Nutch爬虫工作流程详解
需积分: 9 28 浏览量
更新于2024-10-06
收藏 91KB DOC 举报
"Nutch流程解析"
Nutch是一个开源的Web搜索引擎项目,它包含了爬虫(Crawler)和查询(Searcher)两个主要部分。这个系统设计得非常灵活,允许在爬取和搜索过程中进行定制和扩展。以下是Nutch的工作流程详解:
1. **Injector初始化Crawldb的总体过程**:
Injector是Nutch流程的起点,它的任务是将用户提供的种子URL(通常是一个文本文件,包含一系列起始网址)注入到Crawldb中。这一过程分为两个步骤:
- 第一步:读取用户指定的`urlDir`目录下的URL列表。
- 第二步:将这些URL转换为Nutch的内部数据结构,并存储到Crawldb中。
2. **Generator产生新的Segment**:
Generator负责从Crawldb中选择需要抓取的新URL。它会根据一些策略(如URL的最后抓取时间、重试次数等)生成一个待抓取的Segment,其中包含了一组URL。`generate()`方法接受Crawldb、目标Segment路径、最多抓取的URL数量以及当前时间戳作为参数。
3. **Fetcher抓取页面**:
Fetcher是实际执行HTTP请求的模块,它从Segment中的URL列表中取出URL,向服务器发送请求,接收响应,并将返回的网页内容保存到本地的Segment中。
4. **ParseSegment解析下载内容**:
解析器(Parser)对Fetcher抓取的网页内容进行分析,提取出文本、元数据等信息。Nutch支持多种解析器,如HTML解析器,可以识别出标题、链接、正文等元素。
5. **CrawlDb更新抓取URL库**:
在Parser处理完网页后,生成的新数据会被用来更新Crawldb。这包括了更新URL的状态(如已抓取、失败等)、存储解析后的元数据等。
6. **LinkDb更新Linkdb库**:
Linkdb是Nutch用来存储网页之间链接关系的数据库。每当一个新的Segment被处理,Linkdb都会更新,记录下新发现的链接。
7. **Indexer创建索引**:
最后,Indexer会从Segment中读取处理过的数据,将其转换为可搜索的索引。Nutch支持多种索引格式,常见的有Lucene索引。Indexer会将索引写入到一个或多个索引目录中,供Searcher使用。
以上步骤构成了Nutch的基本工作流程。在实际操作中,Nutch还提供了其他组件如UpdateDb用于更新Crawldb,Extractors用于提取特定格式的文档内容,以及Filters用于预处理数据。Nutch的整个流程可以通过配置文件进行定制,以适应不同的抓取和搜索需求。
在提供的流程图草稿中,可以看到从urlDir开始,经过Injector、Generator、Fetcher、Parser、CrawlDb和LinkDb的更新,最终由Indexer创建索引的详细步骤。每个阶段都有其特定的输入输出格式,如SequenceFile、MapFile等,这是Hadoop生态系统中的常见数据存储格式。Segment命名遵循日期时间格式(yyyyMMddHHmmss),以保持数据的时间序列性。
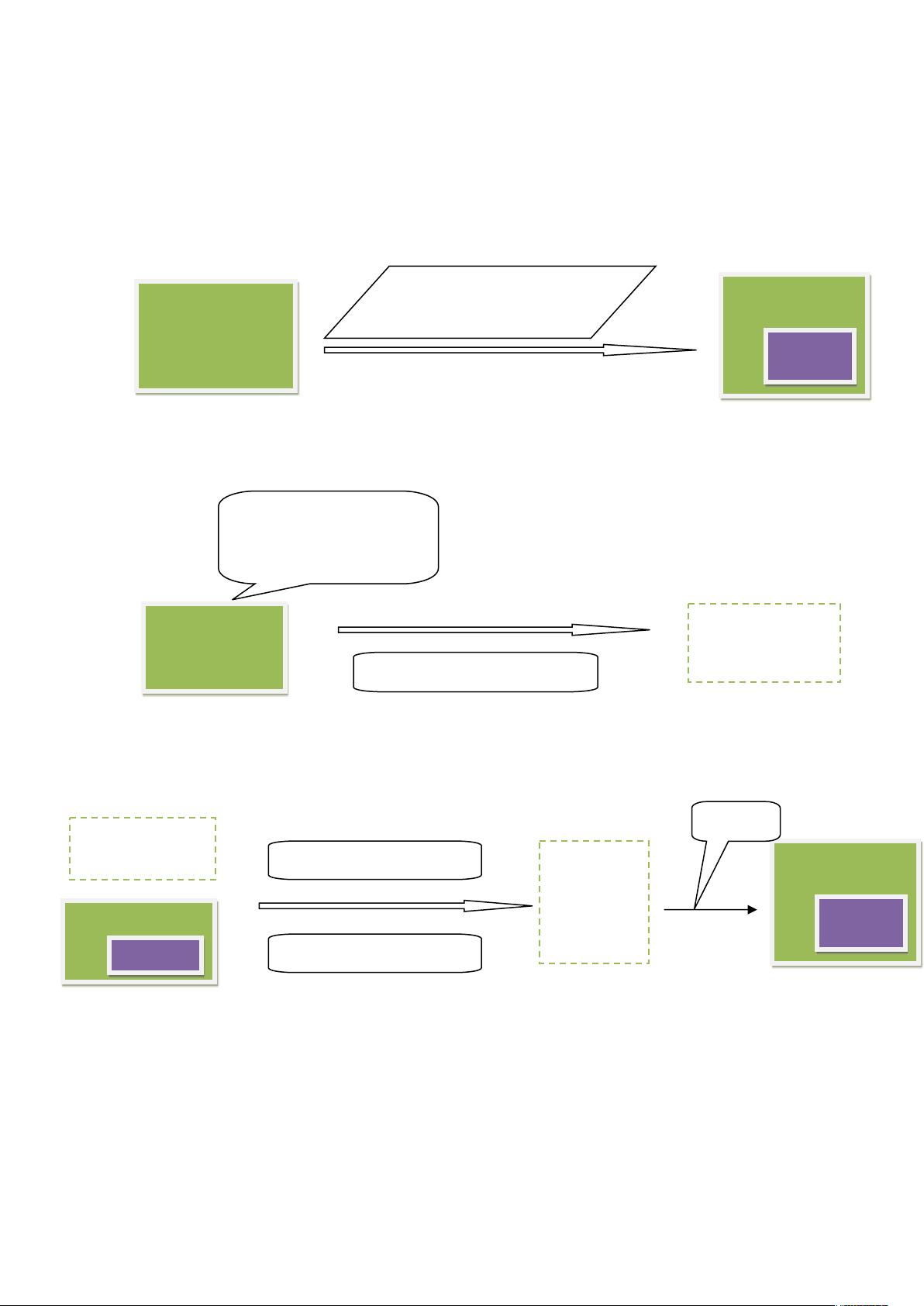
一、Injector 初始化 crawldb 的总体过程:
injector.inject(crawlDb, rootUrlDir);
第一个,还是详细点,我把上面的总体过程分为两步:
第一步:
第二步:
urlDir
urlDir+current->current
crawldb
current
urlDir tempDir
SequenceFileOutputFormat
urlDir 是程序入口时,用
户指定的那个 url 列表所
在的目录
tempDir
crawldb
current
newCrawldb
SequenceFileInputFormat
MapFileOutputFormat
crawldb
current
rename
下载后可阅读完整内容,剩余4页未读,立即下载
2010-12-02 上传
2011-08-14 上传
2023-09-06 上传
2023-06-12 上传
2023-05-21 上传
2023-05-24 上传
2023-06-11 上传
2023-03-31 上传
2024-01-25 上传

weizhilizhiwei
- 粉丝: 0
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- Unity UGUI性能优化实战:UGUI_BatchDemo示例
- Java实现小游戏飞翔的小鸟教程分享
- Ant Design 4.16.8:企业级React组件库的最新更新
- Windows下MongoDB的安装教程与步骤
- 婚庆公司响应式网站模板源码下载
- 高端旅行推荐:官网模板及移动响应式网页设计
- Java基础教程:类与接口的实现与应用
- 高级版照片排版软件功能介绍与操作指南
- 精品黑色插画设计师作品展示网页模板
- 蓝色互联网科技企业Bootstrap网站模板下载
- MQTTFX 1.7.1版:Windows平台最强Mqtt客户端体验
- 黑色摄影主题响应式网站模板设计案例
- 扁平化风格商业旅游网站模板设计
- 绿色留学H5模板:科研教育机构官网解决方案
- Linux环境下EMQX安装全流程指导
- 可爱卡通儿童APP官网模板_复古绿色动画设计
