自适应数据压缩算法:局部相关性与多尺度分析的应用
PDF格式 | 1.77MB |
更新于2024-06-18
| 25 浏览量 | 举报
"本文介绍了2021年新数据压缩算法的研究与应用,主要关注局部相关性度量下的非均匀采样和多尺度分析方法。该算法适用于数据压缩,尤其适用于处理稀疏信号,并采用了自适应采样策略。通过利用数据的局部统计特性,算法能够动态调整采样密度,从而实现自适应压缩。此外,该算法构建了一个渐进压缩的数据树结构,为多尺度分析和选择性内存释放提供了可能,有助于高效的数据存档管理。
在具体实施上,算法首先衡量数据序列的局部相关性,根据这一度量进行非均匀采样。在处理过程中,不需要额外的输入参数,使得算法具有较高的灵活性。测试结果表明,即使在非稀疏信号条件下,算法也能显著减少样本数量,同时保持信号的相关特性。通过对比重构的无噪声信号与原始信号的傅立叶变换,评估了压缩误差,并考虑了信号带宽与采样频率的比例,以便进行后续的分析比较。
文章还回顾了信息记录的历史,从古代文字到现代数字时代的转变,强调了数据存储和共享的重要性。随着数字时代的到来,虽然数据交换变得更加便捷,但数据中心的能耗问题日益突出,对环境产生了重大影响。因此,开发高效的数据压缩技术,如文中所提出的算法,对于应对全球变暖和实现可持续的信息技术发展至关重要。
为了进一步验证算法的性能,文中选择了理想无噪声信号和实际应用案例进行实验。实验结果证明,新算法在保持信号质量的同时,能有效减少数据存储需求,这对于大数据时代的数据管理和存储具有重要意义。未来的研发方向可能包括优化算法以适应更多类型的数据和应用场景,以及探索如何将这种压缩技术集成到现有的数据管理系统中,以提高整体的能效比。"
P. Daniel
等人
阵列
12
(
2021
)
100076
3
}
(
)
下一
页
=
{()(
)
(
)下
一页
∑
i
=
n
1
{.
)
}
n
=
我
-
不
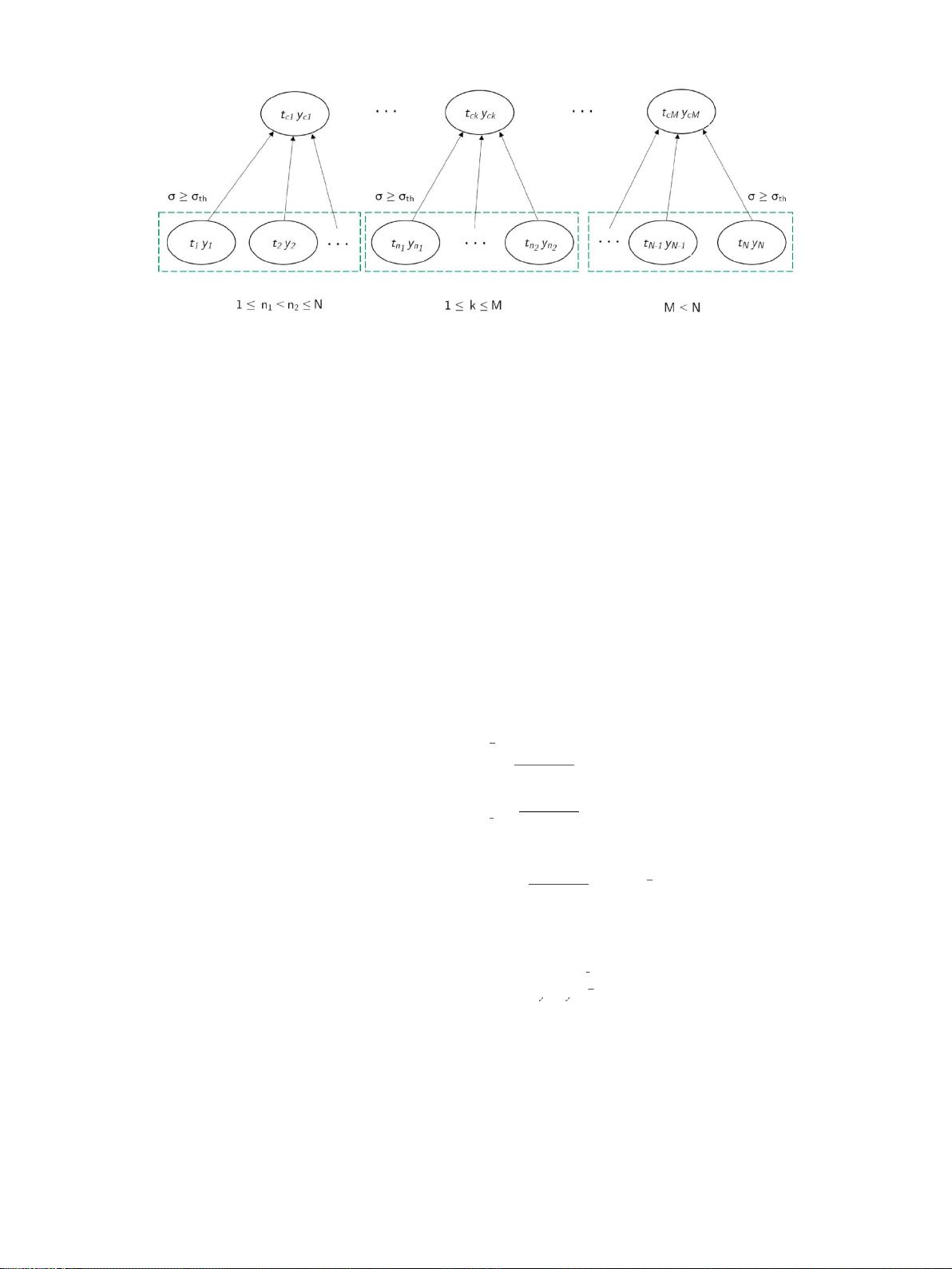
Fig. 1.
压缩过程的图表,显示节点(当前段的样本)与其子节点(合并的较低级别的节点)之间的从属关系。当前段被延长,直到其标准偏差超过截止阈值
σ
th
。
分类在基于事件的采样类别中,但不需要特殊的数据采集硬件。压缩是
有损的,尽管它与近无损压缩有一些相似之处,因为用户可以控制压缩
的程度。此外,如前所述,稀疏信号的常规采样会产生大量不必要的数
据。均匀采样,然后被视为后验作为惩罚约束。相比之下,我们的算法
基本上执行非均匀下采样,这导致相关性的均匀分布
因此,我们的第一个贡献是实现了一个结构化的数据树,一个逐层
的压缩进展,允许数据管理直接在几个规模和逐步减少归档文件。我们
在3.1节中介绍了它的过程原理。在目前的发展阶段,只能处理一维信
号。第二个贡献是基于局部标准差的统计方法,用于在压缩期间实现非
均匀采样,这意味着不使用机器学习或AI技术。由于局部标准偏差的中
心参数,非均匀或自适应采样得以实现,该局部标准偏差测量样本的相
关性并且对噪声非常有弹性。这种自适应压缩技术还利用从数据计算的
质量指标参数。此功能在第3.2节中公开。
据我们所知,这项研究中提出的工作是一个进一步的
通过非均匀采样尝试近无损混合压缩,最大限度地提高能源效率和数据
分析人员的工作效率,并避免前面提到的AI缺点。度量算法性能的几个
关键特征和指标
是 评价 通过 仿真 实验 在 部分 4包括
可以说,非均匀采样引入了额外的数据存储,因为时间戳不再仅从两个
实数计算:采样率和第一个时间戳。这两个数据通常以双精度浮点格式
存储,以便生成的系列具有足够的分辨率。在我们的例子中,如果保存
树,存储每个节点的子节点的数量,则存储所有时间戳也不是强制性
的。每个时间戳都可以计算出来, 该树具有相同的精度,因为记录了
原始信号的恒定采样率及其第一时间戳。子节点的数量可以以整数格式
存储,这只需要少量的内存。
因此,我们认为点的集合
S= {
(
t
1
;y
1
),
是输出信号的M个样本,其中
M
为
N
。
<
发起
在压缩中,取输入信号的第一段,其仅包含前两个样本
Sn
= {(t
1
;y
1
),
(t
2
;y
2
)
}
,将其标准偏差σ与预定义的截止阈值σ th进行比较。如果
σσ
th
,则将下一个样本t
3
;y
3
附加到Sn
,
并且重复比较的过程以及附加
(cf.
<
等式(1)),直到阈值
路口.在这种情况下,该片段从信号中被切断,并且其质心t
c1
;y
c1
(参见
等式(2)和(3))被附加到压缩采样,这是其目前唯一的点。然后打
开一个新的段,该段最初仅包含原始采样中的下两个点。整个过程一直
重复到最后,如
图1示出了压缩采样的任意项(
t
ck
;y
ck
)
S
n
={
(
t
n
1
;y
n
1
),
n
2
压缩比、压缩水平的相对平均误差、空间-
y
n
=
n
1
1
∑
y
i
(
2
)
节省,压缩增益,信噪比,最大绝对失真,信号分割,局部采样率和平
均
2
-n
1
+
i=n
1
n
每个节点的子节点。最后,我们提出了我们的压缩算法的测试结果上提
供的信号均匀采样。
使用阈值
1
2
n
=
n
2
-n
1
+1
i
(三
)
用启发式方法确定:人在休息时的正常ECG
从Physionet数据库中提取,并由欧洲航天局测试任务的卫星
σ
1
i
=
n
1
(四
)
3.
算法分解
3.1.
树结构数据压缩
数字数据序列的压缩不仅是为了节省存储空间
与阈值的比较以及所产生的动作可以在简单的标准逻辑操作中实
现。(假设
n
2
scin
=
N
或
N
-
1
):
t
ck
=
t
n
空间,但也要过滤掉不太相关或不必要的信息,
σ
n
≥σ
t
h
y
ck
=
{
y
.
n
t
y
)
。
t
y
(五
)
作为测量噪声。因此,该算法充当低通滤波器
⎪
⎩
S
n
=
n
2
+
1
,
n
2
+
2
;
n
2
+
2
旨在促进大数据的利用。
图1示意了所提出的压缩树过程。当原始采样是均匀的时,这种树结
构减少了数据存储
σ
n
σ
th<$Sn
=Sn
<
$ t
n
2
+1
;
yn
2
+1
(6)<
然而,在这方面, 的 标准 偏差 并 不 采取 成 账户a
)
}
n
2
-n
1
+1
n
不
剩余14页未读,继续阅读
相关推荐





cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Openaea:Unity下开源fanmad-aea游戏开发
- Eclipse中实用的Maven3插件指南
- 批量查询软件发布:轻松掌握搜索引擎下拉关键词
- 《C#技术内幕》源代码解析与学习指南
- Carmon广义切比雪夫滤波器综合与耦合矩阵分析
- C++在MFC框架下实时采集Kinect深度及彩色图像
- 代码研究员的Markdown阅读笔记解析
- 基于TCP/UDP的数据采集与端口监听系统
- 探索CDirDialog:高效的文件路径选择对话框
- PIC24单片机开发全攻略:原理与编程指南
- 实现文字焦点切换特效与滤镜滚动效果的JavaScript代码
- Flask API入门教程:快速设置与运行
- Matlab实现的说话人识别和确认系统
- 全面操作OpenFlight格式的API安装指南
- 基于C++的书店管理系统课程设计与源码解析
- Apache Tomcat 7.0.42版本压缩包发布
