Python实现KNN算法实战:电影类型预测与鸢尾花分类
本文主要介绍了机器学习中的K-近邻算法(KNN)及其应用。KNN是一种基于实例的学习方法,其核心思想是根据输入数据在已知数据集中的相似性进行预测。以下是文章的主要知识点:
**一、K-近邻算法原理**
1. KNN的基本概念:算法基于训练样本集,其中每个样本都有特征和相应的标签。新数据通过寻找与其特征最接近的K个训练样本,根据这些样本的类别分布确定预测标签。
2. 距离度量:KNN使用的是特征值之间的距离(如欧氏距离)来衡量相似性,K通常是一个小整数,比如1到20。
3. 有监督学习:KNN是监督学习的一种,因为训练数据中包含已知的输入和输出(标签)。
**二、K-近邻算法案例**
1. **使用步骤**:
- 导入所需库(如pandas、numpy等)
- 准备数据集,包括特征数据(如电影的武打镜头和接吻镜头数)和标签(电影类型)
- 训练模型(KNN分类器)
- 进行预测,对新数据进行分类
- 评估模型性能,如计算训练数据和预测数据的得分
2. **具体案例**:
- **预测电影类型**:通过电影中的武打镜头和接吻镜头数量来预测动作片或爱情片。首先,从电影数据中提取相关特征并划分训练数据和标签。
- **数据可视化**:文章还涉及了如何通过matplotlib和pyplot库对预测结果进行可视化,例如展示预测边界、交叉表和不同变量之间的关系。
3. **其他知识补充**:
- **随机数种子**:确保每次运行实验时能重现相同的结果,通常设置固定的随机数种子。
- **数据标准化**:为了减少特征间量纲的影响,可能需要对数据进行预处理,如Z-score标准化或最小-最大规范化。
4. **对比**:文章还提到了K近邻回归算法与线性回归模型(如Lasso回归)在处理线性数据预测上的区别,展示了KNN在回归任务中的应用。
综上,本文详细讲解了K-近邻算法的工作原理,并通过实例演示了如何使用Python实现KNN进行电影类型预测以及数据可视化,同时还讨论了如何优化算法性能和数据预处理技巧。通过阅读这篇文章,读者能够深入了解KNN算法并在实际项目中应用它。
6-机器学习之机器学习之KNN((K-近临算法)近临算法)
tags: python,机器学习,KNN,matplotlib,pyplot,pandas,numpy,Series,DataFrame
文章目录文章目录一、 k-近邻算法原理二、k-近邻算法案例2.1. 使用步骤2.2. 预测电影类型2.3. 通过身高、体重、鞋子尺码数据预测性别2.4. 预测鸢尾花类型2.4.1. 常规机器学习步骤2.4.2. 机
器学习结果可视化(获取knn分类的边界)2.5. 使用交叉表对预测结果进行可视化展示2.6. 对训练值、训练值标签、预测标签进行可视化展示2.7. k-近临算法用于回归对趋势进行预测
三、其他知识补充3.1. 随机数种子3.2. 机器学习数据标准化四、`K近临回归算法`和`Lasso回归`在线性数据预测中的表现
一、一、 k-近邻算法原理近邻算法原理
存在一个样本数据集合,也称作训练样本集(一般在代码中用X_train和y_train表示),并且样本集中每个数据都存在标签(y_train存放标签数据),即我们知道样本集中每一数据(X_train中存放)与
所属分类(y_train中存放)的对应关系。
输人没有标签的新数据(X_test中存放)后,将新数据的每个特征与样本集中数据对应的 特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。
一般来说,我们 只选择样本数据集中前K个最相似的数据,这就是K-近邻算法中K的出处,通常K是不大于20的整数。 最后 ,选择K个最相似数据中出现次数最多的分类,作为新数据的
分类。
简单地说,K-近邻算法采用测量不同特征值之间的距离方法进行分类。
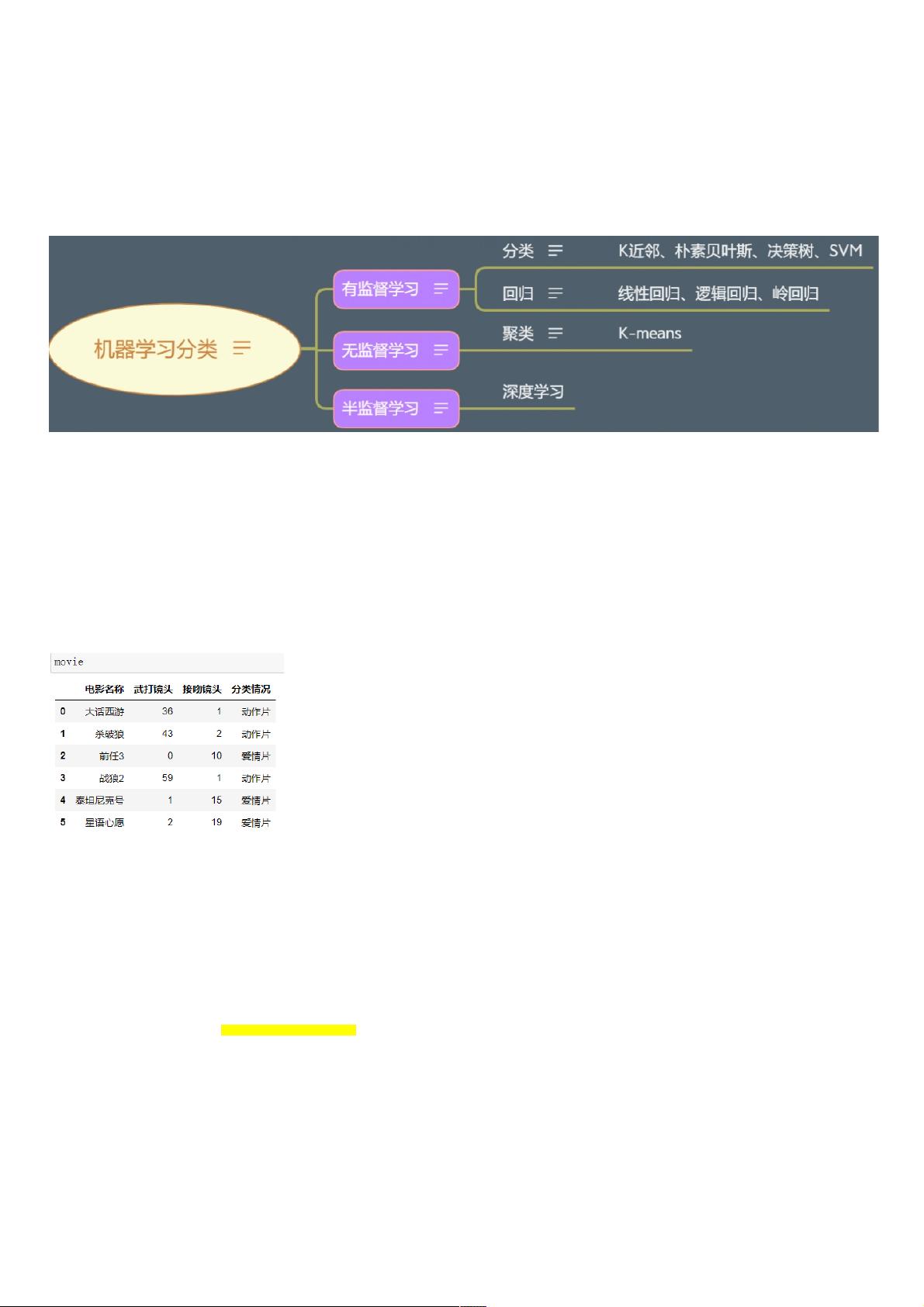
k-近邻算法属于有监督学习算法,即训练值中有对应的结果。机器学习的分类见上图。
二、二、k-近邻算法案例近邻算法案例
2.1. 使用步骤使用步骤
调包
准备数据
建立训练模型
训练
预测
计算训练数据得分和预测数据得分
2.2. 预测电影类型预测电影类型
通过统计每个电影中,接吻和打斗的次数,来区分电影是动作片还是爱情片。
目前有电影数据movie数据如下:
获取训练数据X_train和对应的标记y_train:
X_train = movie[['武打镜头', '接吻镜头']] y_train = movie['分类情况']
将上面获取到的训练数据使用knn算法进行计算,但是在计算前,需要先导入使用到的模块:
import pandas as pd
import numpy as np
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
# 训练数据必须是2维, 标记没有要求是几维的,一般是1维, 而且也没有要求必须是数字,
knn.fit(X_train, y_train)
训练数据必须是训练数据必须是2维维,
标记没有要求是几维的,一般是1维,而且也没有要求必须是数字。
现在有待预测的新数据:
# 预测数据
# 哪吒, 海王, 红海行动, 前任2,
X_test = np.array([[50, 0], [40, 2], [65, 0], [1, 20]])
使用上面的待预测数据X_test,调用训练好的模型,来预测其对应的分类结果:
knn.predict(X_test)
输出结果为array(['动作片', '动作片', '动作片', '爱情片'], dtype=object)
最后可以测试一下我们的模型预测的准确率:
y_test = ['动作片', '动作片', '动作片', '爱情片'] knn.score(X_test, y_test)
输出结果为1.0,即预测准确率为100%。
2.3. 通过身高、体重、鞋子尺码数据预测性别通过身高、体重、鞋子尺码数据预测性别
# 调包
下载后可阅读完整内容,剩余7页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-07-13 上传
2021-11-18 上传
2021-03-25 上传
2024-10-11 上传

weixin_38733333
- 粉丝: 4
- 资源: 922
 我的内容管理
展开
我的内容管理
展开







最新资源
- PyTorch中的YOLOv3> ONNX> CoreML> iOS-Python开发
- Molten:用于zipkin和opentracing的php探针
- pandas_genomics-0.11.2.tar.gz
- W7D1-项目:CSS选择器,大O,字谜,两次和,加窗最大范围
- PyFJCore:具有NumPy支持的FastJet Core功能的Python包装器
- dotfiles:我的项目点文件
- pandas_geojson-1.0.0.tar.gz
- Python备忘单-Python开发
- 【IT十八掌徐培成】Java基础第02天-04.运算符-移位运算-逻辑运算.zip
- 装饰:PocketMine插件可为玩家购买的世界添加超棒的自定义几何!
- 层流:一种适用于多人游戏的简单,半可靠的UDP协议
- image uploader-crx插件
- Math
- Ola-Mundo:第一个Git和GitHub课程存储库
- pandas_genomics-0.12.1.tar.gz
- DGL是易于使用,高性能和可扩展的Python软件包,用于图的深度学习-Python开发
