领导者引导的多尺度注意力深度网络提升人员再识别性能
174 浏览量
更新于2024-07-15
收藏 2.46MB PDF 举报
本文主要探讨了"基于领导者的多尺度注意力深度架构"在人员重新识别(person re-identification, Re-ID)领域的应用。Re-ID是一个在公共空间中通过非重叠摄像头视角寻找同一人的任务,由于监控视频中的个体常常穿着相似的衣物,这使得他们在视觉上的区别微小,往往依赖于特定的位置和视角细节。为此,研究人员提出了MuDeep(Multi-scale Deep Learning with Leader-Based Attention)网络,这是一个创新的深度学习模型,特别设计用于解决这个挑战。
MuDeep的核心是两个新颖的层结构:多尺度深度学习层和基于领导者注意力学习层。多尺度深度学习层允许网络在不同的尺度级别上学习深度特征表示,这样可以捕捉到不同尺寸的人体特征,增强模型对穿着相似性的鲁棒性。它不仅考虑了全局信息,还关注了局部细节,提高了特征的区分度。
另一方面,基于领导者注意力学习层的关键在于它能够智能地整合来自多个尺度的信息。这个层通过模拟领导者角色,动态调整每个尺度的重要性,确保模型能够专注于最具区分性的特征区域。这种注意力机制有助于提升模型在处理复杂场景时的性能,例如遮挡、光照变化等,从而提高识别精度。
实验结果表明,MuDeep在多个基准数据集上展现出显著的优势,超越了当时的最新技术。尤其是在领域泛化(domain generalization)测试中,MuDeep显示出更强的适应性和更好的跨环境识别能力。这证明了该方法在实际应用场景中的实用性和有效性。
总结来说,这篇研究论文深入剖析了如何利用多尺度注意力机制提升人员重新识别的性能,特别是在面对复杂场景时的特征选择和区分能力。它为未来的Re-ID研究提供了一个有价值的框架,有望推动该领域的发展和实际应用。
[40], [41], [42], or learn better relative distances of triplet
training samples [43], [44], [45], [46], or learn better similar-
ity metrics of any pairs [23], [29], [47], [48]. To cope with the
data sparsity problem, Xiao et al. [49] proposed a single
deep network built upon the inception module [50], com-
bined multiple re-id datasets together for training, and
introduced a domain guided dropout strategy to achieve
domain adaptation for each individual dataset. More
recently, variants of Siamese Network have been studied
for person re-id [51], [52]. Pairwise and triplet comparison
objectives were utilized to combine several sub-networks
for person re-id in [27]. Zhong et al. [29] proposed a novel
method to utilize hard sample mining online with triplet
loss in person re-identification. Similarly, Chen et al. [43]
improved triplet loss and proposed a deep quadruplet net-
work. With the success of generative adversarial networks
(GAN) in image generation, Wei et al. [53] and Zhong et al.
[26] applied GAN in the re-id task to solve the problem of
domain gap and overcame the problem of lacking labeled
data in new domains. Among these existing approaches, a
number are closely related which are worth mentioning and
differentiating from our model.
1) Our MuDeep generalizes convolutional layers with
multi-scale representation learning. In particular, we
propose a multi-scale stream layer and a leader-
based attention learning layer for multi-scale learn-
ing, which is clearly different from the ideas of com-
bining multiple sub-networks [27] or channels [30]
with the pairwise or triplet loss.
2) He et al. [54] proposed a multi-branch deep network
to obtain global feature representations and local fea-
ture representations with multiple granularities. In
contrast, our work applies a multi-branch architec-
ture to not only learn the feature representations of
person images at multiple scales, but also share the
weights of previous layers to exploit the complemen-
tarity between multi-scale feature representations.
3) Both Shen et al. [55] and Guo et al. [51] improved the
accuracy of person re-id by using a multi-level simi-
larity, which was computed by multi-level features.
Although the multi-level features are related to ana-
lyzing person images at multiple scales, our MuDeep
is specially designed for multi-scale feature learning
with multiple branches. Importantly, features are
extracted using convolutional filters of different
receptive fields at the same abstraction level, i.e., in
the same convolution block/layer rather than across
different layers. Moreover, in order to learn scale-
specific feature representations, the weights of the
multiple branches are not shared between any two
of them in our network.
2.2 Multi-Scale re-id
The idea of multi-scale learning for re-id was first exploited
in [56]. However, the definition of scale is different: It was
defined as different levels of input resolutions rather than
as in our definition, which applies multi-scale filters.
Despite the similarity between terminology, very different
problems are tackled in these two approaches. Compared
with previous multi-scale methods in re-id, Chen et al. [57]
adopted m scale-specific networks to learn deep pyramidal
features from images with different scales; however, our
MuDeep has a much simpler architecture and only utilizes
one network with multiple branches to extract m scale-
specific representations of one person image. Wang et al.
[58] extracted multi-resolution embeddings in one network
at different stages, and fused them with a simple weig-
hted sum to solve the problem of person re-identification
under resource constraints. Our MuDeep concentrates on
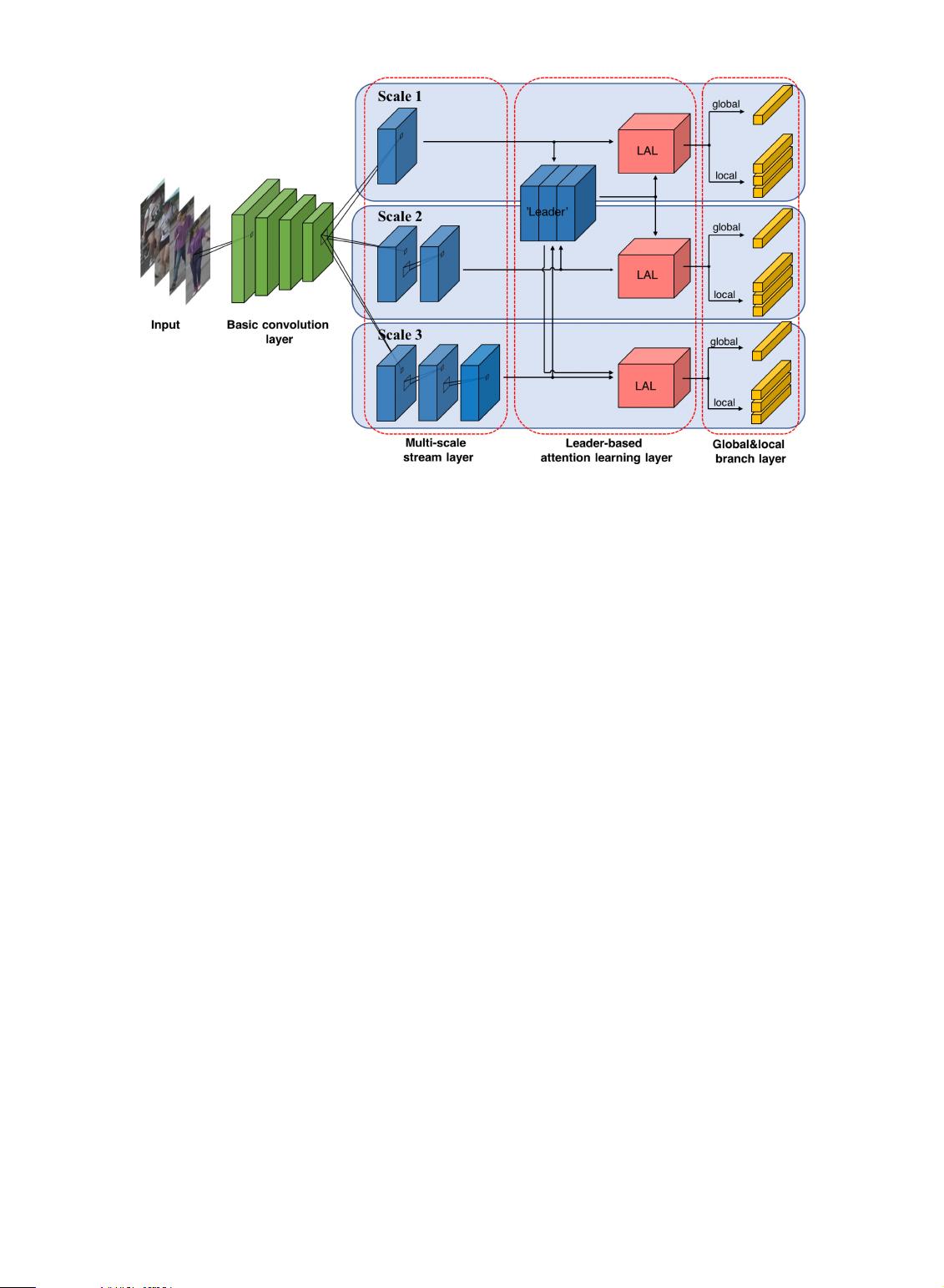
Fig. 2. Overview of MuDeep architecture. The multi-scale stream layer first analyzes feature maps with multiple scales. Then the leader-based
attention learning layer is followed to automatically discover and emphasize important spatial locations. Finally, the global and local branch layer
is utilized to extract discriminate features from global and local parts. Note that the parameters of each scale are not shared. ‘LAL’ means the
Leader-based Attention Learning layer, with further details shown in Fig. 4.
QIAN ET AL.: LEADER-BASED MULTI-SCALE ATTENTION DEEP ARCHITECTURE FOR PERSON RE-IDENTIFICATION 373
剩余14页未读,继续阅读
2022-09-04 上传
2023-05-10 上传
2023-05-10 上传
2023-05-09 上传
2023-05-22 上传
2023-03-30 上传
2023-07-15 上传
2023-05-10 上传
2023-05-25 上传

weixin_38631331
- 粉丝: 5
- 资源: 907
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebLogic集群配置与管理实战指南
- AIX5.3上安装Weblogic 9.2详细步骤
- 面向对象编程模拟试题详解与解析
- Flex+FMS2.0中文教程:开发流媒体应用的实践指南
- PID调节深入解析:从入门到精通
- 数字水印技术:保护版权的新防线
- 8位数码管显示24小时制数字电子钟程序设计
- Mhdd免费版详细使用教程:硬盘检测与坏道屏蔽
- 操作系统期末复习指南:进程、线程与系统调用详解
- Cognos8性能优化指南:软件参数与报表设计调优
- Cognos8开发入门:从Transformer到ReportStudio
- Cisco 6509交换机配置全面指南
- C#入门:XML基础教程与实例解析
- Matlab振动分析详解:从单自由度到6自由度模型
- Eclipse JDT中的ASTParser详解与核心类介绍
- Java程序员必备资源网站大全
