C语言实现的编译原理词法分析实验指南
需积分: 14 90 浏览量
更新于2024-07-23
收藏 125KB DOC 举报
"本次实验是关于编译原理的词法分析部分,主要使用C语言实现。实验目的是理解和掌握词法分析的基本原理,以及如何在C语言的子集中进行单词符号的识别。实验要求包括选择C语言的一个子集,编写并调试词法分析程序,以及提交完整的实验报告和调试成功的源代码。实验环境为Visual Studio 2010和Windows 7操作系统。词法分析过程中,单词符号被归类为保留字、标识符、常数和界符四种类型,并以二元式的形式输出。实验中给出了保留字和界符的部分表,包括常见的运算符和保留字。"
词法分析是编译器设计的重要组成部分,其任务是对源代码进行扫描,将连续的字符流分解成一个个有意义的单元,即单词符号(Token)。在本实验中,单词符号被分为四类:保留字(Keywords)、标识符(Identifiers)、常数(Constants)和界符(Punctuation)。保留字是编程语言预定义的有特殊含义的词汇,如`if`、`for`等;标识符是程序员自定义的变量、函数名等;常数包括数值和字符串等;界符则是用于分隔和构成语法结构的符号,如括号、运算符等。
实验要求学生选取C语言的一个子集,可以是某一类典型单词,也可以覆盖各种类型的单词。为了简化实验,可以仅选取保留字和界符的部分子集,如表1所示,包含10个保留字和一些基本的运算符、分隔符。在词法分析过程中,每个单词被表示为一个二元式,包含单词类型(t)和指向对应类表中特定项目的指针(i)。这种表示方式有助于后续的语法分析。
实验步骤涉及分析源程序,识别出的单词按照类别填充到对应的表中,并生成一个二元式序列作为索引。词法分析程序在每次调用时会自动扫描并识别下一个单词,直到完整源程序扫描结束。这样的设计有助于理解词法分析的过程,以及如何构建和使用词法分析器。
完成实验后,学生需提交包含完整实验流程、分析结果和源代码的实验报告,以及在机器上调试成功的源程序,以验证词法分析程序的正确性和效率。通过这个实验,学生不仅能够深入理解词法分析的原理,还能实际操作并掌握词法分析器的实现技巧,这对于理解和构建编译器至关重要。
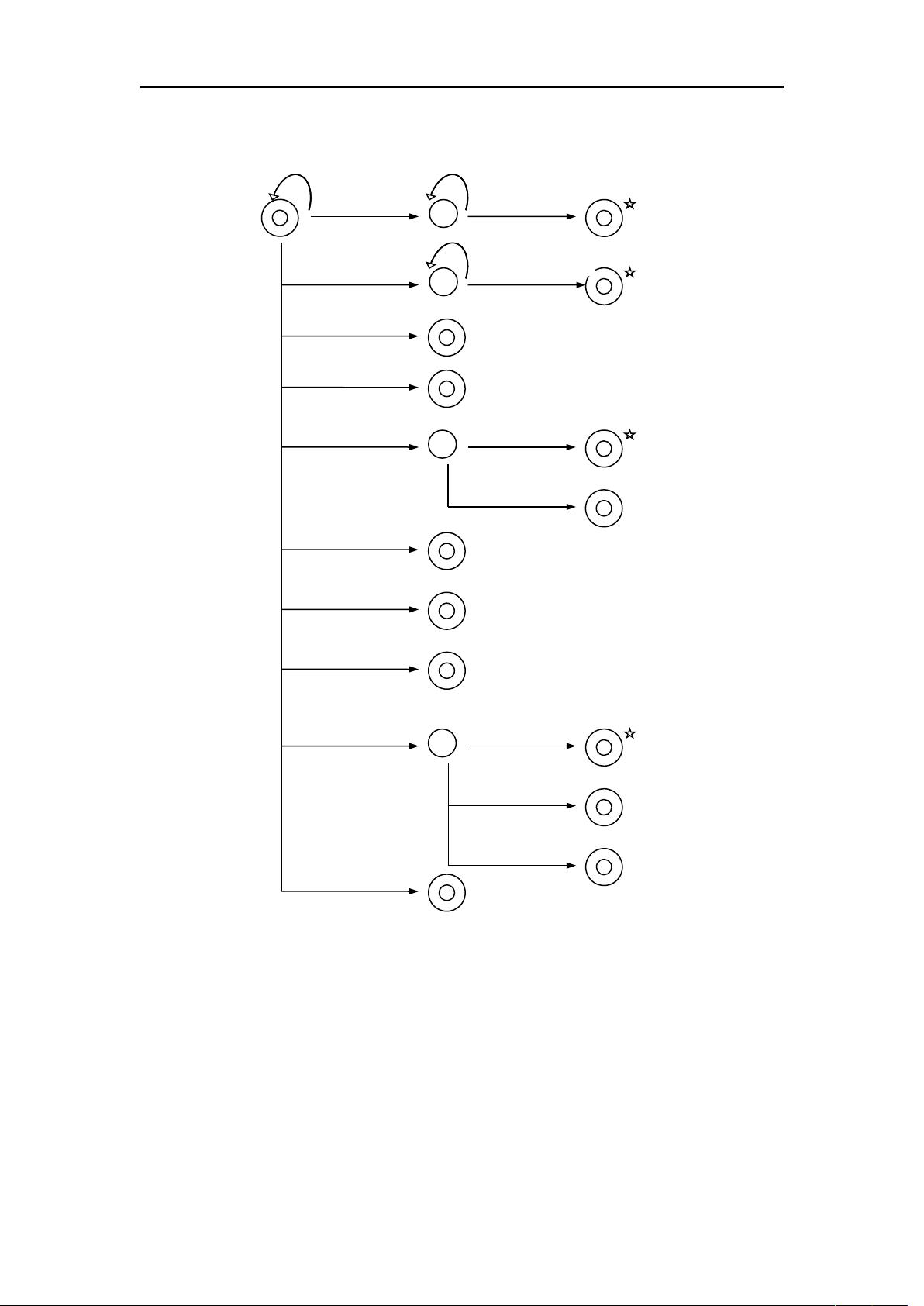
南华大学计算机科学与技术学院 实验报告
说明:这个图只是大概表达一个词法分析的思路,由于不知道加入,所以并不完全准确。
2
字母 非字母与数字
1
字母与数字
0
空白
4
数字 非数字
3
数字
+
6
;
5
8
:
非 =
7
=
9
(
10
,
11
)
12
其它
17
14
< 非 =
13
15
>
16
=
图 1 扫描程序的状态转换图
剩余14页未读,继续阅读
2009-03-05 上传
139 浏览量
2010-10-23 上传
2024-10-25 上传
2024-10-25 上传
2024-10-25 上传
2024-10-25 上传

忘我sunny
- 粉丝: 0
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- ES管理利器:ES Head工具详解
- Layui前端UI框架压缩包:轻量级的Web界面构建利器
- WPF 字体布局问题解决方法与应用案例
- 响应式网页布局教程:CSS实现全平台适配
- Windows平台Elasticsearch 8.10.2版发布
- ICEY开源小程序:定时显示极限值提醒
- MATLAB条形图绘制指南:从入门到进阶技巧全解析
- WPF实现任务管理器进程分组逻辑教程解析
- C#编程实现显卡硬件信息的获取方法
- 前端世界核心-HTML+CSS+JS团队服务网页模板开发
- 精选SQL面试题大汇总
- Nacos Server 1.2.1在Linux系统的安装包介绍
- 易语言MySQL支持库3.0#0版全新升级与使用指南
- 快乐足球响应式网页模板:前端开发全技能秘籍
- OpenEuler4.19内核发布:国产操作系统的里程碑
- Boyue Zheng的LeetCode Python解答集
