声明式提示调优:提升视觉问答性能的新方法
64 浏览量
更新于2024-06-16
收藏 1.57MB PDF 举报
"本文提出了基于声明的可视化提问提示调优(Declaration-based Prompt Tuning,简称DPT),这是一种针对预训练视觉语言(VL)模型进行微调的新方法,旨在解决预训练与微调目标不一致的问题,提高模型在视觉问答(VQA)等任务上的泛化能力。DPT通过文本改编将问题转化为陈述句形式,并采用任务自适应的方式优化目标函数。实验结果显示,DPT在全监督和少样本设置下均能显著提升VQA的准确性。"
近年来,预训练-微调范式在多模态领域,特别是视觉语言任务如视觉问题回答(VQA)中,已成为主流。预训练模型通过自监督任务,如掩码语言建模(MLM)和图像-文本匹配(ITM),学习跨模态的表示。然而,预训练阶段和微调阶段的目标函数差异,可能导致模型在下游任务中的泛化能力受限,同时需要大量标注数据进行微调。
为了解决这一问题,研究者们提出了DPT方法。DPT的核心在于将原始问题转换成声明性的陈述句,以便更好地与预训练阶段的任务对齐。此外,DPT还采用了任务自适应策略,即沿用预训练阶段的目标函数来优化VQA任务。这样做的好处是,可以减少预训练和微调之间的目标不匹配,同时降低对大量标注数据的依赖。
在GQA数据集上的实验显示,DPT在全监督设置下提高了2.68%的准确率,而在零样本或少样本设置下,性能提升超过了31%。这表明DPT在未见过的数据或有限标注数据的情况下,也能保持出色的泛化能力。
DPT的创新之处在于其结合了文本改编和任务自适应,提供了一种有效的方法来调整预训练VL模型以适应VQA任务。这种方法对于减少对大量标注数据的依赖和提高模型的迁移学习能力具有重要意义。未来的研究可能进一步探索DPT在其他视觉语言任务中的应用,或者改进DPT以适应更复杂的任务和环境,如虚拟现实场景。
论文和相关代码可以在指定网址上找到,这为研究人员和开发者提供了实践和扩展DPT方法的资源。这项工作为多模态理解和交互的智能系统设计提供了新的思路,有助于推动预训练模型在视觉问答和相关领域的应用。
+v:mala2277获取更多论
文
任务适应(MLM)
分类
任务适应(ITM)
匹配
C
s
ans
TopK
C
{s
mat
}
K1
k 0
的
gt
公元
VQA
MLM
CE
a
G
T
{a}
K1
k0
VQA
ITM
情态型嵌入词位嵌入词
嵌入
特殊令牌嵌入
Bbox
区域功能
C
Concat
输出
H
[CLS]
H
[MA SK]/a
k
特征路
径
梯度路
径
0 0
01
...
015 0 16
...
021
0 22
[CLS]
问题
宣言
[SEP]
文本改编
声明生成
问题
编解码器
宣言
-
-
-
-
-
-
m
+
n
+2
-
-
1
1
...
1
1
...
多层变压器
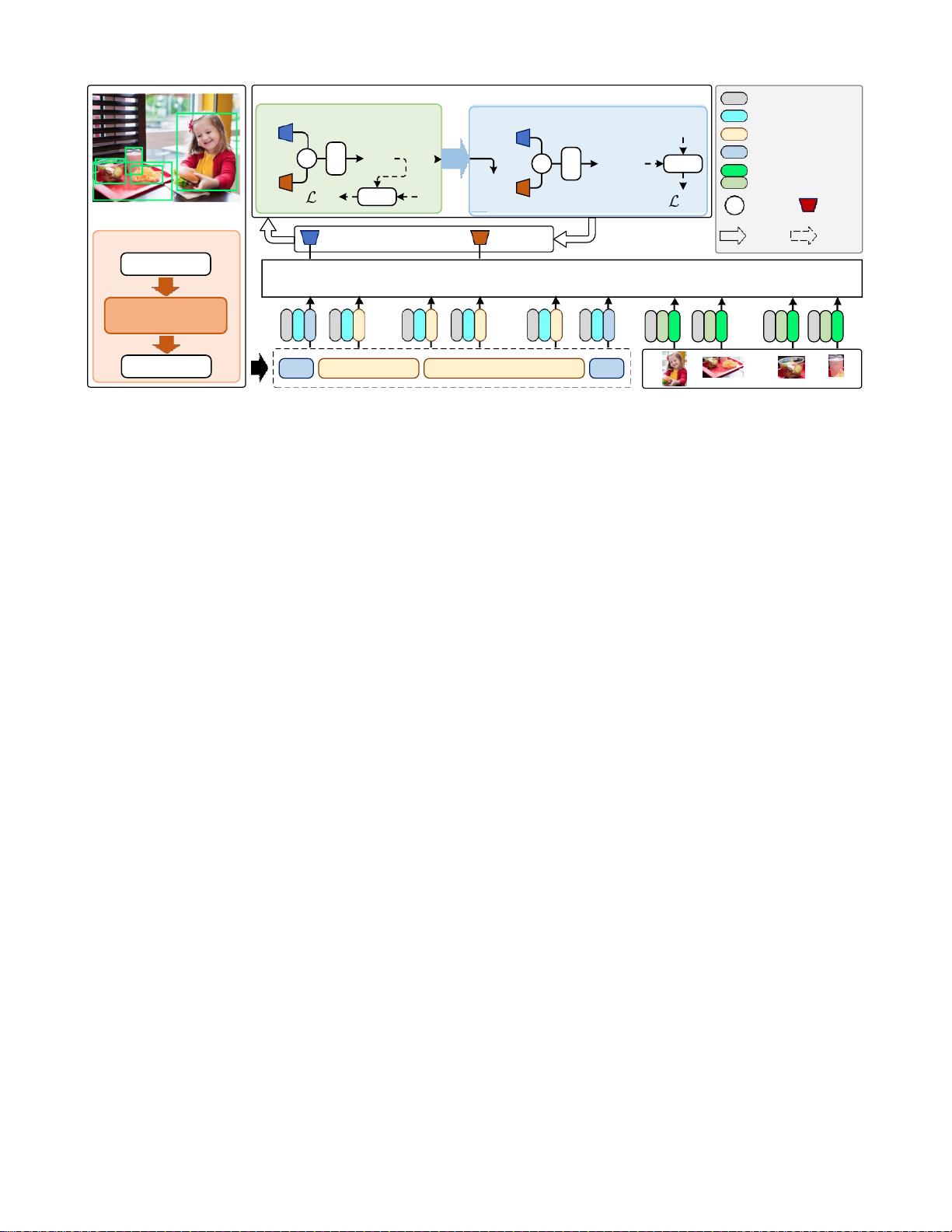
图
2
:我们提出的
DPT
方法的框架。问题被转换为声明,这些声明被连接成文本输入形式,并与区域特征一起被馈送到预先训练
的
VL
模型。输出的
[MASK]
和
[CLS]
表示将提示模型预测答案分数或(图像
-
文本)匹配分数。
多类分类问题形式上,
VQA
任务的目标是在给定图像
I
和问题
Q
时从候选答案集中选择正确答案
a
。为此,
我们提出了
VQA
的经典范式,即
预训练然后微调范
式
。
预训练-然后微调范式。给定一个 通用架构,
例如,
Transformer,该模型首先通过手动设计的自监督任务在
大规模图像-文本语料库上进行预训练,
例如,
MLM和
ITM。为此,从图像I提取的一组区域提议 ,
o
1
,
o
2
,
...
,
o
n
和问题的词嵌入
Q,
e1
,
e2
,
.
e
m
转换为输入格式,
即,
e
[
CLS
]
,
e
1
,
e
2
,
...
,
e
m
,
e
[
SEP
]
,
o
1
,
o
2
,
...
,
o
n
,其
被 馈 送 到 模 型 并 被 融 合 以 产 生 隐 藏 表 示
h
i
i
=0
, 其 中
e
[
CLS
]
、
e
[
SEP
]
是特殊令牌的嵌入。该模型进一步优化使
用自监督
目标.然后,在VQA任务的微调阶段,输出[CLS]被用来
执行多类分类,并通过交叉熵损失进行优化。该范式引
入了一个全新的微调任务,需要大量的标记数据在下游
任务中进行泛化。
3.2
基于声明的提示调优
促进预训练VL模型的泛化 对于下游VQA任务,我们
提出了一个基于声明的提示调优(DPT)范式,将VQA
重新定义为预训练任务格式。如图1(b-d)所示,存在
两个挑战,
即,
不同形式的文本输入(问题
与
声明)和
不同的任务目标(传销ITM
与
答案分类)。为了解决这
些问题,我们提出了(1)文本适应模块,将问题转换
为相应的陈述句,
(2)任务适应模块重新制定答案预测-
基于声明生成的
文本适配旨在转换文本输入(
即,
问题)到预训练表格
(
即,
陈述 句),
例如,
“女孩留下的红色物体 是什
么
?
“是”一个红色[面具]是女孩留下的
。
“.为此,我们引
入了声明生成,它将此过程表示为一个翻译问题,其中
源文本和目标文本分别是
问题
和相应
的
dec-panel。形式
上,我们首先使用GQA数据集的注释构建声明数据集
[
Hudson和Manning,2019 a
]
,其中然后,编码器-解码
器网络(T5
[
Raffelet al. 2020年
]
), 该数据集并使用
标准自回归交叉熵损失进行优化。最后,该模型可以用
于将 问 题 转换为各 种 VQA 数据 集的 陈 述 句,
例如 ,
GQA
[
Hudson 和 Manning , 2019 a
]
和 VQA
[
Agrawal
等
人,
,2015
]
。更多详细信息请参见第
4.1附录
任务适应
配备陈述句,VQA可以被改造成预训练任务格式,
即,
MLM和ITM。顺应主要涉及文本输入格式和任务目标两
个 方 面 。 具 体 来 说 , MLM 在 文 本 输 入 中 保 留 一 个
[MASK]标记,并通过多类分类来预测答案。 用顶部替
换[MASK]- 从MLM预测的k个候选答案,并使用二进
制分类来预测匹配分数。
适应MLM任务。为了将VQA重新公式化为MLM任务,
问题和声明句被连接以形成文本输入:
传销
MLM和ITM任务。这两个经过调整的任务被结合起来决
定最终的答案。
T (
Q
)
=[CLS]Q
答案:
D[SEP]
(
1
)
其中,
T
MLM
表示与
MLP
[CLS]
MLP
[CLS] [
面具
]
剩余14页未读,继续阅读
790 浏览量
2613 浏览量
125 浏览量
140 浏览量
145 浏览量
312 浏览量
2024-12-11 上传
145 浏览量
2023-05-22 上传

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Verilog实现的Xilinx序列检测器设计教程
- 九度智能SEO优化软件新版发布,提升搜索引擎排名
- EssentialPIM Pro v11.0 便携修改版:全面个人信息管理与同步
- C#源代码的恶作剧外表答题器程序教程
- Weblogic集群配置与优化及常见问题解决方案
- Harvard Dataverse数据的Python Flask API教程
- DNS域名批量解析工具v1.31:功能提升与日志更新
- JavaScript前台表单验证技巧与实例解析
- FLAC二次开发实用论文资料汇总
- JavaScript项目开发实践:Front-Projeto-Final-PS-2019.2解析
- 76云保姆:迅雷云点播免费自动升级体验
- Android SQLite数据库增删改查操作详解
- HTML/CSS/JS基础模板:经典篮球学习项目
- 粒子群算法优化GARVER-6直流配网规划
- Windows版jemalloc内存分配器发布
- 实用强大QQ机器人,你值得拥有
