能耗数据库设计详解:架构与分类
37 浏览量
更新于2024-06-23
收藏 570KB DOC 举报
能耗数据库设计是一个关键的IT项目,旨在构建一个结构化的数据存储系统来管理建筑物和数据中心的能耗数据。该数据库设计包含多个核心表,每个表都代表了数据的不同方面,以确保信息的有效组织和分析。
1. 数据表与字段前缀:
- T_**: 表示表格(Table),用于标识数据库中的各个实体。
- F_**: 表示字段(Field),用来描述数据表中的具体属性。
主要表包括:
- T_DC_**: 数据中心(DataCenter)表,用于记录数据中心的基本信息,如ID、名称等。
- T_BD_**: 建筑(Building)表,记录建筑物的详细数据,包括类别、编码等。
- T_DT_**: 字典(Dictionary)表,用于存储分类和子项目的定义,例如建筑类别表(T_DT_BuildingType)和能耗分类表(T_DT_EnergyType)。
- T_EC_**: 能耗(EnergyConsumption)表,追踪具体的能耗数据,如能耗类型、分项等。
- T_ST_**: 设计安装(Setting)表,可能涉及设备设置或安装参数信息。
- T_OV_**: 原始值(OriginalValue)表,保存初始状态的数据。
- T_IV_**: 增量值(IncreaseValue)表,记录数据的变化情况。
2. 基本字典表:
- **T_DT_BuildingType**: 包含了不同类型的建筑,如办公、商场、宾馆饭店等,通过BuildingTypeID作为主键,保证唯一性。
- **T_DT_EnergyType**: 详细列出各种能源类型,如电、水、燃气、集中供热量等,每种类型都有一个唯一的EnergyTypeID。
3. 能耗分项表(T_DT_EnergySubItem):
这个表详细列举了能耗的子项目,如电力消耗的各个部分,通过EnergyItemID作为主键。这样的设计有助于细致地跟踪和分析能耗数据。
在设计过程中,这些表格的关联性和数据完整性至关重要。通过这些表格,我们可以建立一套全面的能耗管理系统,不仅便于数据的输入、查询和更新,还能支持数据分析和报告生成,帮助决策者做出更科学的节能减排措施。此外,数据库设计时还需要考虑性能优化、数据安全以及数据备份等问题,以确保系统的稳定运行和长期维护。
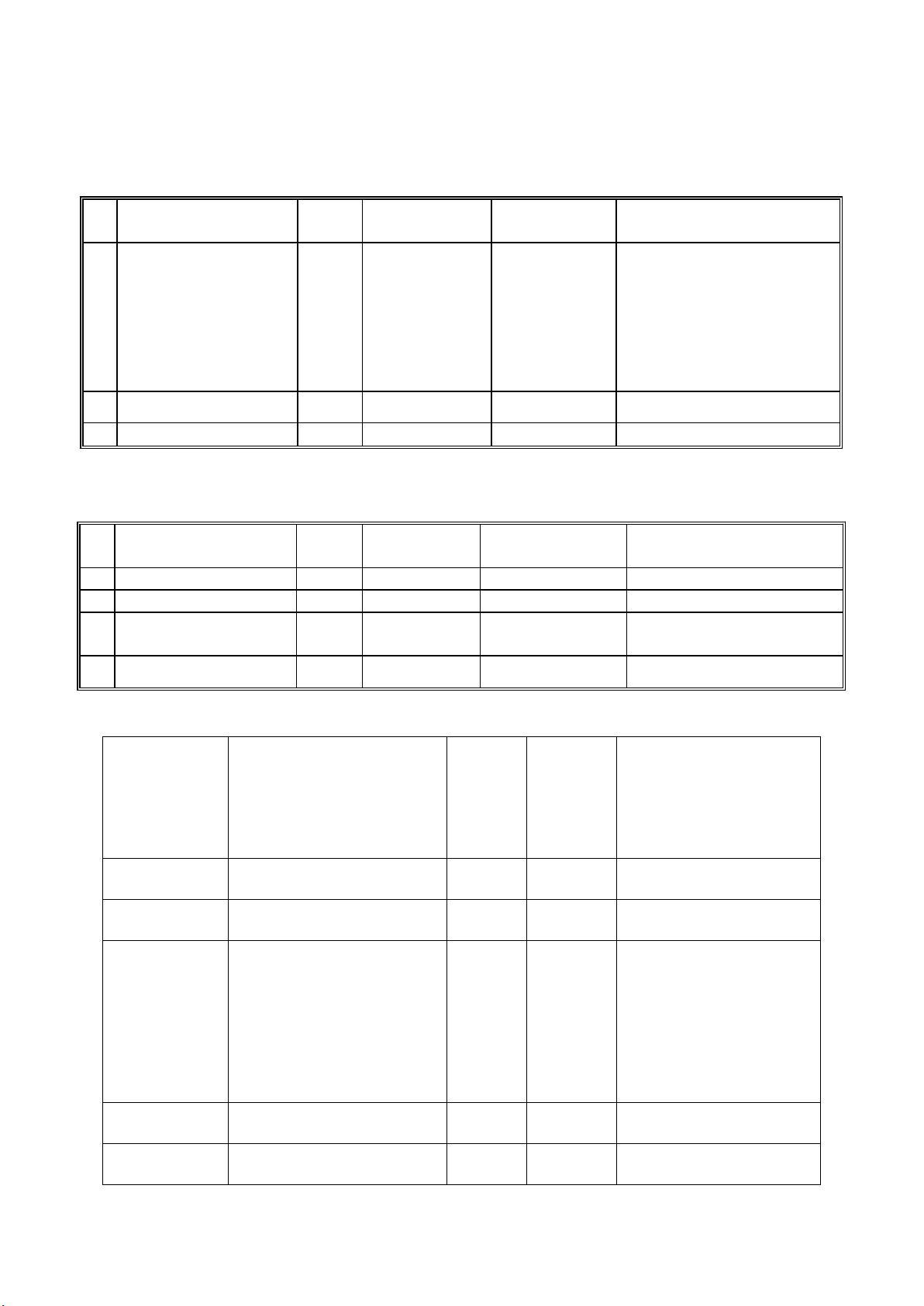
2.4 仪表类型信息表 T_DT_MeterType
序
号
字段名
主、外
键
字段中文名
推荐数据类型
描述
1
MeterTypeCode
主键
仪表类型编码
Varchar(2)
A- 普通电表
B- 多功能电表
C- 水表
D- 燃气表
E- 热表
F- 冷表
G- 冷热量计
2
MeterTypeName
仪表类型名称
Varchar(48)
3
MeterTypeDesc
仪表类型描述
2.5 能耗单位折算煤炭转换参数表 T_DT_EnergyRateToCoal
序
号
字段名
主、外
键
字段中文名
推荐数据类型
描述
1
EnergyRateID
主键
折算比率 ID
Int
IDENTITY(1,1)
2
EnergyTypeCode
能耗分类编码
Char(2)
3
ChangeRate
必填
转换比率
Numeric(18,4)
参数单位转换至标准单位的
比率
4
分类能耗代码
分类能耗名称
能耗类
型
分类、分项
能耗数值
单位
换算公式
(千克标准煤)
01
电
A
千瓦时
0.1229
02
水
A
吨
无
03
管道燃气
A
立方米
1.2143(天然气)
0.5714~0.6143(焦炉
煤气)
0.3570(其它煤气)
04
集中供热量
A
兆焦
1.229
05
集中供冷量
A
兆焦
1.229
剩余18页未读,继续阅读
2023-01-08 上传
2023-01-08 上传
2024-06-30 上传
2022-11-30 上传
2022-07-14 上传
2021-10-12 上传
2021-04-06 上传
2022-04-10 上传

Mmnnnbb123
- 粉丝: 748
- 资源: 8万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
