深度学习基础解析:从神经网络到卷积网络
需积分: 10 106 浏览量
更新于2024-07-07
收藏 1.96MB PDF 举报
"该资源是一份深度学习的基础讲义,主要涵盖了深度学习的基本概念、卷积神经网络(CNN)的解析及其应用实例,以及深度学习方法在图像识别中的运用。讲义强调了学习深度学习的目的,即寻找合适的函数来解决如数字识别、猫狗识别、人脸识别等任务,并介绍了学习过程,包括确定函数集合、评价标准、模型建立、损失函数、参数学习等方面。此外,还提到了监督学习的概念,并以手写识别为例,展示了训练和测试数据在深度学习中的应用。最后,讨论了当前深度学习模型存在的问题,如模型架构的灵活性和参数过多等。"
深度学习是人工智能领域的一个重要分支,其主要目标是通过模拟人脑神经网络的工作机制来构建复杂的学习模型,处理各种复杂的数据,如图像、语音和文本。在本讲义中,深度学习被定义为寻找一个合适的函数来映射输入到期望的输出。例如,在图像识别任务中,这个函数可以将一张图片转化为对应的标签,如数字、动物或人脸。
深度神经网络(DNN)是深度学习的核心组件,但它们也存在一些问题。其中,卷积神经网络(CNN)作为解决图像识别问题的有效工具,被详细讲解。CNN利用卷积层和池化层来提取图像特征,减少了模型的参数数量,提高了计算效率。讲义中提供了CNN的应用示例,说明了如何通过CNN进行图像识别。
在学习过程中,深度学习首先需要确定一个函数集合,这通常是一个庞大的参数空间。然后,通过损失函数来衡量模型预测与真实结果之间的差距,例如均方误差。接下来,通过反向传播和优化算法(如梯度下降)更新模型参数,以最小化损失函数,从而找到最佳函数。这一过程称为参数学习。
监督学习是深度学习最常见的一种学习方式,它需要有标记的训练数据。在手写识别的例子中,训练数据包含了输入图像(手写数字)和对应的正确标签,模型通过学习这些数据来调整参数,以提高预测准确率。训练完成后,使用未见过的测试数据来评估模型的泛化能力。
然而,现有的深度学习模型面临一些挑战。比如,模型架构可能过于固定,对于不同大小或复杂性的输入,可能需要增加神经元数量或层数,这可能导致过拟合和计算资源的浪费。另外,模型参数过多可能导致训练时间过长和内存需求增大。因此,后续的内容可能涉及到如何通过改进模型结构、引入正则化等技术来解决这些问题,以提升模型的灵活性和效率。
……
……
……
……
……
……
……
y
1
y
2
y
m
x
1
x
2
x
n
……
……
模型不足
16 x 16 = 256
256个神经元
1000个神经元
1000 个神经元
10 个神经元
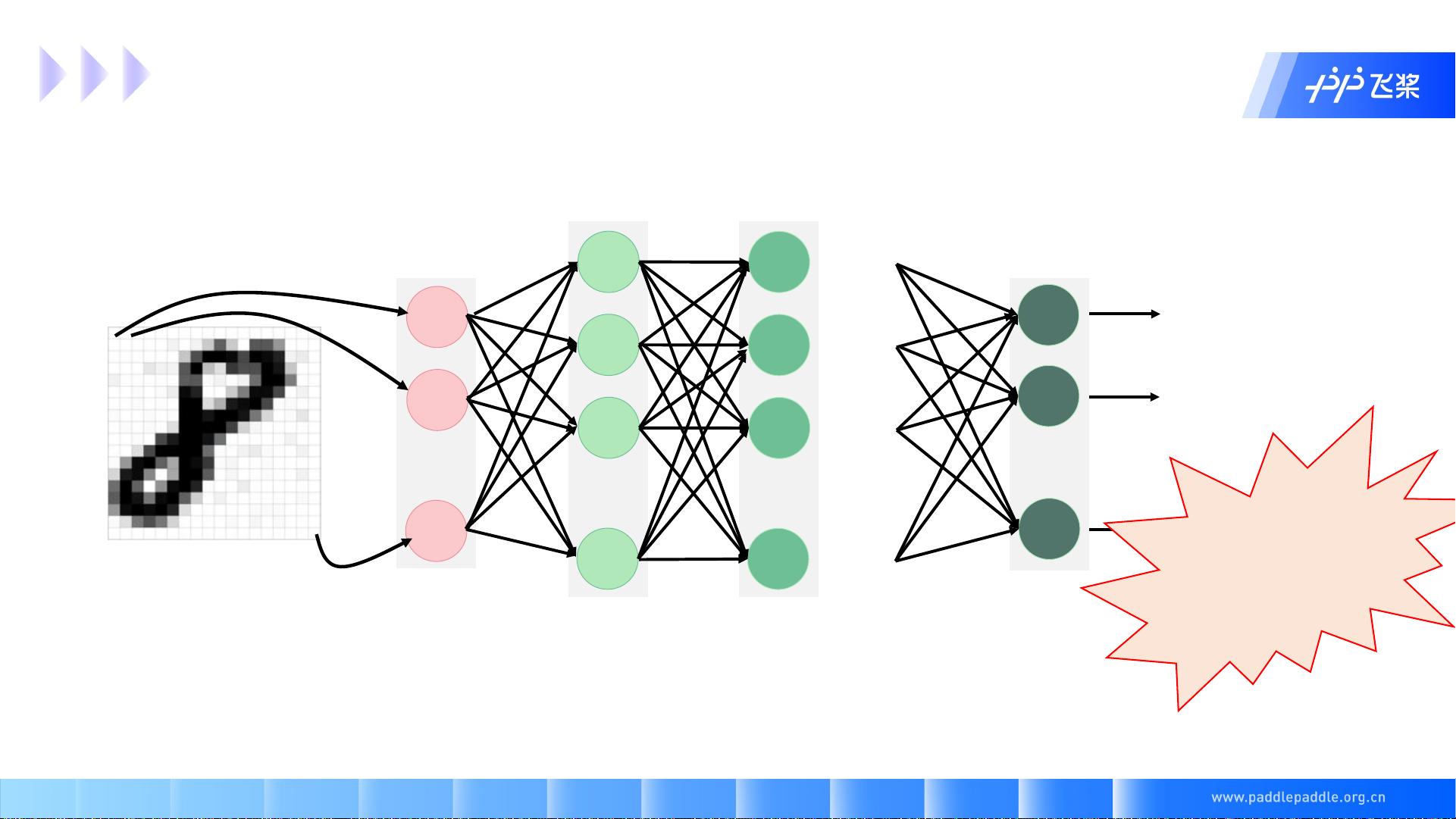
假设对 16 x 16 的图片进行分类手写字体分类任务,设计了如上所示的网络。
那对100*100的图片做相同的任务,只有通过增加每层的神经元个数或者增加网络的层数来完成。
模型结构不够灵活
网络结构
不够灵活
剩余69页未读,继续阅读
103 浏览量
2023-09-12 上传
2021-08-18 上传
2021-08-19 上传
2021-08-31 上传
2021-08-19 上传
2019-06-20 上传
2021-11-26 上传
2021-08-19 上传

放码过来呀!!!
- 粉丝: 395
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- ES管理利器:ES Head工具详解
- Layui前端UI框架压缩包:轻量级的Web界面构建利器
- WPF 字体布局问题解决方法与应用案例
- 响应式网页布局教程:CSS实现全平台适配
- Windows平台Elasticsearch 8.10.2版发布
- ICEY开源小程序:定时显示极限值提醒
- MATLAB条形图绘制指南:从入门到进阶技巧全解析
- WPF实现任务管理器进程分组逻辑教程解析
- C#编程实现显卡硬件信息的获取方法
- 前端世界核心-HTML+CSS+JS团队服务网页模板开发
- 精选SQL面试题大汇总
- Nacos Server 1.2.1在Linux系统的安装包介绍
- 易语言MySQL支持库3.0#0版全新升级与使用指南
- 快乐足球响应式网页模板:前端开发全技能秘籍
- OpenEuler4.19内核发布:国产操作系统的里程碑
- Boyue Zheng的LeetCode Python解答集
