词法分析实验:构建扫描器与Token生成
"本次实验是关于编译原理中的词法分析器实现,旨在让学生熟悉词法分析器的设计与实现过程。实验要求使用C语言或C++编写代码,输入为源程序文件,输出包括Token系列、关键字表、界符表、符号表和常数表。实验内容包括设计扫描器的自动机、生成Token的算法以及上机调试。提供的关键字表包含了诸如'program', 'procedure', 'begin', 'end', '+', '*', ':=', ','等常见编程语言的关键字。实验还给出了部分源代码,如对关键字表和界符表的定义,以及用于处理Token、错误处理和判断字符类型的辅助函数。"
在编译原理中,词法分析器(也称为扫描器或lexer)是编译器的第一个阶段,它的主要任务是将源代码文本分解成一系列有意义的单元,称为Token。这些Token是语言的最小语法单位,比如关键字、标识符、常量、运算符和分隔符等。
1. **设计扫描器的自动机**:
扫描器的自动机通常是一个有限状态自动机(Finite State Automaton, FSA),它根据输入字符流的状态进行转换。在给出的实验中,自动机以状态①开始,根据输入字符'l'或'd'转移到不同的状态。例如,状态①接收'd'会转到状态②,然后根据后续字符进行进一步的转移。自动机的设计目的是确保能正确识别出关键字、标识符、数字和其他字符。
2. **生成Token的算法**:
算法设计通常包含以下步骤:
- 初始化:设置初始状态,可能包括清除缓冲区、设置错误处理标志等。
- 滤除空格:忽略程序中的空白字符,因为它们在语法分析中通常不重要。
- 读取第一个非空字符:获取源代码中的下一个有意义的字符。
- 关键字/标识符处理:如果字符是字母,开始读取可能的关键字或标识符,通过比较关键字表来确定是关键字还是标识符。
- 常数处理:如果字符是数字,处理数字常数,将其添加到常数表。
- 界符处理:处理运算符、分隔符等。
- 错误处理:当遇到无法识别的字符时,进行错误处理,如调用`ProcError()`函数。
实验代码中,定义了结构体`TokenType`存储Token的代码和值,以及关键字表、界符表、符号表和常数表。`IsLetter()`和`IsDigit()`函数用于辅助判断字符类型。`Print()`函数用于输出Token信息,而`ProcError()`用于输出错误提示。
通过完成这个实验,学生将能够深入理解词法分析的过程,并实际操作如何构建一个简单的词法分析器,这对于理解和构建更复杂的编译器至关重要。
编译原理实验 实验一
实验题目:词法分析
实验目的:熟悉并实现一个简单的扫描器
实验内容:
1. 设计扫描器的自动机
2. 设计翻译、生成 Token 的算法
3. 编写代码并上机调试运行通过
实验要求:( 用 C 语言或 C++环境设计并实现)
输入:源程序文件
输出:
(1)相应的 Token 系列
(2)关键字、界符表,符号表,
常数表
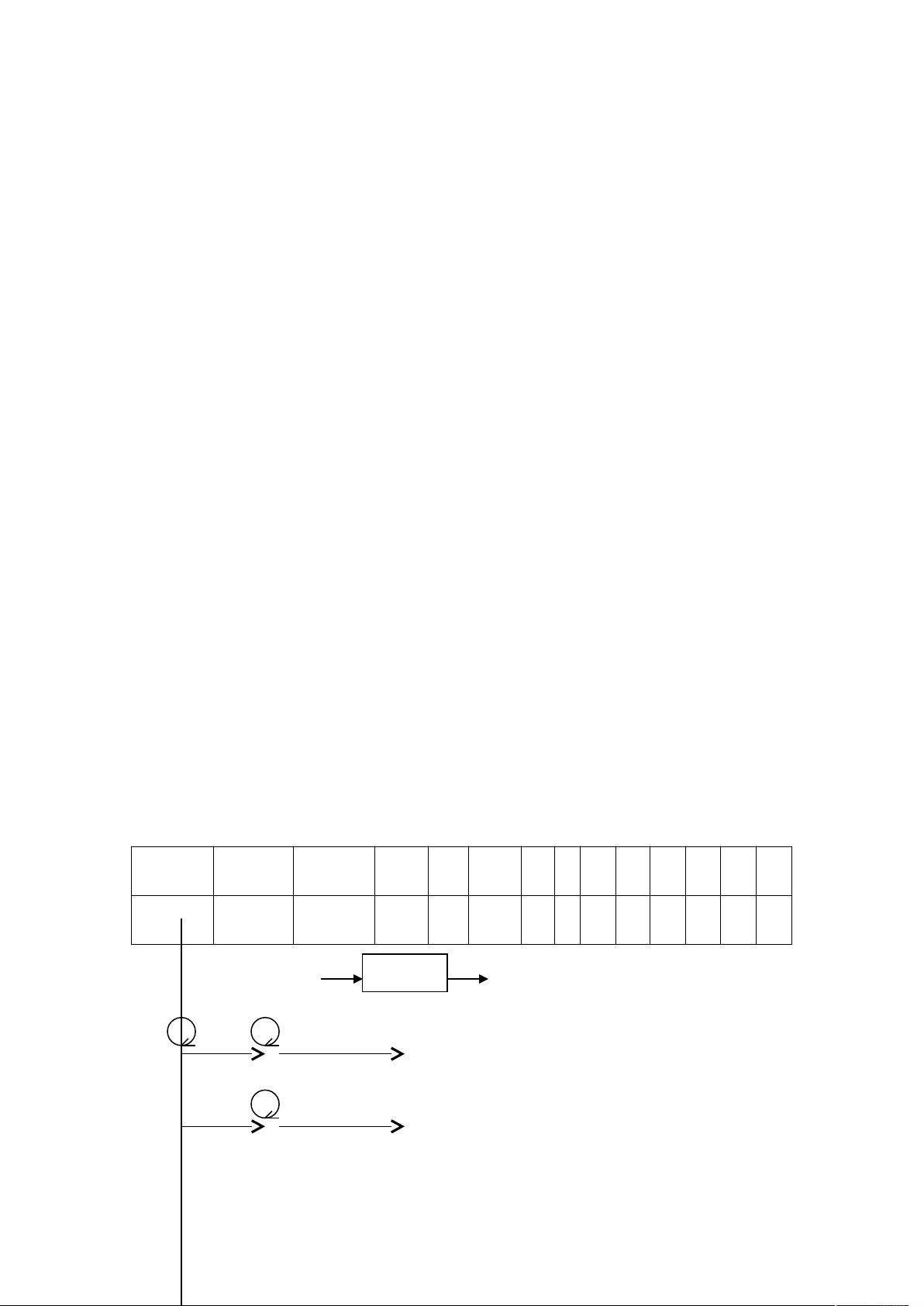
关键字表和界符表:
关键字
program
procedure begin end while do + * : := = , ;
编码
3 4 5 6 7 8 9 10 11 12 13 14 15
概要设计:单词 Token
1.自动机:
空 l/d
① ②-
d
d -1
③ ④-
+
扫描器
下载后可阅读完整内容,剩余6页未读,立即下载
2021-06-17 上传
2011-06-19 上传
2022-05-05 上传
2010-05-07 上传
2011-01-05 上传
2009-06-19 上传

李狗蛋儿
- 粉丝: 4
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- BottleJS快速入门:演示JavaScript依赖注入优势
- vConsole插件使用教程:输出与复制日志文件
- Node.js v12.7.0版本发布 - 适合高性能Web服务器与网络应用
- Android中实现图片的双指和双击缩放功能
- Anum Pinki英语至乌尔都语开源词典:23000词汇会话
- 三菱电机SLIMDIP智能功率模块在变频洗衣机的应用分析
- 用JavaScript实现的剪刀石头布游戏指南
- Node.js v12.22.1版发布 - 跨平台JavaScript环境新选择
- Infix修复发布:探索新的中缀处理方式
- 罕见疾病酶替代疗法药物非临床研究指导原则报告
- Node.js v10.20.0 版本发布,性能卓越的服务器端JavaScript
- hap-java-client:Java实现的HAP客户端库解析
- Shreyas Satish的GitHub博客自动化静态站点技术解析
- vtomole个人博客网站建设与维护经验分享
- MEAN.JS全栈解决方案:打造MongoDB、Express、AngularJS和Node.js应用
- 东南大学网络空间安全学院复试代码解析
