大数据日志分析实战:从环境配置到工具应用
需积分: 50 24 浏览量
更新于2024-07-18
收藏 7.49MB PDF 举报
"该资源是一份关于大数据日志分析的实战教程,主要涵盖了从基础的Linux操作系统使用到大数据处理工具Hadoop、Spark、Kafka、Flume和Hive的安装与配置,以及如何使用IntelliJ IDEA进行SparkStreaming的开发环境搭建。教程详细讲解了每个步骤,包括版本选择、集群搭建、问题解决以及具体工具的应用,适合想要深入学习大数据日志分析的读者。"
本资源详细介绍了大数据日志分析的实践过程,首先从基础的Linux环境入手,选择了CentOS操作系统,并逐步讲解了CentOS的下载、安装及使用技巧,包括设置快捷键、网络配置和远程连接等,确保读者能够熟练操作Linux环境。
接着,资源进入了大数据组件的选择和安装阶段,提到了Hadoop、Spark、Kafka、Flume和Hive等工具的版本选择,这对于构建稳定的大数据处理平台至关重要。随后,详细介绍了Hadoop和Spark集群的搭建,包括Scala的安装,以及Spark的主要模块和SparkSQL的使用方法,帮助读者理解Spark的基本架构和功能。
在Kafka部分,不仅讲述了Kafka集群的安装,还针对Zookeeper进程中可能出现的问题提供了解决方案。Flume的安装和使用则强调了如何有效地收集和传输日志数据,同时提出了在使用Flume时需要思考的问题。
对于开发环境的搭建,资源提供了使用IntelliJ IDEA配置SBT版本SparkStreaming的详细步骤,包括手动添加本地依赖和在Windows环境下配置Scala开发环境。此外,还展示了如何在SparkLocal模式下进行日志文本的清洗工作,这是日志分析的前期准备。
整个教程通过实战案例,系统地引导读者掌握大数据日志分析的各个环节,对于提升大数据处理和分析能力具有很高的参考价值。无论是初学者还是有一定经验的开发者,都能从中受益。
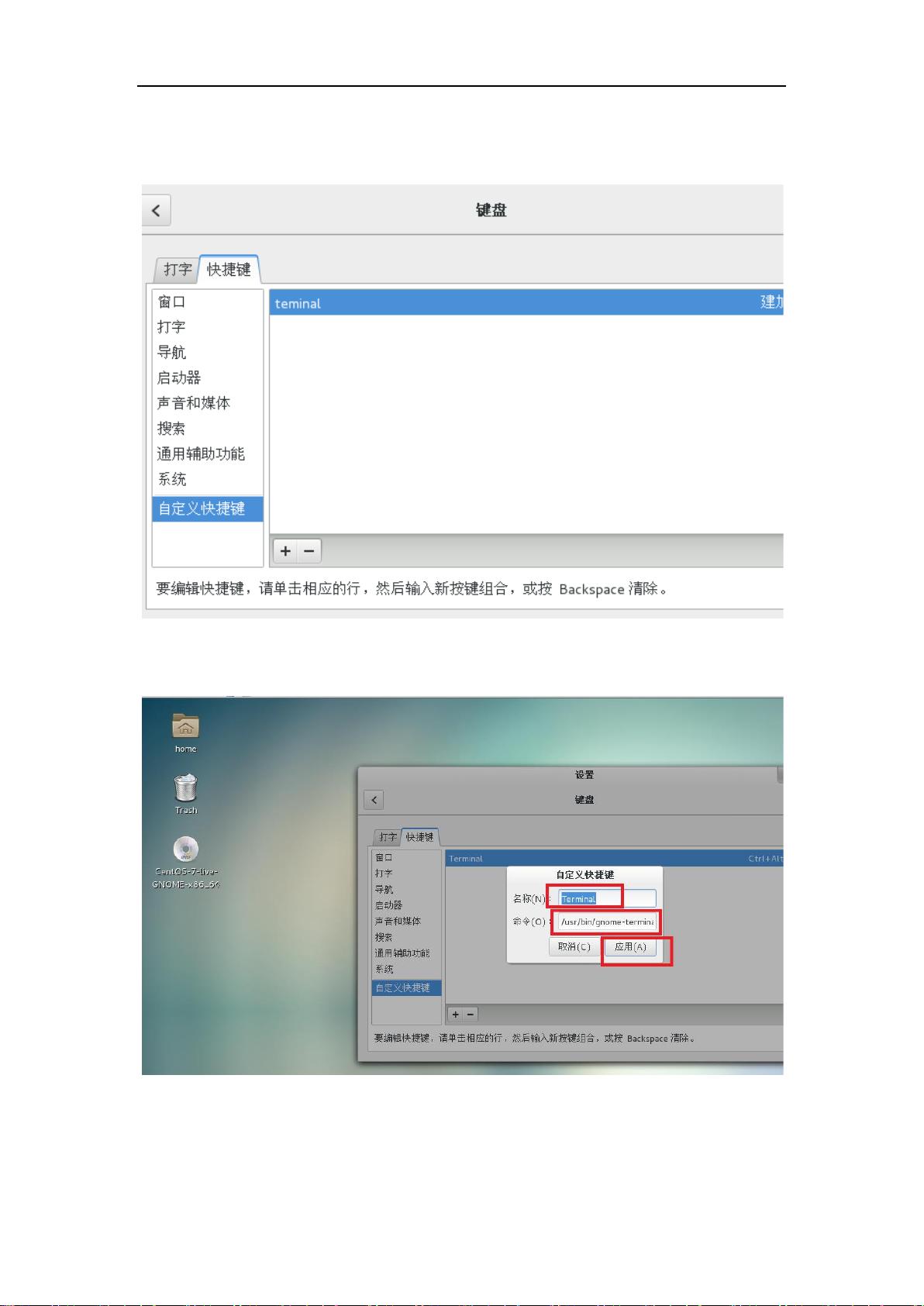
about 云--活到老学到老
需要点击右侧,点击之后,会看到建加速键
【注意路径不要写错,否则自定义不成功,上图中我的路径就写错了】
,按下 ctrl+alt+t
自定义就完成了,会看到相应的键,如下图所示。【比较难操作的是选定可能弹出上图所示内容】
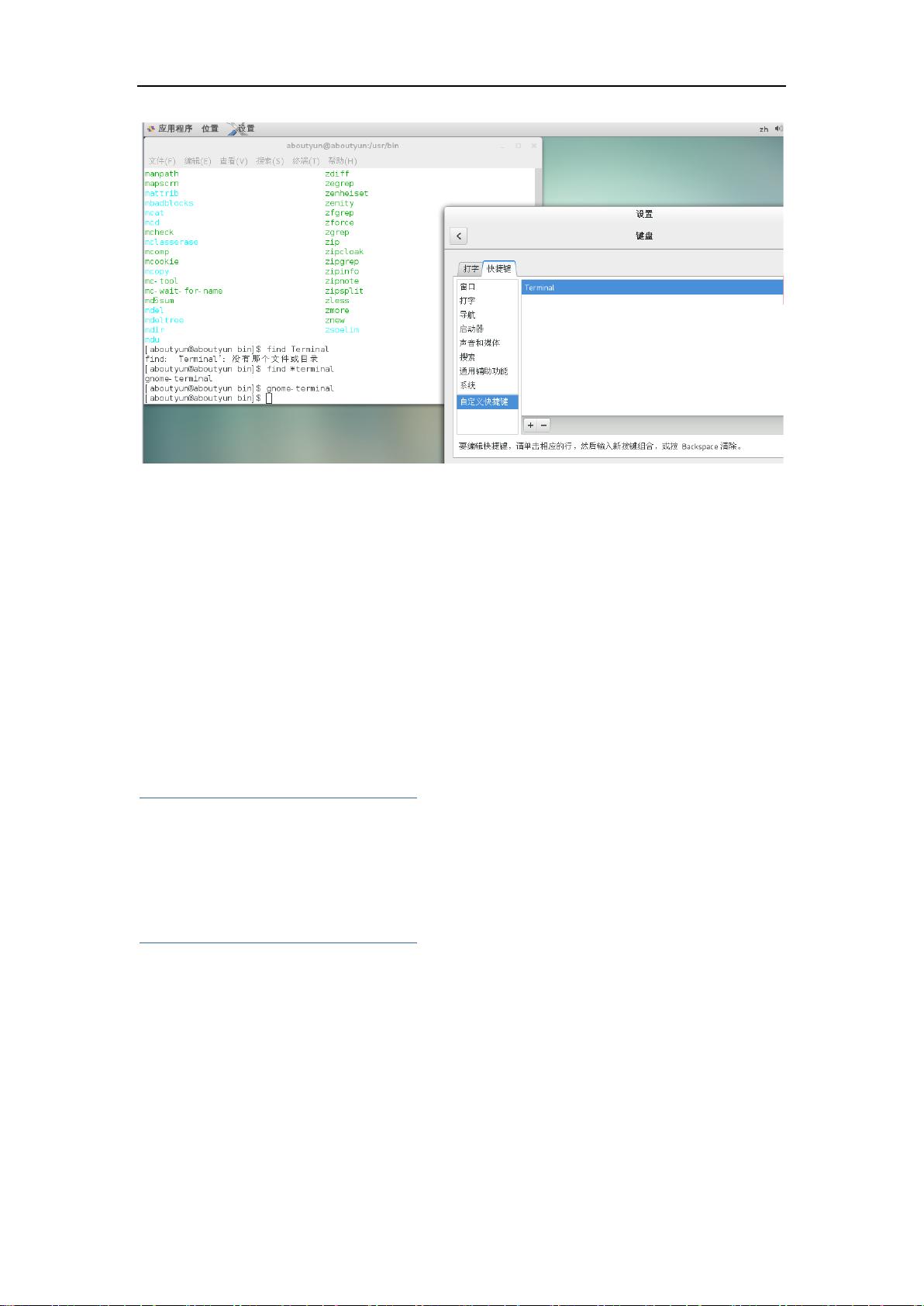
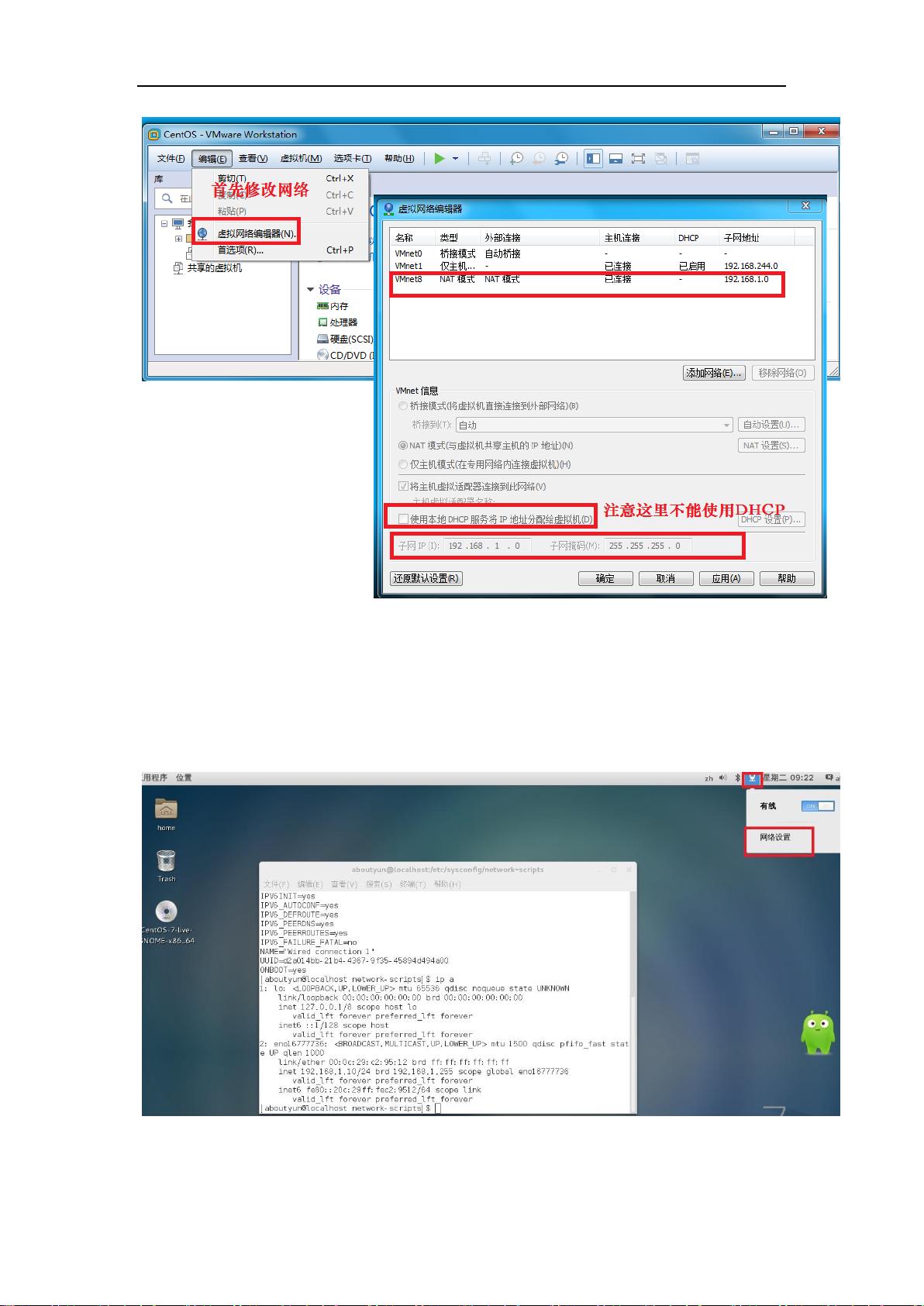
剩余193页未读,继续阅读
319 浏览量
170 浏览量
点击了解资源详情
253 浏览量
148 浏览量
249 浏览量
720 浏览量
118 浏览量
976 浏览量

说来世事不如闲
- 粉丝: 19
- 资源: 17
 我的内容管理
展开
我的内容管理
展开







最新资源
- 浙江大学C++教材 非常详细
- windows组策略应用攻略
- JavaServer Faces in Action
- IBatis开发指南
- Eclipse中文教程
- 宋劲杉Linux C编程一站式学习_PDF版本——非常好的C,linux编程入门教程_2009.3.6最新版,不断更新到最新版
- verilog 入门
- 考研 自做简易倒计时器
- 往oracle数据库中,插入excel文件中的数据
- WEB标准与网站重构(PDF)
- Hibernate开发指南.pdf
- 加速度传感器 MMA7260Q
- 教你认识电子元件(有图)
- 汽车修理管理课程设计
- Grails 入门指南
- 融合粒子群优化算法与蚁群算法的随机搜索算法
