深度学习实践:多层感知器与感知器算法解析
需积分: 43 173 浏览量
更新于2024-07-17
收藏 2.02MB PPT 举报
"感知器算法介绍 - 深度学习实践应用中的多层感知器原理与实现"
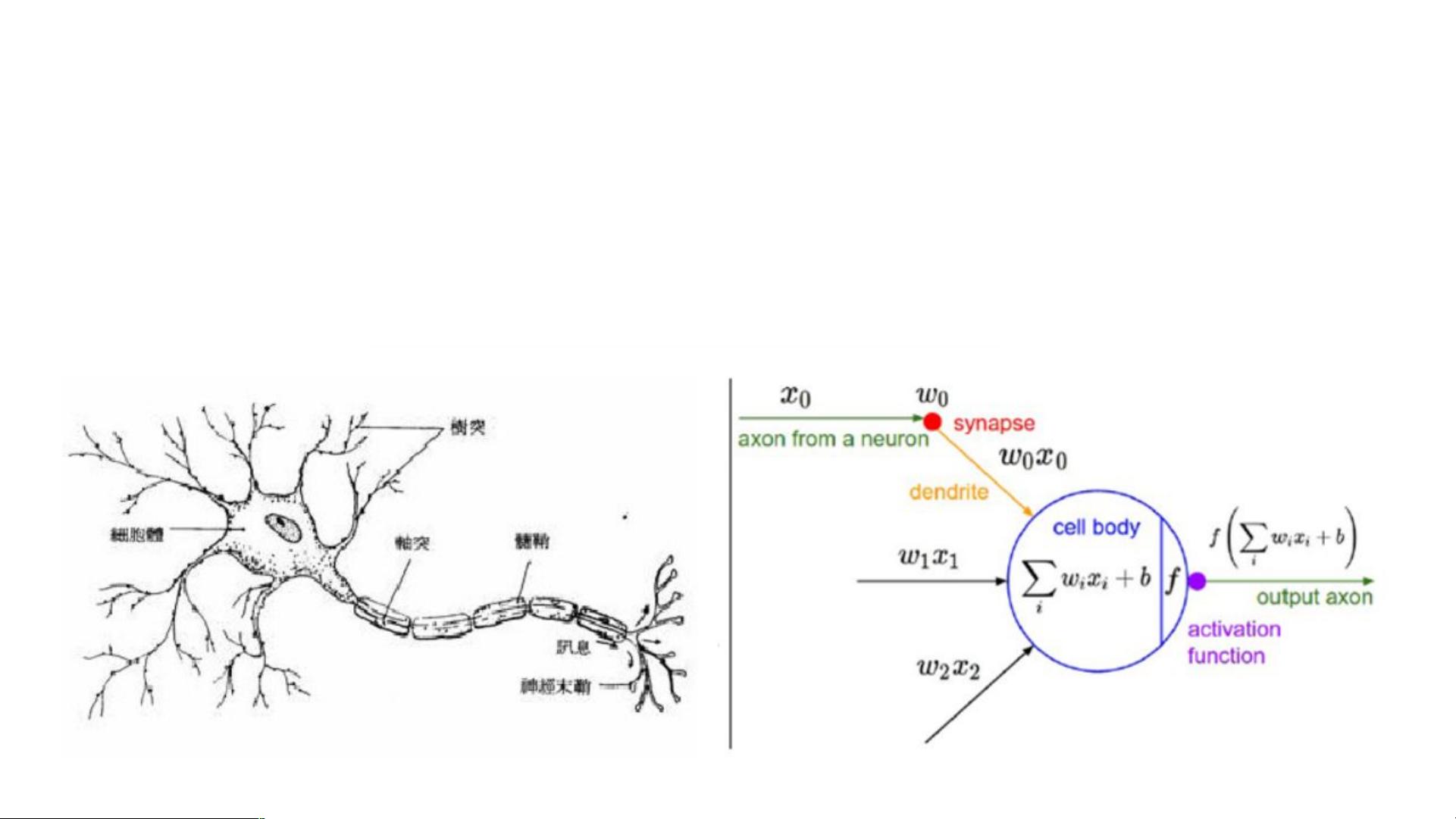
感知器算法是神经网络模型中最基础的一种,它主要用于二分类问题。该算法模仿了生物神经元的工作机制,可以接收来自环境的信息并根据权重进行信息传递。在机器学习领域,感知器被看作是线性可分问题的解决方案,它能够找到一个超平面,将数据集中的两类样本分开。
感知器分为单层和多层。单层感知器通常用于处理线性可分的问题,它由输入层和输出层组成,每个神经元都应用一个激活函数来决定输出。常见的激活函数包括阶跃函数、符号函数、S型函数和线性函数。近年来,随着深度学习的发展,ReLU(Rectified Linear Unit)及其变体成为更常用的激活函数,因为它们解决了梯度消失的问题,有助于模型的训练。
多层感知器(Multilayer Perceptrons, MLP)则进一步扩展了感知器的概念,通过在输入层和输出层之间加入一个或多个隐藏层,形成了一个前馈神经网络。这种结构使得模型能够学习更复杂的非线性关系,处理非线性可分的问题。在训练多层感知器时,通常采用反向传播算法进行权重更新。该算法包括以下步骤:
1. 初始化所有权重为随机值。
2. 对每个训练样本,从输入层到输出层前向传播计算,得到输出层的预测值。
3. 计算每个层的误差项,从输出层开始反向传播。
4. 根据误差项更新每个权重,如输出层的误差项和隐藏层的误差项。
5. 重复上述过程直到满足停止条件(例如达到预设的迭代次数或损失函数收敛)。
感知器功能上,单层感知器可以建立简单的决策边界,如二维平面上的一条直线。对于二维输入向量X=(x1, x2),感知器的决策边界由方程w1x1 + w2x2 - T = 0定义。而在三维或更高维度空间中,多层感知器可以形成更复杂的决策超面,处理高维数据的分类问题。
感知器算法是神经网络和深度学习的基础,为解决分类问题提供了初步的理论框架。随着技术的进步,多层感知器和其改进版本在许多实际应用中取得了显著的成功,如图像识别、自然语言处理等领域。理解并掌握感知器算法的原理和实现,对于深入学习深度学习模型至关重要。
感知器介绍
感知器介绍
人的视觉是重要的感观来源,人接受全部信息量的 80-85% 来源于视觉。
感知器是模拟人的视觉,接受环境信息,并由神经冲动进行信息传递的神经网络。
感知器分单层与多层,是具有学习能力的神经网络。
剩余18页未读,继续阅读
134 浏览量
2021-10-03 上传
2014-11-29 上传
2022-09-24 上传
2022-09-24 上传
106 浏览量
2018-11-25 上传

智享AI
- 粉丝: 150
- 资源: 30
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
