揭秘SparkTask执行流程:ResultTask与ShuffleMapTask详解
需积分: 0 197 浏览量
更新于2024-08-04
收藏 673KB DOCX 举报
SparkTask的执行流程是Spark分布式计算的核心组成部分,它确保了任务在集群中的高效并行执行。在这个流程中,TaskRunner对象作为Runnable的实例,扮演着关键角色,它的run()方法是理解任务执行机制的关键所在。TaskRunner被提交到Executor的线程池,这个线程池负责执行来自Driver程序的任务。
首先,Task的类型分为两种:ResultTask和ShuffleMapTask。ResultTask通常出现在DAG图的最后阶段,对应于图中的最后一个RDD,其数量等于该RDD的分区数。而ShuffleMapTask则用于非最后阶段的Stage,数量与该Stage最后一RDD的分区数相同。这些任务的区别在于,ResultTask负责对RDD进行聚合操作,如计数或取前n条数据,而ShuffleMapTask负责map操作,并可能涉及数据的局部性shuffle。
在Task#run()方法中,最重要的部分是调用Task#runTask(context: TaskContext),这个方法的实现根据Task的类型有所不同。对于ResultTask,它会反序列化相应的RDD(即数据集)和一个预定义的函数func。func函数根据RDD Action(如count、take等)的不同,执行特定的操作,例如计算迭代器中的数据条数或者获取指定数量的元素。
例如,当执行RDD#count()操作时,func实际上是`def getIteratorSize[T](iterator: Iterator[T]): Long`,它会计算给定分区的迭代器中的数据量。而对于RDD#take(num: Int): Array[T],func则是`(it: Iterator[T]) => it.take(num).toArray`,它从迭代器中提取前n个元素并转换为数组。
总结来说,SparkTask的执行流程包括了任务的提交、线程池的调度、TaskRunner的run()方法中的任务分解和操作执行,以及不同类型Task(如ResultTask和ShuffleMapTask)针对不同Action的具体处理。理解这些核心环节有助于深入掌握Spark的分布式计算原理和优化策略。后续的文章将更详细地探讨任务结果的处理,以及如何在Spark中有效地利用这些任务执行流程。
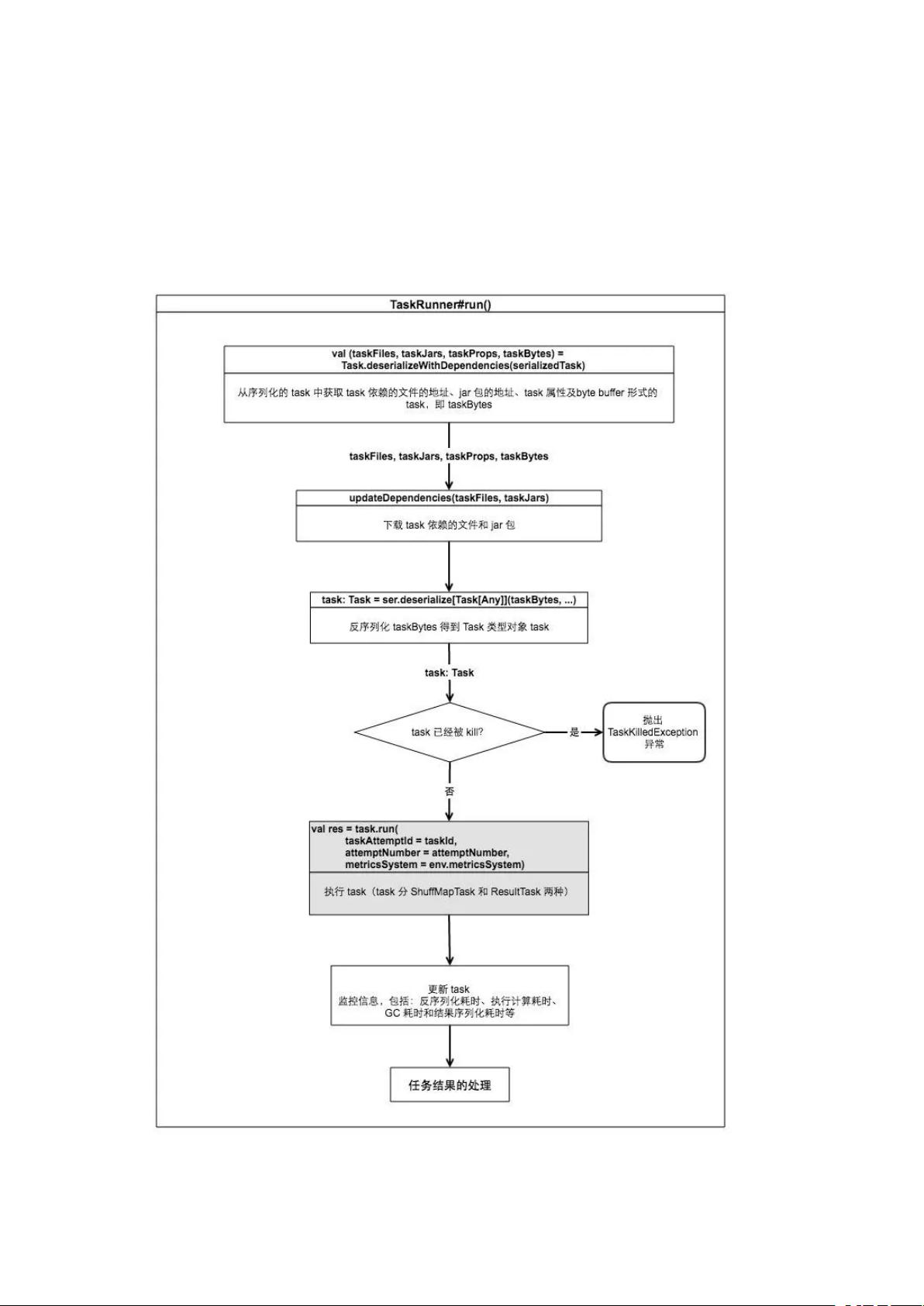
Spark Task 的执行流程--执行 task
TaskRunner(继承于 Runnable) 对象最终会被提交到 Executor 的线程池中去执行, 该
执行过程封装在 TaskRunner#run() 中,搞懂该函数就搞懂了 task 是如何执行的,该函
数的核心实现如下:
下载后可阅读完整内容,剩余5页未读,立即下载
2017-11-27 上传
2017-12-18 上传
2019-10-23 上传
2023-08-16 上传
2023-06-01 上传
2023-09-05 上传
2023-06-10 上传
2024-06-19 上传
2024-06-23 上传

代码深渊漫步者
- 粉丝: 21
- 资源: 320
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
