全托管消息队列Kafka:高性能、高可用的数据传输平台
需积分: 25 26 浏览量
更新于2024-07-17
收藏 1.21MB PDF 举报
"消息队列Kafka介绍"
Kafka是一个分布式、高性能的消息队列服务,起源于LinkedIn并后来成为Apache软件基金会的顶级项目。它最初设计的目的是为了处理大规模的日志收集,现在则广泛应用于大数据处理、实时分析以及事件驱动的应用程序。Kafka作为一个消息中间件,它的核心功能在于高效地在生产者和消费者之间传输大量数据,同时提供高可用性和可扩展性。
在Kafka架构中,有以下几个关键角色:
1. **Controller**:Controller是Kafka集群的管理器,负责监控和管理集群中的分区和副本状态。它处理如领导者选举、分区分配等操作,确保系统的稳定运行。
2. **Broker**:Broker是Kafka的基本单位,每个Broker都是一个独立的服务器,可以接收和存储消息。多个Broker组成一个Kafka集群,提供冗余和负载均衡。
3. **ZooKeeper**:ZooKeeper是一个分布式协调服务,Kafka早期版本依赖于它来进行集群状态管理和故障恢复。不过,从Kafka 2.8版本开始,Kafka已经逐步减少对ZooKeeper的依赖,实现自我管理。
4. **Producer**:Producer是消息的发布者,它负责将消息发送到Kafka的特定主题(Topic)上。Kafka支持同步和异步两种生产模式,可以根据应用需求选择合适的发送策略。
5. **Consumer**:Consumer是消息的订阅者,它可以订阅一个或多个主题,并消费其中的消息。Kafka支持多消费者组模型,同一组内的消费者会进行负载均衡,避免重复消费。
6. **Consumer Group**:消费者组是Kafka的一个重要特性,它允许一组消费者共享订阅的主题,每个分区只会被组内的一个消费者消费,这样可以实现并行处理和故障恢复。
Kafka的优势在于其高吞吐量、低延迟以及强大的持久化能力。消息可以被持久化到硬盘,保证了即使在服务器宕机的情况下也不会丢失数据。此外,Kafka的可扩展性强,可以通过添加更多的Broker来水平扩展集群,以应对更高的消息处理需求。
使用消息队列Kafka服务,可以避免自建Kafka集群带来的运维复杂性,例如参数调优、扩缩容、磁盘和网络管理等问题。云服务商提供的全托管服务简化了这些流程,用户只需要专注于业务开发,无需关心底层基础设施,降低了成本,提高了服务的弹性和可靠性。
在实际应用中,Kafka常用于日志聚合、流式处理、实时监控、用户行为追踪等多个场景。例如,网站可以使用Kafka收集用户点击流数据,然后通过实时处理引擎(如Spark Streaming或Flink)进行分析,从而快速响应用户的活动变化。
总结来说,Kafka是一个强大且灵活的消息队列解决方案,尤其适合大数据和实时分析环境。全托管的消息队列Kafka服务让开发者能够更专注于业务逻辑,而不用担心基础架构的运维问题。
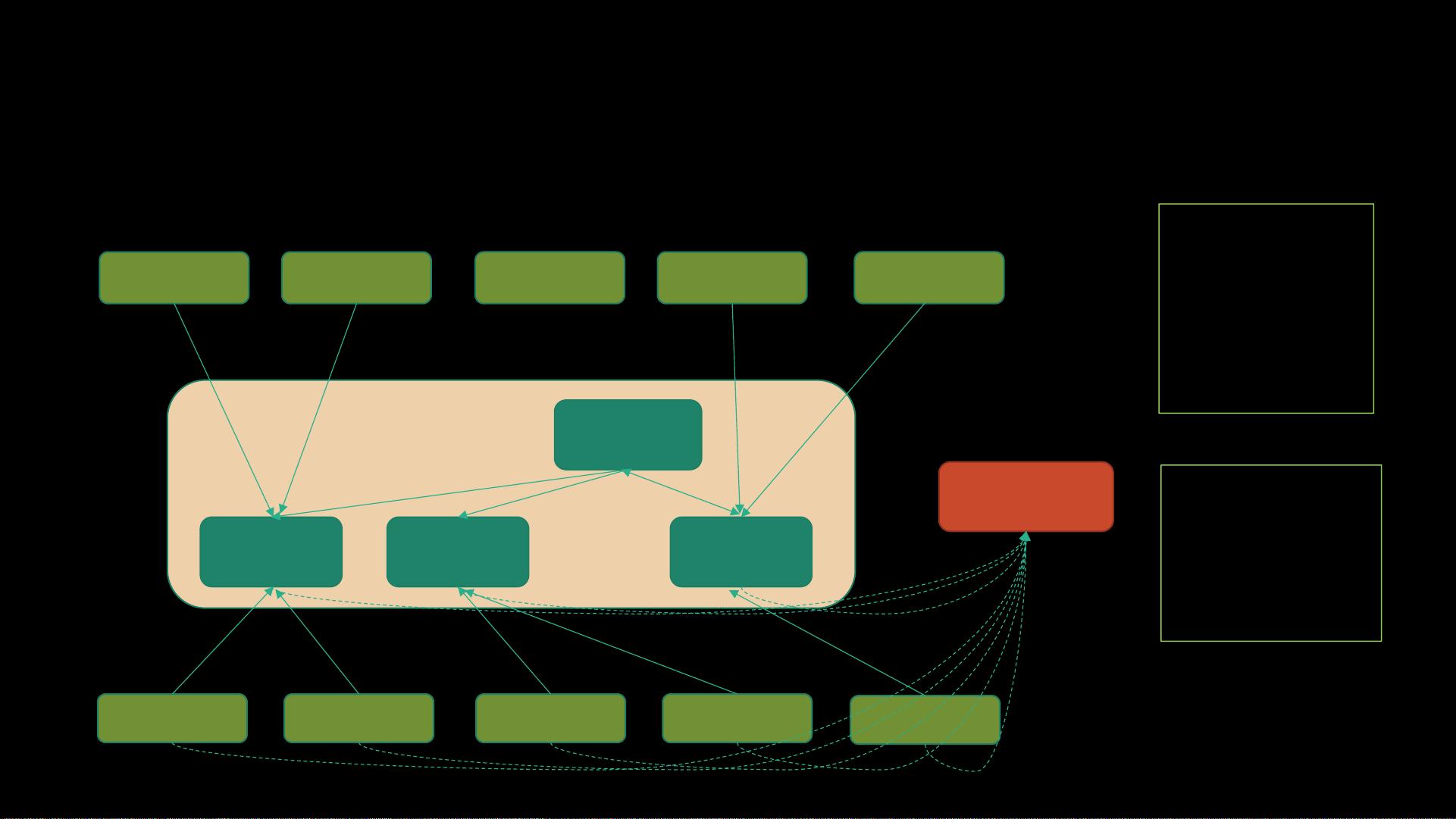
角色相关
• Controller
• Broker
• ZooKeeper
• Producer
• Consumer
系统相关
• 参数调优
• 扩缩容
• 磁盘
• 网络
broker broker broker
controller
ZooKeeper
Consumer Consumer Consumer Consumer
Consumer
Producer
Producer
Producer
Producer
Producer
…...
Kafka Cluster
自建Kafka的烦恼
Apache Kafka运维难度大
剩余23页未读,继续阅读
2021-08-23 上传
2021-03-19 上传
2021-09-26 上传
2024-04-18 上传
2021-07-24 上传
2019-06-27 上传
2023-06-10 上传
2022-03-04 上传
2021-10-24 上传

weixin_38743481
- 粉丝: 696
- 资源: 4万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
