DataStage8并行作业教程:官方指南
"DataStage8 是IBM的一款强大的ETL(Extract, Transform, Load)工具,用于数据集成和数据仓库建设。本教程是官方提供的并行JOB开发指南,旨在帮助用户了解和掌握DataStage8的使用,包括如何打开和运行样本作业、查看和编译作业,以及运行和检查作业结果等基本操作。"
在DataStage8中,用户可以构建复杂的数据处理流程,将来自不同源的数据清洗、转换,并加载到目标系统中。这个教程是针对初学者的,通过一系列的模块化教学,逐步引导用户熟悉DataStage的工作环境和功能。
第1章:介绍
这一章通常会概述DataStage8的基本概念,其在数据集成中的作用,以及并行JOB的概念。并行JOB是DataStage的一个关键特性,它能利用多处理器或集群资源,提高数据处理速度。
第2章:教程项目目标
本章会明确教程的目标,可能包括理解DataStage8的工作流程、掌握作业设计和管理,以及如何实现数据的高效处理和迁移。
第3章:模块1 - 打开和运行样本作业
这部分详细介绍了如何启动DataStage的Designer客户端,它是进行作业设计的主要工具。然后,教程会指导用户打开提供的样本作业,以便学习和实践。首先,用户会学习如何打开和浏览作业结构,理解各个组件的功能。
Lesson1.1:打开样本作业
这部分重点是熟悉Designer界面,以及如何找到和打开示例作业。用户将学习如何导航和理解作业的拓扑视图。
Lesson1.2:查看和编译样本作业
接下来,用户将深入到作业的细节,了解Sequential File stage(顺序文件阶段)和DataSet stage(数据集阶段)这两个重要的数据处理组件。然后,教程会演示如何编译作业,确保所有组件都正确无误。
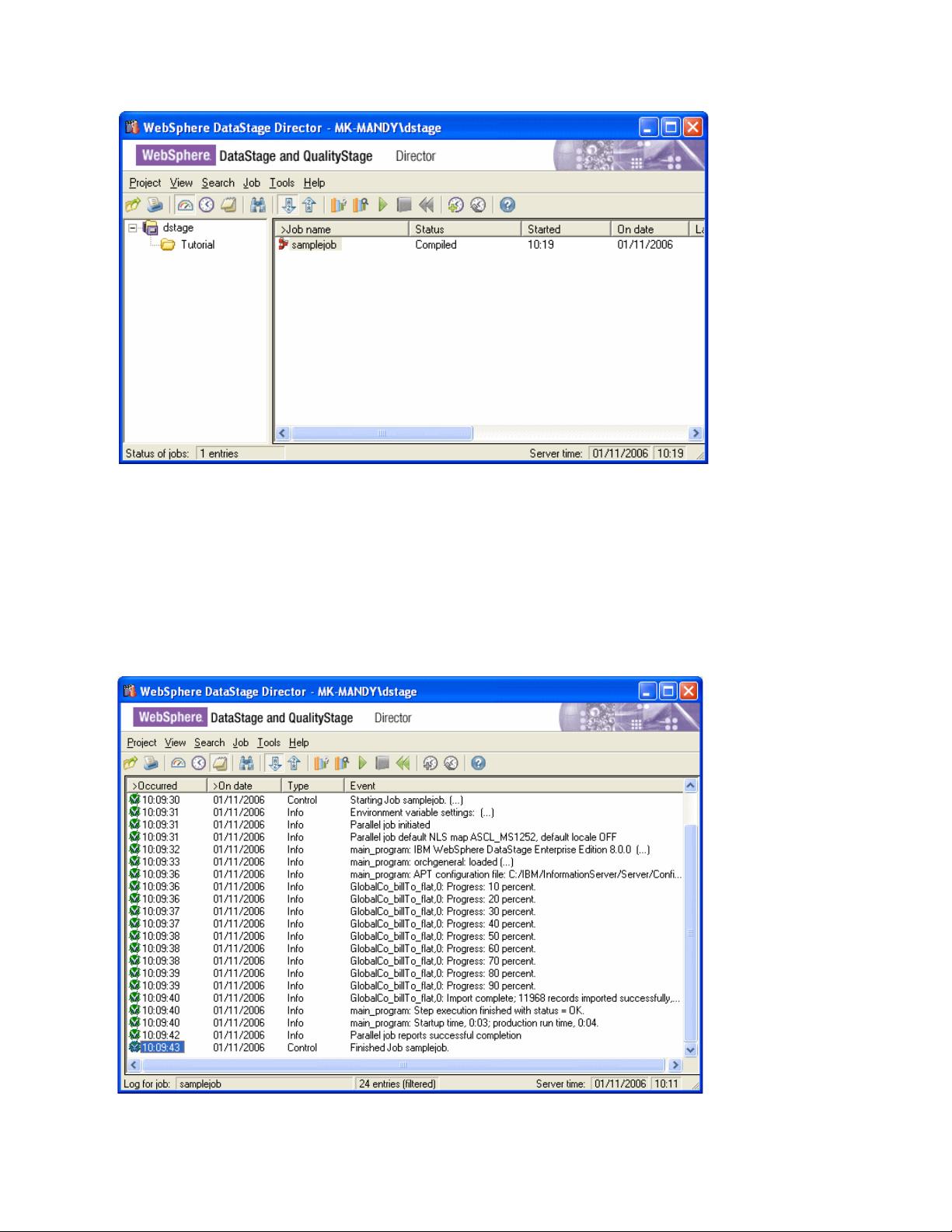
Lesson1.3:运行样本作业
最后,用户将学习如何执行作业,并查看运行结果。运行作业后,会讲解如何检查输出数据集,验证作业是否按预期工作。
每个课后都有一个“Lesson checkpoint”,这可能是对所学内容的小结,让用户确认他们已经掌握了这些基本技能。
通过这个教程,用户不仅能够熟悉DataStage8的工作环境,还能获得实际操作的经验,为进一步深入学习和应用DataStage8打下坚实的基础。教程后续章节可能会涉及更多高级主题,如错误处理、调度、性能优化以及与其他IBM WebSphere产品如Information Server的集成等。
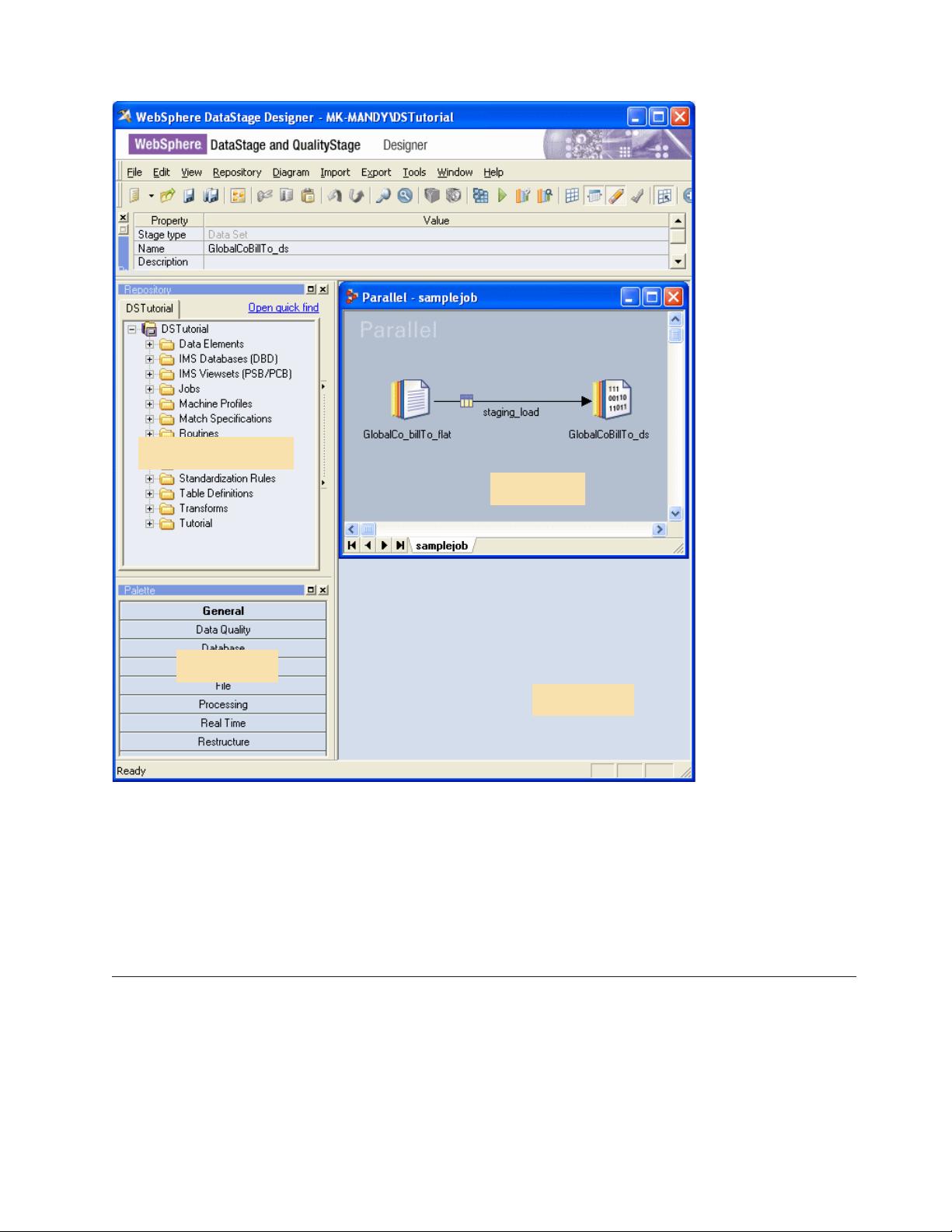
sample job
design area
repository tree
palette
Lesson checkpoint
In this lesson, you opened your first job.
You learned the following tasks:
v How to start the Designer client
v How to open a job
v Where to find the tutorial objects in the repository tree
Lesson 1.2: Viewing and compiling the sample job
In this lesson, you view the sample job to understand its components. You compile the job to prepare it
to run on your system.
The sample job has a Sequential File stage to read data from the flat file and a Data Set stage to write
data to the staging area. The two stages are joined by a link. The data that will flow between the two
stages on the link was defined when the job was designed. When the job is run, the data will flow down
this link.
Chapter 3. Module 1: Opening and running the sample job 7


剩余75页未读,继续阅读
2010-01-04 上传
2012-09-26 上传
2010-10-27 上传
405 浏览量
2012-06-14 上传
2010-04-23 上传
2019-04-19 上传
2011-02-25 上传
2011-02-25 上传

dulingqiang
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
