浏览器工作原理:从URL输入到页面加载的完整流程
需积分: 0 39 浏览量
更新于2024-08-05
收藏 1.52MB PDF 举报
"04-导航流程:从输入URL到页面展示,这中间发生了什么?_For_vip_user_0011"
在这个话题中,我们将深入探讨从用户在浏览器中输入URL到页面最终显示的完整过程。这个流程涉及到网络、操作系统和Web技术等多个领域的知识。以下是对这个过程的详细解释:
首先,用户在浏览器的地址栏输入URL或搜索关键词。这时,浏览器首先会检查输入是否为书签或历史记录中的条目。如果是,它将直接跳转到相应的页面。如果不是,则进入下一阶段。
2.URL请求过程:
一旦用户按下回车键,浏览器开始解析输入的URL。解析包括验证URL的格式,解析协议(如HTTP或HTTPS)、主机名、路径和其他组成部分。浏览器根据解析得到的协议决定是否使用代理服务器,并构建一个HTTP或HTTPS请求。
3.网络进程:
网络进程负责处理实际的网络通信。它创建一个TCP连接(对于HTTP/1.x)或建立TLS连接(对于HTTPS),并向服务器发送HTTP请求。请求头包含了诸如Host、User-Agent等信息,以及请求方法(GET、POST等)。对于HTTPS,数据会被加密以保证传输安全。
4.服务器响应:
服务器接收到请求后,处理并返回响应,包括状态码(如200表示成功,404表示未找到),响应头,以及页面内容。如果服务器需要身份验证,可能会返回401状态码并要求客户端提供凭证。
5.准备渲染进程:
当浏览器接收到服务器的响应后,它需要创建或选择一个合适的渲染进程来显示页面。渲染进程是独立于浏览器进程的,每个Tab通常对应一个渲染进程,以实现进程隔离,减少因一个页面崩溃而影响其他页面的风险。
6.提交文档阶段:
浏览器进程将接收到的HTML文档提交给渲染进程,同时也会传递其他如CSS、JavaScript、图片等资源的URL。这个阶段称为提交文档。
7.渲染进程:
渲染进程接收文档后,开始解析HTML,构建DOM树。接着,CSS样式表被下载并解析,与DOM树结合形成CSSOM树。同时,JavaScript代码也可能开始执行,可能修改DOM或CSSOM,影响页面布局。
8.页面渲染:
当CSSOM树和DOM树合并成渲染树后,渲染进程计算每个元素的布局,然后进行绘制。这个过程称为布局和绘画,结果被存储在GPU内存中,用于屏幕显示。页面的动态更新,如脚本执行、网络资源加载,都会触发重排和重绘。
9.加载子资源:
在页面解析过程中,浏览器还会异步加载图片、字体等子资源。这些资源的加载可能触发额外的网络请求,并在加载完成后被插入到页面中。
10.页面交互:
页面完全加载后,用户可以开始与页面交互,如点击按钮、滚动等。这些交互会被传递给渲染进程,然后由渲染进程处理事件并更新页面。
总结,从输入URL到页面展示,这是一个涉及多个步骤和进程协作的过程,包括用户交互、网络请求、数据解析、页面渲染和用户交互。理解这一流程有助于我们更好地理解网页的工作原理,同时也对排查和优化网站性能至关重要。
从图中可以看出,当浏览器刚开始加载⼀个地址之后,标签⻚上的图标便进⼊了加载状态。但此时图中⻚⾯
显⽰的依然是之前打开的⻚⾯内容,并没⽴即替换为极客时间的⻚⾯。因为需要等待提交⽂档阶段,⻚⾯内
容才会被替换。
2.URL请求过程2.URL请求过程
接下来,便进⼊了⻚⾯资源请求过程。这时,浏览器进程会通过进程间通信(IPC)把URL请求发送⾄⽹络
进程,⽹络进程接收到URL请求后,会在这⾥发起真正的URL请求流程。那具体流程是怎样的呢?
⾸先,⽹络进程会查找本地缓存是否缓存了该资源。如果有缓存资源,那么直接返回资源给浏览器进程;如
果在缓存中没有查找到资源,那么直接进⼊⽹络请求流程。这请求前的第⼀步是要进⾏DNS解析,以获取请
求域名的服务器IP地址。如果请求协议是HTTPS,那么还需要建⽴TLS连接。
接下来就是利⽤IP地址和服务器建⽴TCP连接。连接建⽴之后,浏览器端会构建请求⾏、请求头等信息,并
把和该域名相关的Cookie等数据附加到请求头中,然后向服务器发送构建的请求信息。
服务器接收到请求信息后,会根据请求信息⽣成响应数据(包括响应⾏、响应头和响应体等信息),并发给
⽹络进程。等⽹络进程接收了响应⾏和响应头之后,就开始解析响应头的内容了。(为了⽅便讲述,下⾯我
将服务器返回的响应头和响应⾏统称为响应头。)
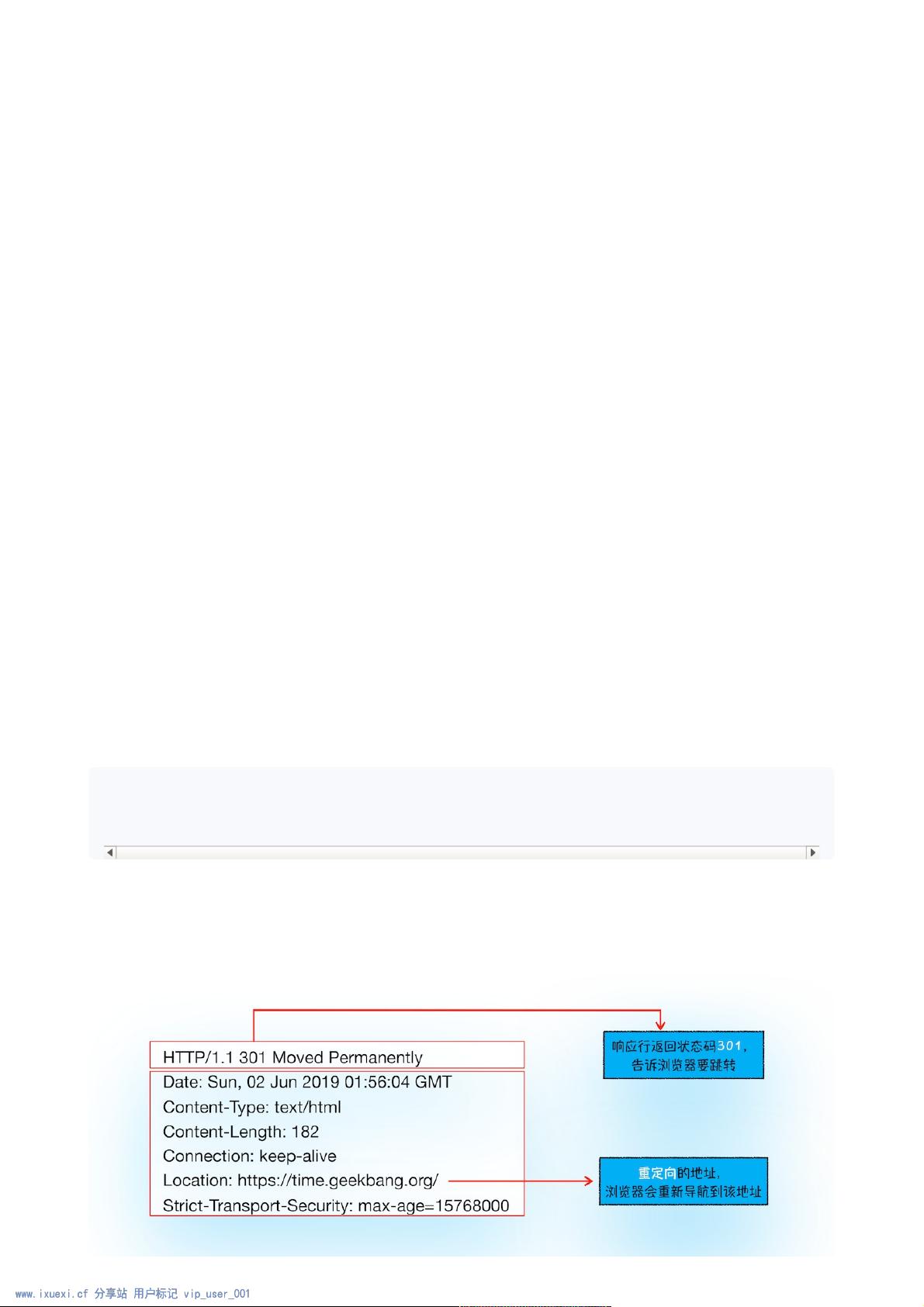
(1)重定向(1)重定向
在接收到服务器返回的响应头后,⽹络进程开始解析响应头,如果发现返回的状态码是301或者302,那么
说明服务器需要浏览器重定向到其他URL。这时⽹络进程会从响应头的Location字段⾥⾯读取重定向的地
址,然后再发起新的HTTP或者HTTPS请求,⼀切⼜重头开始了。
⽐如,我们在终端⾥输⼊以下命令:
curl-I+URL的命令是接收服务器返回的响应头的信息。执⾏命令后,我们看到服务器返回的响应头信
息如下:
curl-Ihttp://time.geekbang.org/
剩余13页未读,继续阅读
2022-08-04 上传
2022-08-04 上传
2022-08-04 上传
2023-06-03 上传
2023-06-10 上传
2023-05-25 上传
2023-06-01 上传
2023-09-21 上传
2023-05-24 上传

ask_ai_app
- 粉丝: 24
- 资源: 326
 我的内容管理
展开
我的内容管理
展开







最新资源
- ES管理利器:ES Head工具详解
- Layui前端UI框架压缩包:轻量级的Web界面构建利器
- WPF 字体布局问题解决方法与应用案例
- 响应式网页布局教程:CSS实现全平台适配
- Windows平台Elasticsearch 8.10.2版发布
- ICEY开源小程序:定时显示极限值提醒
- MATLAB条形图绘制指南:从入门到进阶技巧全解析
- WPF实现任务管理器进程分组逻辑教程解析
- C#编程实现显卡硬件信息的获取方法
- 前端世界核心-HTML+CSS+JS团队服务网页模板开发
- 精选SQL面试题大汇总
- Nacos Server 1.2.1在Linux系统的安装包介绍
- 易语言MySQL支持库3.0#0版全新升级与使用指南
- 快乐足球响应式网页模板:前端开发全技能秘籍
- OpenEuler4.19内核发布:国产操作系统的里程碑
- Boyue Zheng的LeetCode Python解答集
