LDA模型详解:Gibbs抽样与Dirichlet分布在文本生成中的应用
下载需积分: 28 | PDF格式 | 4.26MB |
更新于2024-07-20
| 62 浏览量 | 举报
LDA(Latent Dirichlet Allocation)是一种常用的文本主题模型,用于发现文本数据中的潜在主题。在这个《LDA漫游指南》的第三、四章PDF中,主要探讨了LDA的Gibbs Sampling算法推导过程及其原理。章节开始于对词袋模型(Bag-of-Words)的介绍,这是一种简单的文本表示方法,不考虑单词在文档中的顺序,仅统计每个词的频率。
在第3章中,作者将文档生成过程比喻为上帝投掷一个有V个面的骰子,每个面代表一个词,其概率由词频决定。通过这种方式,可以计算出单个文档的概率。然而,LDA在此基础上引入了Dirichlet分布作为多项分布的先验,这是因为Dirichlet分布常用于处理多类别的概率分布,它的超参数α提供了对词频的不确定性建模。
具体来说,Dirichlet分布的似然函数与超参数α密切相关,公式(3.2)给出了这个关系。在贝叶斯框架下,由于我们对每个文档的主题分布(即骰子)没有先验知识,所以我们假设它们都来自一个Dirichlet分布的池子。利用贝叶斯公式,我们可以得到主题分布的后验分布,即每个文档中每个主题的概率分布,如公式(3.3)所示。
Gibbs Sampling作为一种迭代算法,用于在给定观测数据的情况下,估计隐藏变量(在这个例子中是主题分配)的分布。在第四章,作者可能详细讲解了如何通过Gibbs Sampling进行参数估计,包括如何通过迭代更新每个单词在每个主题上的归属概率,以及如何收敛到一个近似稳定的分布。
这部分内容深入介绍了LDA模型的构建思路,从基础的词袋模型扩展到带有Dirichlet先验的模型,强调了贝叶斯方法在主题模型中的应用,并重点讲述了如何通过Gibbs Sampling实现模型的估计和学习。这对于理解文本挖掘中主题模型的内在机制和技术细节非常关键。
2016/6/25 LDA漫游指南_电子书免费在线阅读_百度阅读
http://yuedu.baidu.com/ebook/d0b441a8ccbff121dd36839a?pn=1&rf=https%3A%2F%2Fwww.google.com.hk%2F 8/43
3.3马尔可夫链—>Metropolis-Hasting—>Gibbs
Sampling
在正式推导LDA的GibbsSampling采样公式之前,读者有必要了解为什么需
要这样推导,做到知其然知其所以然。
3.3.1马尔可夫链(markovchain)
马尔可夫链条通俗说就是根据一个转移概率矩阵去转移的随机过程(马尔可夫
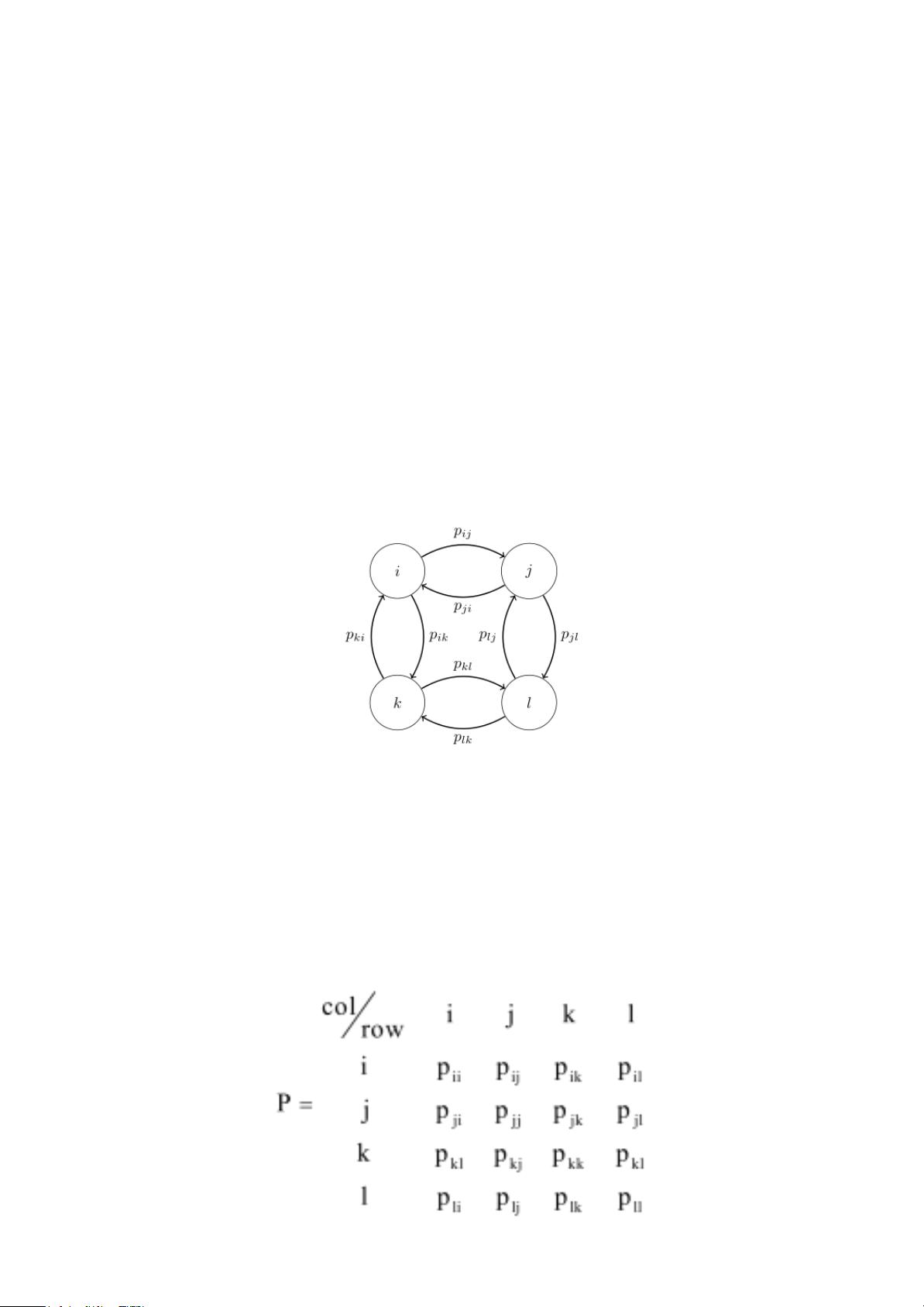
过程) ,该随机过程在PageRank算法中也有使用。如下图所示:
图 3.7 马尔可夫转移图
通俗理解:这里的每个圆环类似一个岛屿(状态),比如i到j的概率是p
ij
,每个节
点的出度概率之和=1。现在假设我要根据这个图去转移,那么首先需要把这张
图“翻译”成如下的矩阵:

剩余42页未读,继续阅读
相关推荐




151 浏览量


chenchengyu
- 粉丝: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++简单实现classloader及示例分析
- 快速掌握UICollectionView横向分页滑动封装技巧
- Symfony捆绑包CrawlerDetectBundle介绍:便于用户代理检测Bot和爬虫
- 阿里巴巴Android开发规范与建议深度解析
- MyEclipse 6 Java开发中文教程
- 开源Java数学表达式解析器MESP详解
- 非响应式图片展示模板及其源码与使用指南
- PNGoo:高保真PNG图像压缩新选择
- Android配置覆盖技巧及其源码解析
- Windows 7系统HP5200打印机驱动安装指南
- 电力负荷预测模型研究:Elman神经网络的应用
- VTK开发指南:深入技术、游戏与医学应用
- 免费获取5套Bootstrap后台模板下载资源
- Netgen Layouts: 无需编码构建复杂网页的高效方案
- JavaScript层叠柱状图统计实现与测试
- RocksmithToTab:将Rocksmith 2014歌曲高效导出至Guitar Pro
