数据科学家成长之路:NLP、数据可视化与大数据探索
96 浏览量
更新于2024-07-15
收藏 1.08MB PDF 举报
"数据科学家成长指南(中)" 涉及到的知识点涵盖了自然语言处理、数据可视化和大数据。在自然语言处理方面,主要讲解了中文自然语言处理的挑战,如分词问题,以及语料库的重要性和构建。此外,还提到了自然语言工具包NLTK,命名实体识别的技术及其应用。
1. **自然语言处理(NLP/TextMining)**: NLP是结合了人类学、语言学的学科,中文NLP相比英文更复杂,因为中文是以字为基本单位,需要通过分词来处理。高质量的分词是NLP成功的关键。
2. **中文分词**: 中文分词是自然语言处理的基础,由于中文词汇没有空格分隔,需要专门的算法进行词的划分。准确的分词对于后续的语义分析、情感分析等至关重要。
3. **语料库(Corpus)**: 大规模电子文本库,是NLP研究的基础,可以包含各种类型的文本,如文献、小说、新闻等。语料库的构建需考虑不同文体的平衡,同时需要进行语言学标注。
4. **NLTK和自然语言工具包**: NLTK是Python中广泛使用的NLP库,包含了丰富的语料库和工具,对英文处理非常成熟,但处理中文时需要额外的分词工具,如jieba、HanLP等。
5. **命名实体识别(Named Entity Recognition, NER)**: NER是识别文本中的特定实体,如人名、地名、时间等。它涉及实体的边界确定和类型识别,是NLP中的关键任务。中文NER更具挑战性,需要解决分词歧义问题。
6. **命名实体识别方法**: 包括基于规则和词典的方法,以及基于机器学习的方法,如HMM、最大熵模型和CRF等。这些方法用于确定实体边界和类型。
7. **文本分析(TextAnalysis)**: 是一个涵盖广泛的研究领域,包括语法分析、语义分析等,它在语言学、社会学和计算机科学等多个领域都有应用。
8. **数据可视化**: 数据科学家需要掌握如何将复杂数据转化为易于理解的图形和图表,这包括使用各种工具如Matplotlib、Seaborn、Tableau等进行数据呈现。
9. **大数据**: 大数据处理涉及到大规模数据的存储、管理和分析,常用工具有Hadoop、Spark等,数据科学家需要了解分布式计算和流式处理技术。
以上内容构成了数据科学家在自然语言处理方面的进阶学习路径,结合数据可视化和大数据技术,能够提升数据科学家的综合能力,帮助他们更好地挖掘和解释文本数据中的信息。
删除。另外一部分是日常用语,你好,谢谢,对文本分析没有帮助,为了区分出它们,我们再加入权重。
权重代表了词语的重要程度,像你好、谢谢这种,我们认为它的权重是很低,几乎没有任何价值。权重既能人工打分,也能通
过计算获得。通常,专业类词汇我们会给予更高的权重,常用词则低权重。
通过词频和权重,我们能提取出代表这份文本的特征词,经典算法为TF-IDF。
Support Vector Machines
支持向量机
它是一种二类分类模型,有别于感知机,它是求间隔最大的线性分类。当使用核函数时,它也可以作为非线性分类器。
它可以细分为线性可分支持向量机、线性支持向量机,非线性支持向量机。
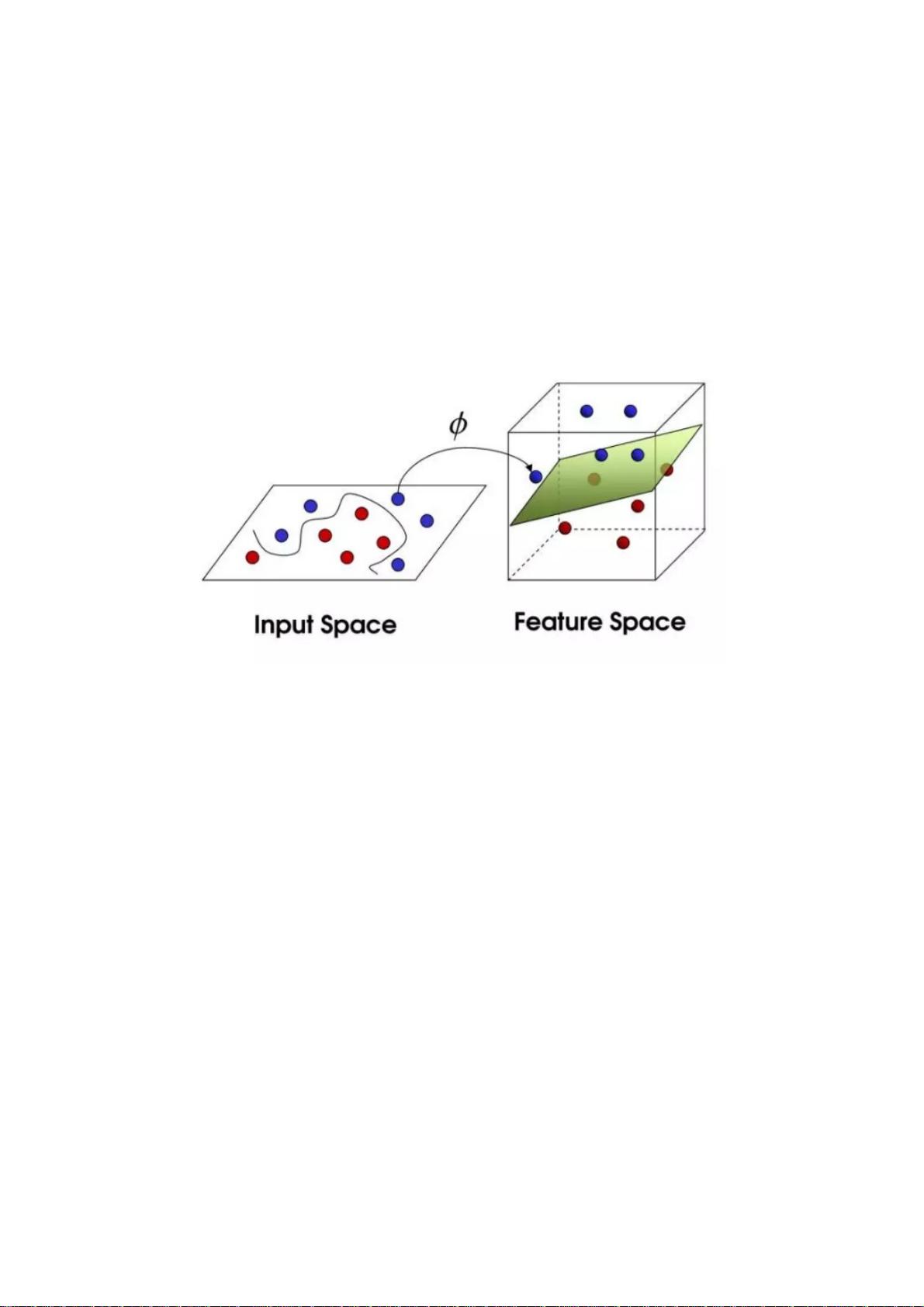
非线性问题不太好求解,图左就是将非线性的特征空间映射到新空间,将其转换成线性分类。说的通俗点,就是利用核函数将
左图特征空间(欧式或离散集合)的超曲面转换成右图特征空间(希尔伯特空间)中的的超平面。
常用核函数有多项式核函数,高斯核函数,字符串核函数。
字符串核函数用于文本分类、信息检索等,SVM在高维的文本分类中表现较好,这也是出现在自然语言处理路径上的原因。
Association Rules
关联规则
它用来挖掘数据背后存在的信息,最知名的例子就是啤酒与尿布了,虽然它是虚构的。但我们可以理解它蕴含的意思:买了尿
布的人更有可能购买啤酒。
它是形如X→Y的蕴涵式,是一种单向的规则,即买了尿布的人更有可能购买啤酒,但是买了啤酒的人未必会买尿布。我们在
规则中引入了支持度和置信度来解释这种单向。支持度表明这条规则的在整体中发生的可能性大小,如果买尿布啤酒的人少,
那么支持度就小。置信度表示从X推导Y的可信度大小,即是否真的买了尿布的人会买啤酒。
关联规则的核心就是找出频繁项目集,Apriori算法就是其中的典型。频繁项目集是通过遍历迭代求解的,时间复杂度很高,大
型数据集的表现不好。
关联规则和协同过滤一样,都是相似性的求解,区分是协同过滤找的是相似的人,将人划分群体做个性化推荐,而关联规则没
有过滤的概念,是针对整体的,与个人偏好无关,计算出的结果是针对所有人。
Market Based Analysis
购物篮分析,实际是Market Basket Analysis,作者笔误。
传统零售业中,购物篮指的是消费者一次性购买的商品,收营条上的单子数据都会被记录下来以供分析。更优秀的购物篮分
析,还会用红外射频记录商品的摆放,顾客在超市的移动,人流量等数据。
关联规则是购物篮分析的主要应用,但还包括促销打折对销售量的影响、会员制度积分制度的分析、回头客和新客的分析。
Feature Extraction
特征提取
剩余14页未读,继续阅读
2021-02-24 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-05-17 上传
点击了解资源详情
点击了解资源详情

weixin_38606466
- 粉丝: 11
- 资源: 871
 我的内容管理
展开
我的内容管理
展开







