HDFS NameNode内存管理深度解析:挑战与优化策略
187 浏览量
更新于2024-08-31
收藏 1.02MB PDF 举报
"HDFSNameNode内存详解"
在Hadoop分布式文件系统(HDFS)中,NameNode是核心组件,负责管理文件系统的元数据。NameNode的内存管理是系统性能的关键因素,因为它必须在内存中存储大量的文件系统状态信息。本文深入探讨了NameNode的内存使用情况,特别是面对数据规模增长时的挑战。
首先,NameNode内存的主要组成部分之一是`NetworkTopology`。这个模块用于构建集群的机架拓扑,以便高效地调度数据传输。每个DataNode由`DatanodeDescriptor`对象表示,这些对象包含了关于DataNode的信息,如存储介质类型。`DatanodeDescriptor`的内存消耗主要来自存储介质集合`storageMap`,其中包含了`DatanodeStorageInfo`对象,这些对象描述了DataNode上的各个存储单元的详细信息。
对于内存调整,NameNode需要解决三个关键问题:1)预测当前内存可以支撑多久;2)确定何时应扩大堆空间以适应数据增长;3)决定应该增加多少堆空间。然而,无限制地增加内存并不是解决之道,因为过大的堆空间可能导致更长的重启时间,以及更频繁的Full Garbage Collection (FGC),这可能会对系统稳定性产生负面影响。
为了优化内存使用,需要对NameNode的核心数据结构进行详细的定量分析。例如,通过对`DatanodeDescriptor`和`DatanodeStorageInfo`的内存使用情况深入理解,可以更准确地估算内存需求。这有助于提前规划内存资源,避免不必要的性能瓶颈,并且可以根据分析结果优化集群的存储资源分配。
内存预估模型是解决这个问题的有效工具。通过建立这样的模型,可以预测随着数据规模的增长,NameNode需要多少内存,从而可以提前调整硬件配置,保证系统的稳定运行。这种预估模型的构建依赖于对NameNode内部数据结构的深入理解和实际工作负载的特征。
HDFSNameNode的内存管理是一个复杂而关键的任务,涉及到对数据结构的深入理解,内存使用量的精确估算,以及对系统性能影响的全面考虑。通过对NameNode内存使用的细致分析和合理规划,可以确保HDFS在大规模数据环境下保持高效和稳定。
HDFSNameNode内存详解内存详解
前言
《HDFS NameNode内存全景》中,我们从NameNode内部数据结构的视角,对它的内存全景及几个关键数据结构进行了简
单解读,并结合实际场景介绍了NameNode可能遇到的问题,还有业界进行横向扩展方面的多种可借鉴解决方案。
事实上,对NameNode实施横向扩展前,会面临常驻内存随数据规模持续增长的情况,为此需要经历不断调整NameNode内
存的堆空间大小的过程,期间会遇到几个问题:
1.当前内存空间预期能够支撑多长时间。
2.何时调整堆空间以应对数据规模增长。
3.增加多大堆空间。
另一方面NameNode堆空间又不能无止境增加,到达阈值后(与机型、JVM版本、GC策略等相关)同样会存在潜在问题:
1.重启时间变长。
2.潜在的FGC风险
由此可见,对NameNode内存使用情况的细粒度掌控,可以为优化内存使用或调整内存大小提供更好的决策支持。
本文在前篇《HDFS NameNode内存全景》文章的基础上,针对前面的几个问题,进一步对NameNode核心数据结构的内存
使用情况进行详细定量分析,并给出可供参考的内存预估模型。根据分析结果可有针对的优化集群存储资源使用模式,同时利
用内存预估模型,可以提前对内存资源进行合理规划,为HDFS的发展提供数据参考依据。
内存分析
NetworkTopology
NameNode通过NetworkTopology维护整个集群的树状拓扑结构,当集群启动过程中,通过机架感知(通常都是外部脚本计
算)逐渐建立起整个集群的机架拓扑结构,一般在NameNode的生命周期内不会发生大变化。拓扑结构的叶子节点
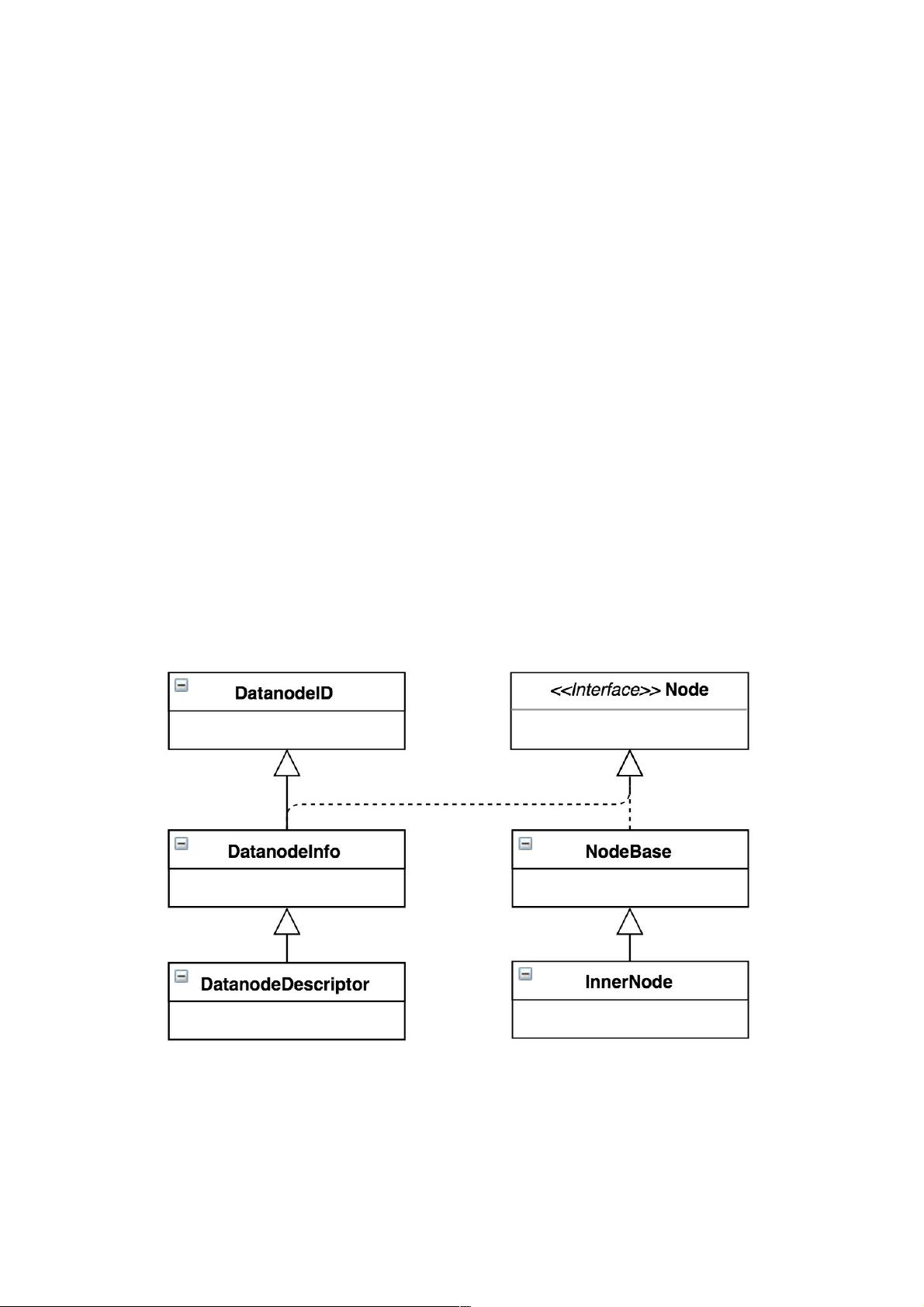
DatanodeDescriptor是标识DataNode的关键结构,该类继承关系如图1所示。
图1 DatanodeDescriptor继承关系
在64位JVM中,DatanodeDescriptor内存使用情况如图2所示(除特殊说明外,后续对其它数据结构的内存使用情况分析均基
于64位JVM)。
下载后可阅读完整内容,剩余5页未读,立即下载
1025 浏览量
2571 浏览量
1808 浏览量
300 浏览量
5676 浏览量
2565 浏览量
2653 浏览量
1194 浏览量
903 浏览量

weixin_38545117
- 粉丝: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- Premiere Pro CS6视频编辑项目教程微课版教案
- SSM+Lucene+Redis搜索引擎缓存实例解析
- 全栈打字稿应用:演示项目实践与探索
- 仿Windows风格的AJAX无限级树形菜单实现教程
- 乐华2025L驱动板通用升级解决方案
- Java通过jcraft实现SFTP文件上传下载教程
- TTT素材-制造1资源包介绍与记录
- 深入C语言编程技巧与实践指南
- Oracle数据自动导出并转换为Excel工具使用教程
- Ubuntu下Deepin-Wine容器的使用与管理
- C语言网络聊天室功能详解:禁言、踢人与群聊
- AndriodSituationClick事件:详解按钮点击响应机制
- 探索Android-NetworkCue库:高效的网络监听解决方案
- 电子通信毕业设计:简易电感线圈制作方法
- 兼容性数据库Compat DB 4.2.52-5.1版本发布
- Android平台部署GNU Linux的新方案:dogeland体验
