alterway.fr:网站来源-Source website php
- hackrank2nd 1-11-2017,c语言软件代码大全源码,c语言
- C#-Leetcode编程题解之第19题删除链表的倒数第N个结点.zip
- gboard-large-clipboard:MVP重现Gboard中的大型剪贴板崩溃
- code_hub_acc_academy
- generator-jade:玉器项目的约曼发电机
- agv:用于自动导引车的 ROS Groovy 包
- peer-flight-search:对等机器人飞行搜索
- gtwizard-0-ex.zip
- Supermarket_Managment_System
- 23种设计模式图.zip
- 太阳高度角.m,vs2017c语言源码,c语言
