深度学习驱动的监督语音分离技术概览
需积分: 50 197 浏览量
更新于2024-07-15
收藏 2.28MB PDF 举报
"这篇论文提供了一个深度学习驱动的监督语音分离技术的全面综述,重点关注近年来的研究进展。文章深入探讨了语音分离的背景、监督分离的构建,以及学习机器、训练目标和声学特征等关键要素。此外,还详细阐述了单声道和多麦克风方法在语音增强、说话者分离和语音混响处理中的应用。"
近年来,随着人工智能领域的快速发展,特别是深度学习的兴起,语音分离技术得到了显著提升。传统上,语音分离被视为一个信号处理问题,而如今,它被重新定义为一个监督学习任务。在这个框架下,模型通过训练数据学习语音、说话者和背景噪声的区分性模式。
监督学习在语音分离中的应用已经成为研究热点,过去十年间涌现了许多相关算法。深度学习的引入尤其对这一领域产生了深远影响,它能够处理复杂的非线性关系,提高模型对不同环境噪声和多说话者的适应能力。深度神经网络(DNN)、卷积神经网络(CNN)和循环神经网络(RNN)等模型已被广泛应用于语音特征提取和分离目标的识别。
论文详细回顾了单声道方法,其中包括语音增强技术,其主要目标是区分语音和非语音信号,消除噪声干扰。此外,说话者分离,即多说话者同时讲话时的语音分离,也是一个重要的研究方向。这通常涉及说话者识别和跟踪技术,以确保正确分离来自不同源的声音。
同时,论文也讨论了语音混响处理,这是实际环境中常见的问题,因为声音往往会因为空间反射产生回声。多麦克风技术在这里发挥了关键作用,通过阵列信号处理和空间谱估计方法,可以利用多个麦克风的相对时间差和强度信息来改善分离效果。
监督学习面临的挑战之一是泛化能力,即模型能否在未见过的数据上表现良好。论文中会讨论如何通过更大的训练数据集、数据增强策略和模型正则化来提高模型的泛化性能。
这篇综述性文章对深度学习驱动的监督语音分离技术进行了详尽的分析,涵盖了从基本概念到最新进展的各个方面,对于理解这一领域的研究现状和未来趋势具有重要价值。
2329-9290 (c) 2018 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TASLP.2018.2842159, IEEE/ACM
Transactions on Audio, Speech, and Language Processing
IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. X, NO. X, XXX XXXX
6
in Fig. 2(c).
D. Spectral Magnitude Mask
The spectral magnitude mask (SMM) (called FFT-MASK
in [178]) is defined on the STFT (short-time Fourier
transform) magnitudes of clean speech and noisy speech:
(3)
where
and
represent spectral magnitudes of
clean speech and noisy speech, respectively. Unlike the IRM,
the SMM is not upper-bounded by 1. To obtain separated
speech, we apply the SMM or its estimate to the spectral
magnitudes of noisy speech, and resynthesize separated
speech with the phases of noisy speech (or an estimate of
clean speech phases). Fig. 2(e) illustrates the SMM.
E. Phase-Sensitive Mask
The phase-sensitive mask (PSM) extends the SMM by
including a measure of phase [41]:
(4)
where denotes the difference of the clean speech phase and
the noisy speech phase with the T-F unit. The inclusion of the
phase difference in the PSM leads to a higher SNR, and tends
to yield a better estimate of clean speech than the SMM [41].
An example of the PSM is shown in Fig. 2(f).
F. Complex Ideal Ratio Mask
The complex ideal ratio mask (cIRM) is an ideal mask in
the complex domain. Unlike the aforementioned masks, it can
perfectly reconstruct clean speech from noisy speech [188]:
(5)
where , denote the STFT of clean speech and noisy speech,
respectively, and ‘ ’ represents complex multiplication.
Solving for mask components results in the following
definition:
(6)
where
and
denote real and imaginary components of
noisy speech, respectively, and
and
real and imaginary
components of clean speech, respectively. The imaginary unit
is denoted by ‘i’. Thus the cIRM has a real component and an
imaginary component, which can be separately estimated in
the real domain. Because of complex-domain calculations,
mask values become unbounded. So some form of
compression should be used to bound mask values, such as a
tangent hyperbolic or sigmoidal function [188] [184] .
Williamson et al. [188] observe that, in Cartesian
coordinates, structure exists in both real and imaginary
components of the cIRM, whereas in polar coordinates,
structure exists in the magnitude spectrogram but not phase
spectrogram. Without clear structure, direct phase estimation
would be intractable through supervised learning, although we
should mention a recent paper that uses complex-domain
DNN to estimate complex STFT coefficients [107]. On the
other hand, an estimate of the cIRM provides a phase estimate,
a property not possessed by PSM estimation.
G. Target Magnitude Spectrum
The target magnitude spectrum (TMS) of clean speech, or
, is a mapping-based training target [116] [196] [57]
[197]. In this case supervised learning aims to estimate the
magnitude spectrogram of clean speech from that of noisy
speech. Power spectrum, or other forms of spectra such as mel
spectrum, may be used instead of magnitude spectrum, and a
log operation is usually applied to compress the dynamic
range and facilitate training. A prominent form of the TMS is
the log-power spectrum normalized to zero mean and unit
variance [197]. An estimated speech magnitude is then
combined with noisy phase to produce the separated speech
waveform. In terms of cost function, MSE is usually used for
TMS estimation. Alternatively, maximum likelihood can be
employed to train a TMS estimator that explicitly models
output correlation [175]. Fig. 2(g) shows an example of the
TMS.
H. Gammatone Frequency Target Power Spectrum
Another closely related mapping-based target is the
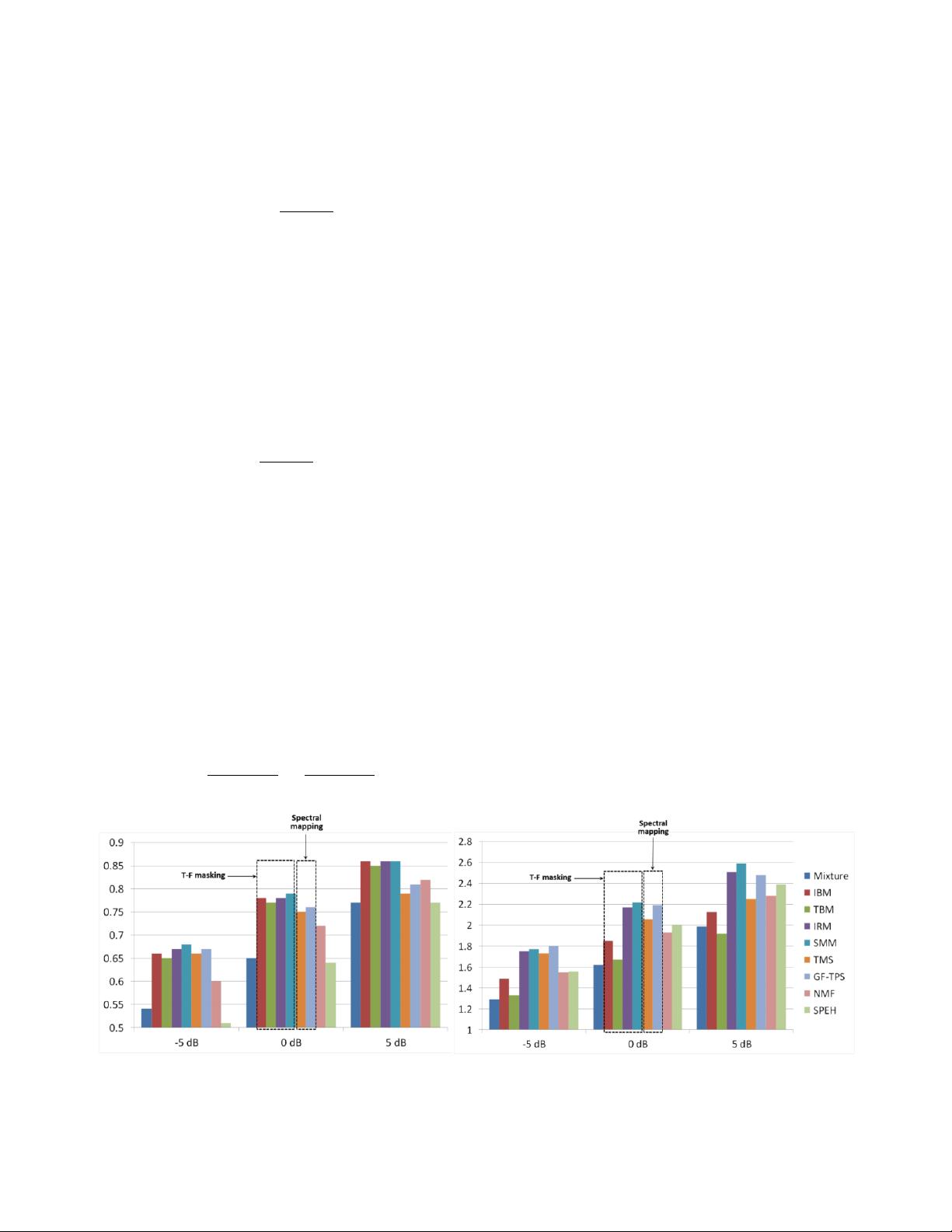
(a) STOI results (b) PESQ results
Figure 3. Comparison of training targets. (a) In terms of STOI. (b) In terms of PESQ. Clean speech is mixed with a factory noise at
-5 dB, 0 dB and 5 dB SNR. Results for different training targets as well as a speech enhancement (SPEH) algorithm and an NMF
method are highlighted for 0 dB mixtures. Note that the results and the data in this figure can be obtained from a Matlab toolbox at
http://web.cse.ohio-state.edu/pnl/DNN_toolbox/.
剩余27页未读,继续阅读
2018-03-17 上传
267 浏览量
2021-02-10 上传
157 浏览量
435 浏览量
2021-03-25 上传
2021-04-03 上传
241 浏览量
295 浏览量

林深迷了鹿
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全面详实的大学生电工实习报告汇总
- 利用极光推送实现App间的消息传递
- 基于JavaScript的节点天气网站开发教程
- 三星贴片机1+1SMT制程方案详细介绍
- PCA与SVM结合的机器学习分类方法
- 钱能版C++课后习题完整答案解析
- 拼音检索ListView:实现快速拼音排序功能
- 手机mp3音量提升神器:mp3Trim使用指南
- 《自动控制原理第二版》习题答案解析
- 广西移动数据库脚本文件详解
- 谭浩强C语言与C++教材PDF版下载
- 汽车电器及电子技术实验操作手册下载
- 2008通信定额概预算教程:快速入门指南
- 流行的表情打分评论特效:实现QQ风格互动
- 使用Winform实现GDI+图像处理与鼠标交互
- Python环境配置教程:安装Tkinter和TTk
