淘宝分布式数据层:从水平分库到读写分离的发展历程
"淘宝分布式数据层的发展历程和关键技术"
淘宝分布式数据层是阿里巴巴集团在面对海量数据和高并发访问挑战时,逐步演化和发展出的一种高效、可靠的数据库架构。这个过程始于2005年,主要目的是解决数据库水平扩展、服务化以及读写分离等问题,以支持淘宝业务的快速发展。
在2005年前世阶段,淘宝开始采用水平分库策略,通过`common-dao`这一框架,实现了基于数据库标识和用户ID的路由,以减轻单一数据库的压力。然而,这种做法并未完全透明于开发人员,对应用程序的开发造成了一定影响。当时,淘宝的系统架构主要依赖于ORACLE数据库、IBM小型机和EMC高端存储。
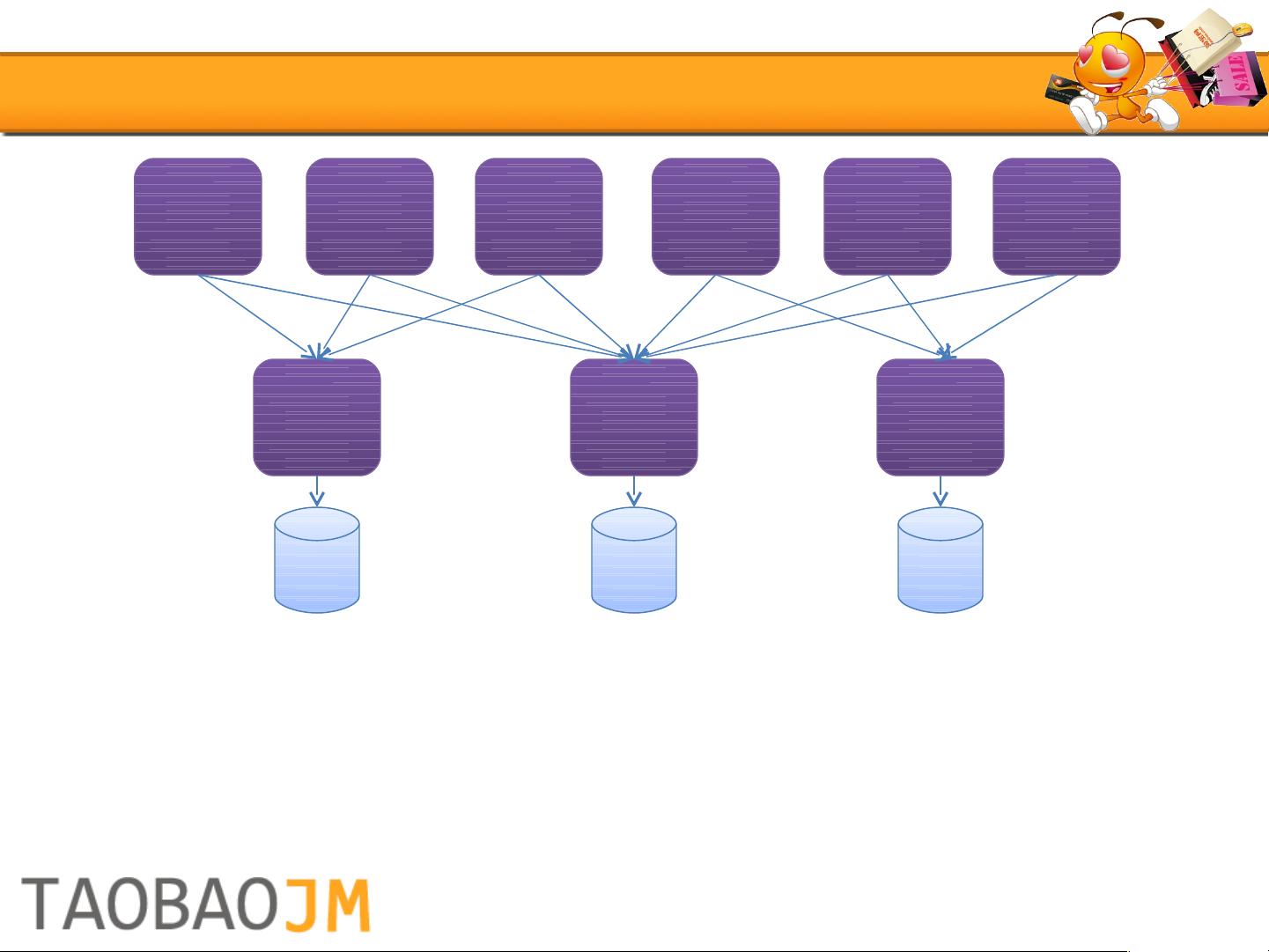
2007年,随着业务的膨胀,数据库连接数成为了一个重大问题。为了解决这个问题,淘宝引入了服务化,将重复的逻辑整合到服务中心,减少了对数据库的直接依赖。服务化提升了业务核心的稳定性和一致性,同时也催生了淘宝分布式数据层进一步发展的需求。
2008年,淘宝面临读写严重不成比例的挑战,约为18:1,这促使了读写分离技术的诞生。采用非对称数据复制,即主从复制,将读操作分散到多个从库上,以缓解主库压力。实现这一目标的方法包括解析主库日志并进行复制,或者拦截SQL操作直接复制到从库。这一策略以较低的成本解决了大部分读取请求,并尽可能地降低了对开发者的影响。
随着时间的推移,淘宝分布式数据层不断演进,不仅包括读写分离,还涉及到分片、数据一致性、故障恢复等多个方面。例如,通过动态分片策略,可以根据数据量和访问模式自动调整数据分布,以适应业务变化。同时,为了保证数据的一致性,引入了事务处理机制和数据校验策略。此外,面对节点故障,淘宝采用了冗余备份和自动切换机制,确保系统的高可用性。
在后续的发展中,淘宝分布式数据层还结合了缓存技术,如Redis和Memcached,以进一步提升读取性能。并利用数据库中间件,如TDDL(淘宝数据库访问层)进行智能路由和负载均衡,以提高系统的整体效率。
总结来说,淘宝分布式数据层是淘宝应对大数据和高并发场景的关键技术,它包括了水平分库、服务化、读写分离、数据复制、分片策略、一致性保障和高可用设计等多个层面,这些技术的综合运用使得淘宝能够处理亿级用户的在线交易,成为了业界的典范。
2007
业务
中心 1
业务
中心 2
业务
中心 3
服务化
解决了业务核心的稳定和一致的问题
解决了重要数据库的连接数的问题
也影响了淘宝分布式数据层的诞生和发展
前台
应用 1
前台
应用 1
前台
应用 1
前台
应用 2
前台
应用 2
前台
应用 2

剩余41页未读,继续阅读

huangyahui
- 粉丝: 1
- 资源: 17
 我的内容管理
展开
我的内容管理
展开







最新资源
- MitsubishiCommunication.rar
- GnssToolKit3.rar 中科微GPS定位数据操作软件
- 行业分类-设备装置-一种接收机自主完好性监视的预测方法及预测系统.zip
- python数据分析与可视化-课后学习-14-查询学员思路分析.ev4.rar
- breed-mt7620不死uboot.rar
- quest-sidenoder:适用于Quest独立耳机的跨平台Sideloader
- eibro
- OMRON NJ/NX系列PLC 指令基准手册 基本篇
- 行业分类-设备装置-一种拉锁式建筑墙板及一种制作拉锁式建筑墙板时使用的拉锁键.zip
- angular_viaticos:SPA前端Viáticos
- AutoNSCoding:使 NSCoding 协议自动化
- Erlang Windows 64位 安装包
- MetaDomain:短序列的蛋白质结构域分类-开源
- atividades_godot
- 一阶二阶一致性多成员的编队实现例子,用MATLAB实现(都是之前做毕设收集的例子)
- QuickQuotes
