数据平台的多元组成与扩展策略:探索规模要素
86 浏览量
更新于2024-07-15
收藏 1.85MB PDF 举报
规模要素:数据平台的组成和扩展
在IT行业中,数据平台的发展与演进反映了软件工程师在处理数据时对效率和性能的追求。过去十多年间,随着技术的进步和开源项目的兴起,数据平台的构成和扩展方式发生了深刻的变化。这些平台不再依赖单一工具,而是整合了多种组件,以适应不同场景下的需求。
基础的构成元素包括:
1. 缓存层:这是提高数据访问速度的关键部分,无论是内存级别的缓存(如CPU缓存、页缓存)还是分布式缓存(如Redis或Memcached),都旨在减少从底层存储设备(如硬盘)获取数据的延迟,实现局部性原则,即数据访问的顺序性和一致性。
2. 多语言持久化层:支持多种数据库引擎,如SQL(MySQL、PostgreSQL)、NoSQL(MongoDB、Cassandra)、甚至是键值对存储(如Riak、Etcd),以满足对不同数据模型和查询需求的支持。
3. 整合数据管道:完整的数据处理链路,涵盖了数据采集、清洗、转换、存储和分析等环节,可能包括ETL(提取、转换、加载)工具和实时流处理框架(如Apache Kafka、Flink或Spark Streaming)。
4. 针对特定需求的解决方案:为了满足特定业务场景,如高性能计算、大数据处理、机器学习等,平台提供了专门优化的组件,如Hadoop HDFS、Spark、TensorFlow等。
这些组件的选择和配置需要根据应用场景的特性进行,例如,对于实时性要求高的系统,可能会优先选择内存密集型的缓存和流处理技术;而对于需要长期存储和复杂查询的场景,则会选择更全面的数据库解决方案。
然而,数据平台的设计并非孤立,它必须考虑到内存和磁盘之间的性能差距,以及随机访问和顺序访问的不同影响。例如,固态硬盘(SSD)的出现改变了传统硬盘的性能瓶颈,尤其是采用高速PCIe接口的SSD,使得有序数据访问性能得到显著提升,尽管随机访问性能可能不如内存。
在创建数据库时,设计者需要平衡读写性能、数据一致性、可扩展性等因素,并可能引入层次化的数据存储策略,比如使用文件系统(如Hadoop HDFS)配合数据库系统,以适应不同的读写模式。
数据平台的规模要素包括了对硬件特性的理解、对数据访问模式的优化、以及对多语言和技术栈的集成。随着技术的不断发展,数据平台的组成和扩展将继续演化,以适应日益增长的数据处理需求和复杂性。
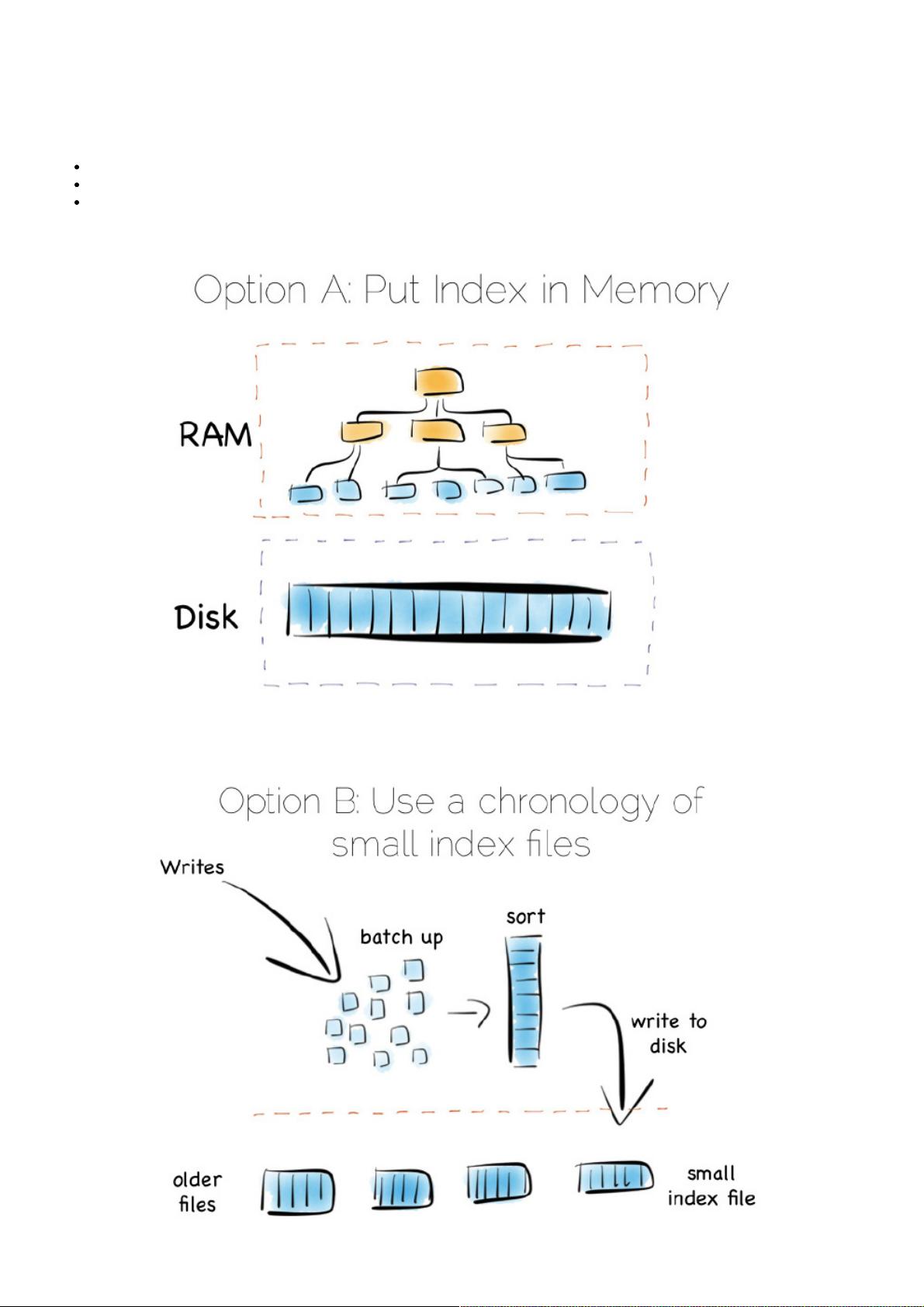
整性,速度大约慢1000倍。
幸运的是,这里有几种解决方案。这里我们讨论三种,它们都是一些极端地例子。在现实世界中,远没有这么复杂,但在考虑
海量存储时这些概念会特别有用。
译者加:
第一种内存映射文件
第二种较小的索引集合,采用元索引或者布隆过滤算法(Bloom Filter)做一些优化
第三种简单匹配算法(brute force)又叫面向列(Column Oriented)
第一种方案是将索引放入主内存,随机写问题分隔到随机存储存储器(RAM),堆文件依旧在硬盘中。
剩余20页未读,继续阅读
2019-08-30 上传
2024-04-18 上传
2024-03-01 上传
2023-06-09 上传
2023-06-09 上传
2024-05-22 上传
2023-06-11 上传
2023-09-03 上传
2023-05-29 上传

weixin_38569722
- 粉丝: 1
- 资源: 924
 我的内容管理
展开
我的内容管理
展开







最新资源
- Postman安装与功能详解:适用于API测试与HTTP请求
- Dart打造简易Web服务器教程:simple-server-dart
- FFmpeg 4.4 快速搭建与环境变量配置教程
- 牛顿井在围棋中的应用:利用牛顿多项式求根技术
- SpringBoot结合MySQL实现MQTT消息持久化教程
- C语言实现水仙花数输出方法详解
- Avatar_Utils库1.0.10版本发布,Python开发者必备工具
- Python爬虫实现漫画榜单数据处理与可视化分析
- 解压缩教材程序文件的正确方法
- 快速搭建Spring Boot Web项目实战指南
- Avatar Utils 1.8.1 工具包的安装与使用指南
- GatewayWorker扩展包压缩文件的下载与使用指南
- 实现饮食目标的开源Visual Basic编码程序
- 打造个性化O'RLY动物封面生成器
- Avatar_Utils库打包文件安装与使用指南
- Python端口扫描工具的设计与实现要点解析
