大数据存储对比:Delta Lake, Iceberg, Hudi
版权申诉
15 浏览量
更新于2024-06-17
收藏 17.13MB PDF 举报
"阿里数据湖选型对比分析"
在大数据领域,选择合适的数据湖解决方案是至关重要的。本PPT深入比较了三个主流的数据湖技术:Delta Lake、Apache Iceberg和Apache Hudi,旨在帮助用户理解它们的关键特性、成熟度以及适用场景。
首先,Delta Lake是一种开源的存储层,它为Apache Spark和大数据工作负载提供了ACID(原子性、一致性、隔离性和持久性)事务。其核心特性包括数据一致性、时间旅行(Time Travel)和元数据管理。Delta Lake通过将ACID交易引入大数据处理,确保了数据的可靠性和准确性,适合于需要强一致性的场景。
Apache Iceberg则是一个用于大规模分析数据集的表格式,它在处理数十PB数据时能提供高查询性能,并支持原子提交、并发写入和SQL兼容的表演化。Iceberg的设计目标是独立于计算引擎,这意味着它可以在不同的大数据处理框架下使用,如Spark、Flink等,适用于需要跨平台兼容性的环境。
Apache Hudi,全称为Hadoop更新增量,专注于在分布式文件系统(DFS)上的大型分析数据集的摄入和管理。Hudi提供了多种数据写入类型,如插入、更新和删除,支持实时查询和批处理。Hudi的独特之处在于其可变文件格式,允许在线更新和删除记录,同时保持良好的查询性能,适用于流处理和批处理的统一场景。
对比来看,Delta Lake在事务处理和时间旅行功能上具有优势,适合需要频繁更新和版本控制的应用;Iceberg则在跨引擎兼容性和大规模数据分析方面表现出色;而Hudi以其对流处理的支持和可变文件格式,更适合实时分析和持续更新的需求。
在工具集成和性能方面,Delta Lake与Spark生态紧密集成,而Iceberg和Hudi则有更广泛的生态系统支持。Hudi在处理大数据更新和删除时可能具有更好的性能。
总结来说,选择数据湖技术应考虑业务需求、数据处理模式、性能要求以及现有技术栈的兼容性。未来理想的数据湖解决方案应具备良好的数据质量保证、事务独立性、统一的批处理与流处理能力、可插拔的存储层、扩展性以及强大的元数据管理功能。
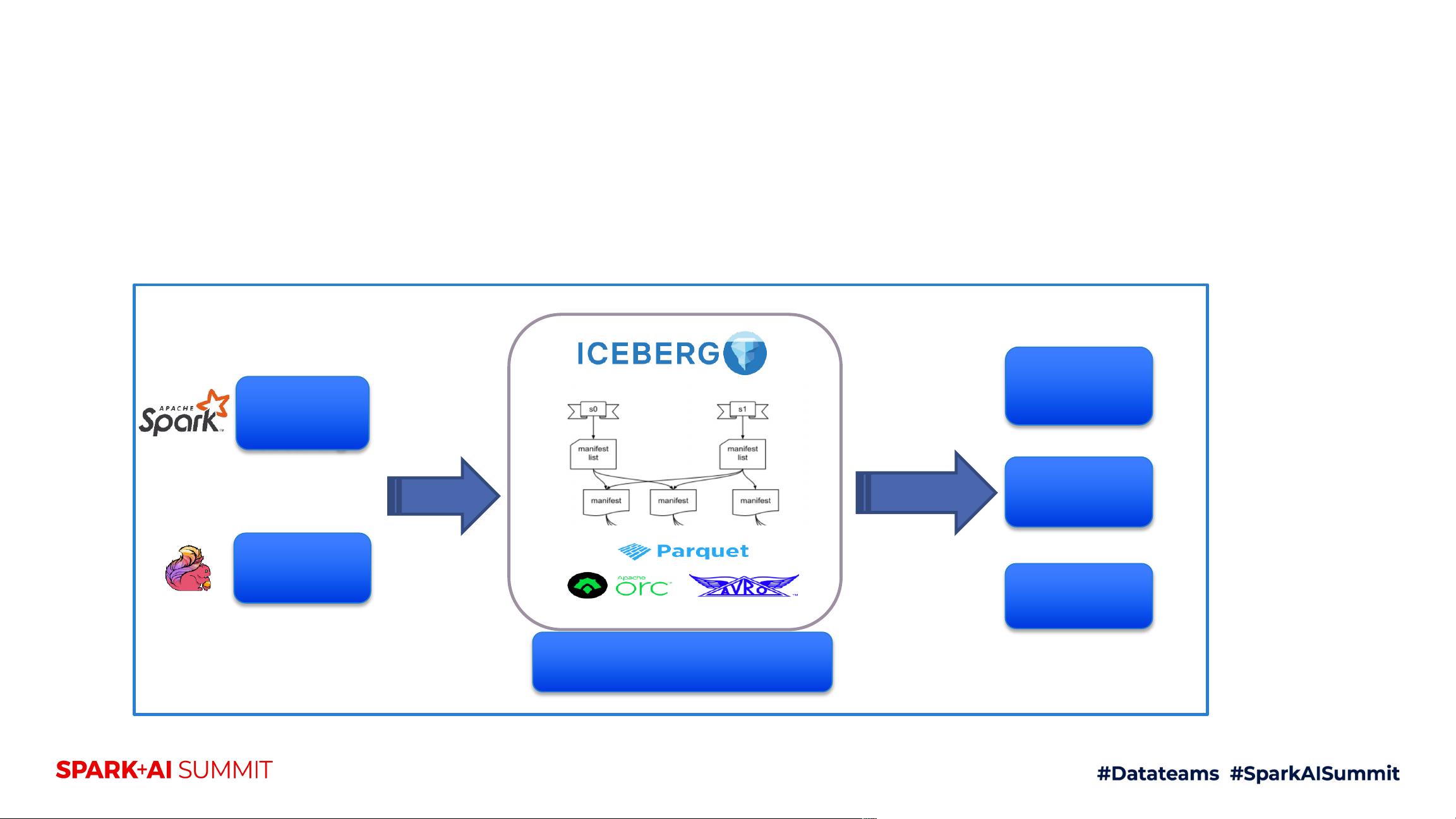
Apache Iceberg
An table format for huge analytic datasets which delivers high query performance for tables with tens of
petabytes of data, along with atomic commits, concurrent writes, and SQL-compatible table evolution.
DFS/Cloud Storage
Spark Batch
&
Streaming
AI &
Reporting
Interactive
Queries
Streaming
Streaming
Analytics
剩余26页未读,继续阅读
2023-09-30 上传
299 浏览量
184 浏览量
2023-09-11 上传
112 浏览量
173 浏览量
2009-09-10 上传
2016-11-24 上传


西攻城狮北
- 粉丝: 8450
- 资源: 434
 我的内容管理
展开
我的内容管理
展开







