深度学习与浅层学习在文本分类的综述
需积分: 10 94 浏览量
更新于2024-07-08
2
收藏 16.45MB PPTX 举报
"这篇PPT是对文本分类领域的一次深入综述,涵盖了从浅层学习到深度学习的各种方法,由Qian Li, Hao Peng, Jianxin Li等人撰写,并在IEEETRANSACTIONSONNEURALNETWORKSANDLEARNINGSYSTEMS上发表于2020年10月。它不仅概述了文本分类的历史发展,还讨论了相关的数据集和评估指标,同时提出了未来的研究挑战和方向。"
在《文本分类综述——从浅层到深度学习》中,作者首先介绍了文本分类的基础概念,这是一个关键的自然语言处理任务,涉及将文本自动分配到预定义的类别中。该领域已有60年的研究历史,且随着机器学习和深度学习技术的进步,文本分类的方法也经历了显著的演变。
Partone部分,作者强调了这篇综述的独特之处在于全面回顾了从浅层学习到深度学习的所有现有模型。浅层学习通常依赖于人工设计的特征,如词袋模型或TF-IDF,这些特征用于构建分类器。这种方法对于特征工程有很高的要求,而深度学习则通过自动学习高级表示,如词嵌入和神经网络结构,减少了对特征工程的依赖。
Parttwo和Partthree详细阐述了浅层学习方法,包括传统统计模型(如朴素贝叶斯、支持向量机)和基于特征工程的机器学习算法。这些方法在特定任务上表现良好,但在处理复杂语义和上下文关系时可能受限。
Partfour和Partfive转向深度学习方法,如卷积神经网络(CNN)、循环神经网络(RNN)、长短时记忆网络(LSTM)和注意力机制。这些模型能够捕获文本的序列性和上下文信息,尤其在大规模数据集上展现出强大的性能。
Partsix部分,作者讨论了用于文本分类的典型数据集,如20新闻组、IMDb电影评论等,以及常用的评估指标,如准确率、精确率、召回率和F1分数。这些数据集和指标是衡量模型性能的关键工具。
最后,文章提出了未来研究的挑战,包括泛化能力、计算效率、模型解释性以及如何处理多语言和低资源语言的文本分类问题。作者鼓励研究者探索新的模型架构、优化算法和预训练技术,以推动文本分类领域的进一步发展。
这篇综述为读者提供了一个全面的框架,帮助理解文本分类的不同层面,从传统的统计方法到现代的深度学习技术,对于研究人员和实践者来说是一份宝贵的参考资料。
1
Introduction
Part one
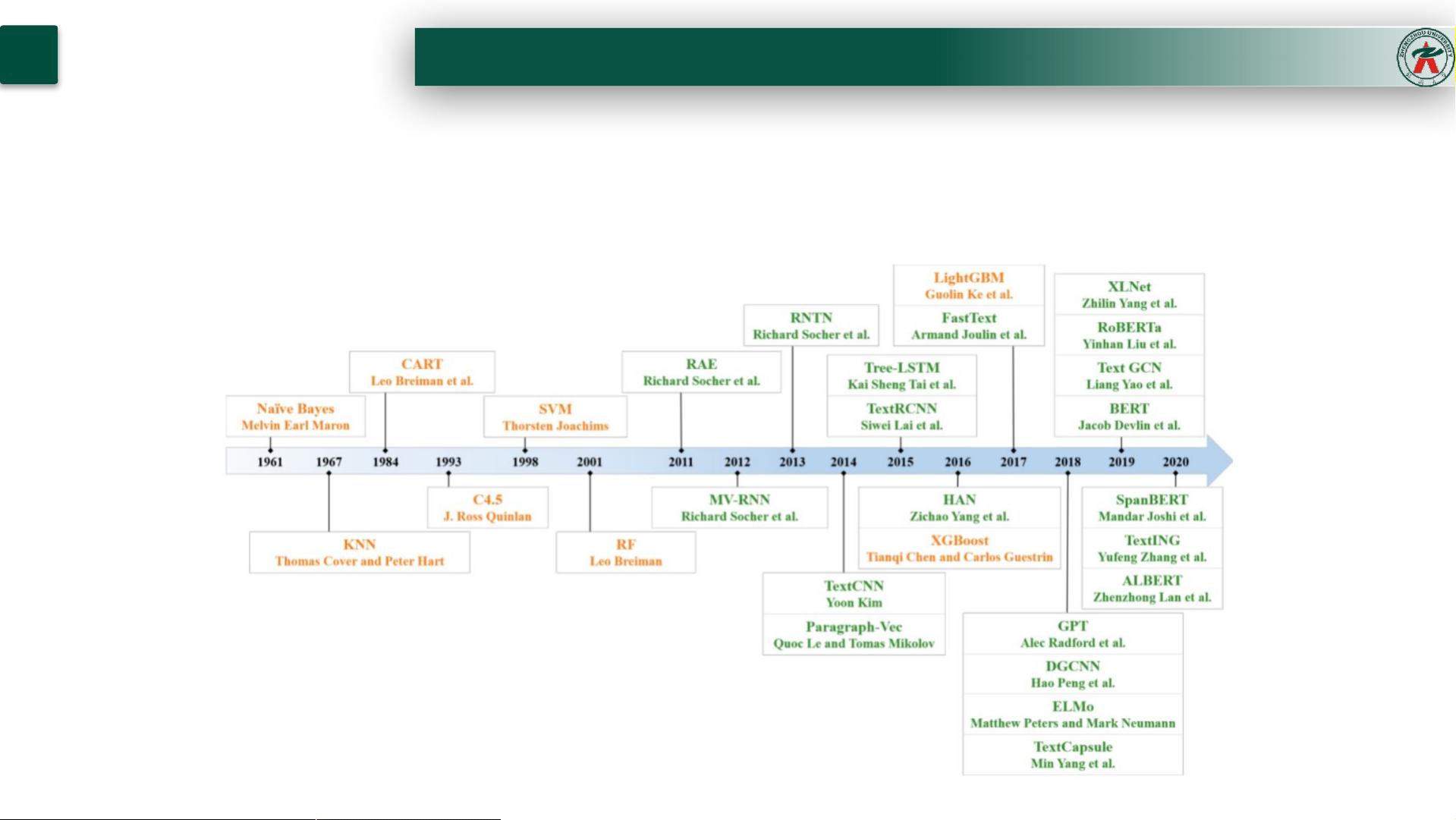
从 1960 年代到 2010 年代,基于浅层学习的文本分类模型占主导地位。自 2010 年代以来,文本分
类已逐渐从浅层学习模型变为深层学习模型。
文本分类发展历史

剩余43页未读,继续阅读
2021-10-05 上传
651 浏览量
2025-01-06 上传
2025-01-06 上传

Suprit
- 粉丝: 472
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- 作品答辩PPT优质模版.rar
- portfolio-website
- Rcam2:配备LiDAR传感器的iPad Pro远程深度相机
- Nativescript-Template:具有Sidedrawer和Tabview的现代Nativescript-Angular模板
- z-toolz:用于NodeJS开发的工具
- 易语言2D音效
- KOMenuView:简单的可折叠底部菜单
- 【Vue2 + ElementUI】分页el-pagination 封装成公用组件
- zeroexchange-开源
- 无参考代码_无参考图像质量评价_
- sbrunwas.github.io
- nativescript-razorpay:用于nativescript的非官方razorpay插件
- 阅读笔记:读书笔记心得
- MPR New Tab-crx插件
- three-js-meteor:三个带有 Meteor 的 js 动画。 看第四个动画
- mochawesome-report-generator:独立的Mochawesome报告生成器。 只需添加测试数据
