CUDA C编程指南:版本8.0更新与性能调优
需积分: 9 176 浏览量
更新于2024-07-15
收藏 8.63MB PDF 举报
"CUDA_C_Programming_Guide 是NVIDIA官方发布的一份关于CUDA C编程的指南,主要针对CUDA C编程模型进行详细阐述,适用于CUDA计算能力为6.0、6.1和6.2的设备。该文档在7.5版本的基础上进行了更新,增加了对64位浮点原子操作的支持,添加了对计算能力6.x的设备的新特性描述,并对统一内存编程和性能调优等部分进行了更新和扩展。"
CUDA是NVIDIA开发的一种并行计算平台和编程模型,它允许程序员利用GPU(图形处理器)的强大计算能力来执行通用计算任务,而不仅仅是图形处理。CUDA C编程模型的核心是将计算任务分解为大量的独立线程,这些线程可以在GPU的并行处理核心上同时运行,极大地提升了计算效率。
在CUDA C编程模型中,**内核(Kernels)**是程序的主要执行单元,它们是由程序员定义的函数,可以在GPU上并行执行。内核通过`__global__`关键字声明,可以访问全局内存、共享内存、纹理内存和常量内存等不同类型的内存空间。
**线程组织**是CUDA编程的重要概念,包括线程块(Thread Blocks)和线程网格(Thread Grids)。线程块是一组线程,它们在GPU硬件中紧密相邻,可以进行高效的通信和同步。线程网格则由多个线程块组成,代表了内核执行的整体布局。
**内存层次**在CUDA中扮演关键角色,包括全局内存、共享内存、常量内存和纹理内存。全局内存是所有线程都可以访问的,但访问速度相对较慢;共享内存是线程块内的线程可以快速共享的数据区域;常量内存用于存储不会改变的全局数据;纹理内存提供优化的读取性能,适用于特定类型的数据访问模式。
**原子操作(Atomic Operations)**是CUDA中确保数据一致性的重要工具,比如原子加法(atomicAdd()),在计算能力6.x的设备上,支持了64位浮点数的原子操作。**受限制的原子操作(Scoped Atomics)**是针对计算能力6.x的设备新增的功能,提供了更精细的内存范围控制,增强了并发安全性。
**统一内存编程(Unified Memory Programming)**是CUDA的一个强大特性,它允许程序员在CPU和GPU之间透明地共享数据,无需显式地复制内存。在计算能力6.x的架构中,统一内存有了新的特性和行为,文档对此进行了详细说明。
此外,文档还包含了一个**性能调优(Performance Tuning)**的新章节,提供了关于如何最大限度地提高CUDA程序效率的指导和建议,包括但不限于内存访问模式优化、同步策略、计算效率提升等方面的内容。
CUDA C Programming Guide是学习和掌握CUDA编程不可或缺的参考资料,对于希望利用GPU进行高性能计算的开发者来说,这份文档详尽地介绍了CUDA编程的关键概念、工具和最佳实践。
Introduction
www.nvidia.com
CUDA C Programming Guide PG-02829-001_v8.0|2
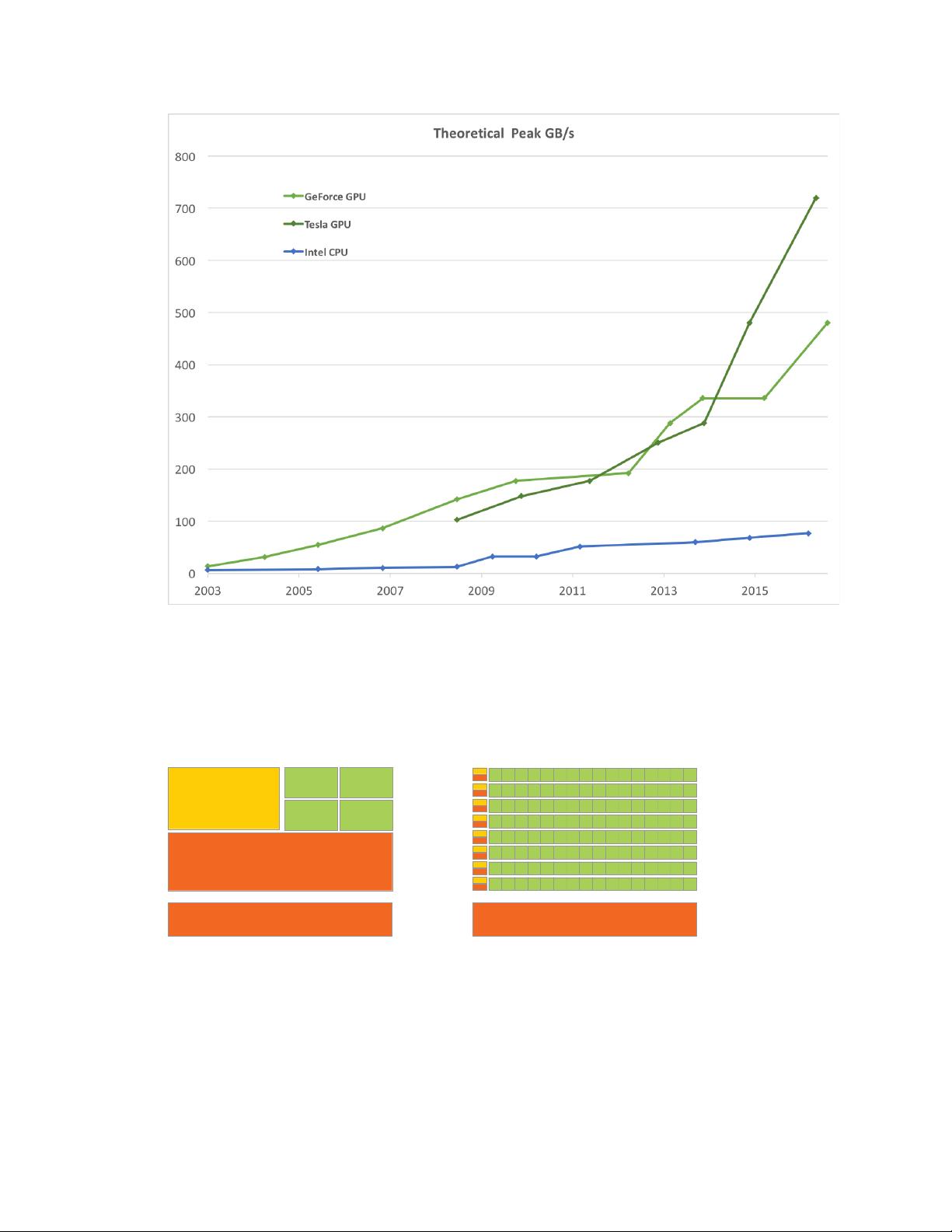
Figure2 Memory Bandwidth for the CPU and GPU
The reason behind the discrepancy in floating-point capability between the CPU and the
GPU is that the GPU is specialized for compute-intensive, highly parallel computation
- exactly what graphics rendering is about - and therefore designed such that more
transistors are devoted to data processing rather than data caching and flow control, as
schematically illustrated by Figure 3.
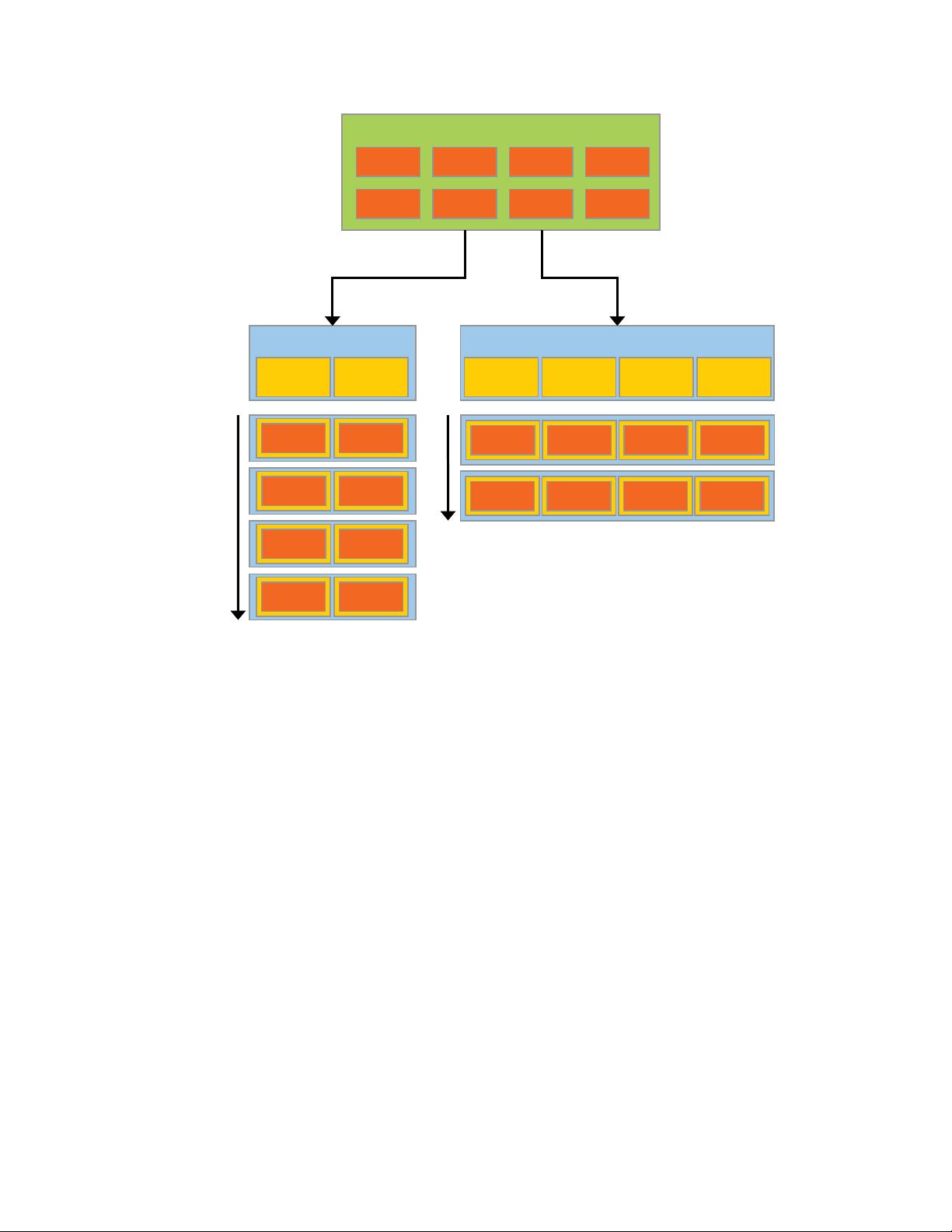
Cache
ALU
Cont rol
ALU
ALU
ALU
DRAM
CPU
DRAM
GPU
Figure3 The GPU Devotes More Transistors to Data Processing
More specifically, the GPU is especially well-suited to address problems that can be
expressed as data-parallel computations - the same program is executed on many data
elements in parallel - with high arithmetic intensity - the ratio of arithmetic operations
to memory operations. Because the same program is executed for each data element,



剩余279页未读,继续阅读
2020-05-20 上传
2019-03-29 上传
2015-12-23 上传
2012-01-06 上传
2018-03-28 上传
2011-05-24 上传
2012-03-20 上传
2015-11-25 上传
2015-11-16 上传

周小天..
- 粉丝: 92
- 资源: 18
 我的内容管理
展开
我的内容管理
展开







最新资源
- snake-js:带有Javascript和HTML5的Snake
- badges-and-schedules:熨斗学校实验室
- ArtCenterGame
- mywonkysounds:SoundManger 2 音板! 我的声音!
- birdinginvermont.com
- Usso:sso统一登录系统
- Design-Algorithm-Homework
- MonadicRP:GHC Haskell中的相对论编程
- monolithic-sample
- vue-shop:Vue + Element UI电商后台管理系统演示
- Neurotypical-mode:一种Chrome扩展程序,可关闭除Microsoft Stream或Manaba之外的所有选项卡
- observ-conference:实验
- module-blog-graph-ql:Magento 2 Blog GraphQL扩展。 为Magefan博客模块提供GraphQL端点
- Excel模板00现金日记账.zip
- Naive-Bayes-Classifier
- SmartFactory
