视频理解新进展:视频标题与描述生成研究
版权申诉
DOCX格式 | 4.24MB |
更新于2024-06-27
| 112 浏览量 | 举报
"从视频到语言 视频标题生成与描述研究综述"
视频标题生成与描述是计算机视觉领域的一个重要研究课题,旨在将视频内容转化为自然语言文本,提供一种结构化的视觉内容概述。这一任务的核心在于理解和抽象视频的时空信息,包括识别静态元素如物体、场景、人物,以及动态元素如动作和事件,并能准确地描述这些元素在时间和空间中的变化。由于视频包含的时间连续性和多维度语义,这项任务比图像描述更复杂,对技术和算法的要求更高。
在早期的研究中,研究人员依赖于手动设计的特征,如SIFT(尺度不变特征变换)和HOG(方向梯度直方图)。这些特征用于统计分析视频内容,提取语义特征,并通过机器学习方法来识别和组织这些特征,生成描述性文本。然而,这种方法的局限性在于生成的句子可能不够自然和准确,因为它们依赖于预定义的模板或规则。
随着深度学习的兴起,特别是深度卷积神经网络(DCNN)的发展,视频特征提取的能力得到了显著提升。DCNN可以从原始视频数据中学习到更抽象、表达力更强的特征。这些特征随后与循环神经网络(RNN)结合,RNN以其处理序列数据的能力而闻名,能够在生成的句子中捕捉到时间序列的信息。CNN-RNN框架成为了视频描述任务的标准架构,提高了生成句子的质量和语义丰富度。
进一步的研究引入了三维卷积神经网络(3D CNN),这种网络能够更好地处理视频的时间维度,捕捉动作和事件的动态变化。结合门控机制(如LSTM或GRU),可以更有效地管理和利用长期依赖关系,使模型在生成描述时更能适应视频的连贯性。此外,一些工作还探索了注意力机制,允许模型在生成描述时关注视频中的关键部分,从而提高描述的针对性和准确性。
尽管取得了这些进展,视频标题生成与描述仍然面临诸多挑战,例如如何处理视频中的复杂交互、多模态信息融合、长时序理解,以及如何生成更自然、流畅和人类可读的文本。此外,大规模、高质量的标注数据仍然是制约模型性能的关键因素,因此数据集的建设和增强学习方法的应用也是当前研究的重点。
未来的研究可能会聚焦于更深入的跨模态理解,利用Transformer等模型来强化视觉和语言之间的交互,以及引入更多的先验知识和社会心理学原理来生成更符合人类认知的视频描述。此外,随着计算资源和技术的进步,更大规模的模型和更复杂的网络结构也将被用来解决这个领域的挑战。
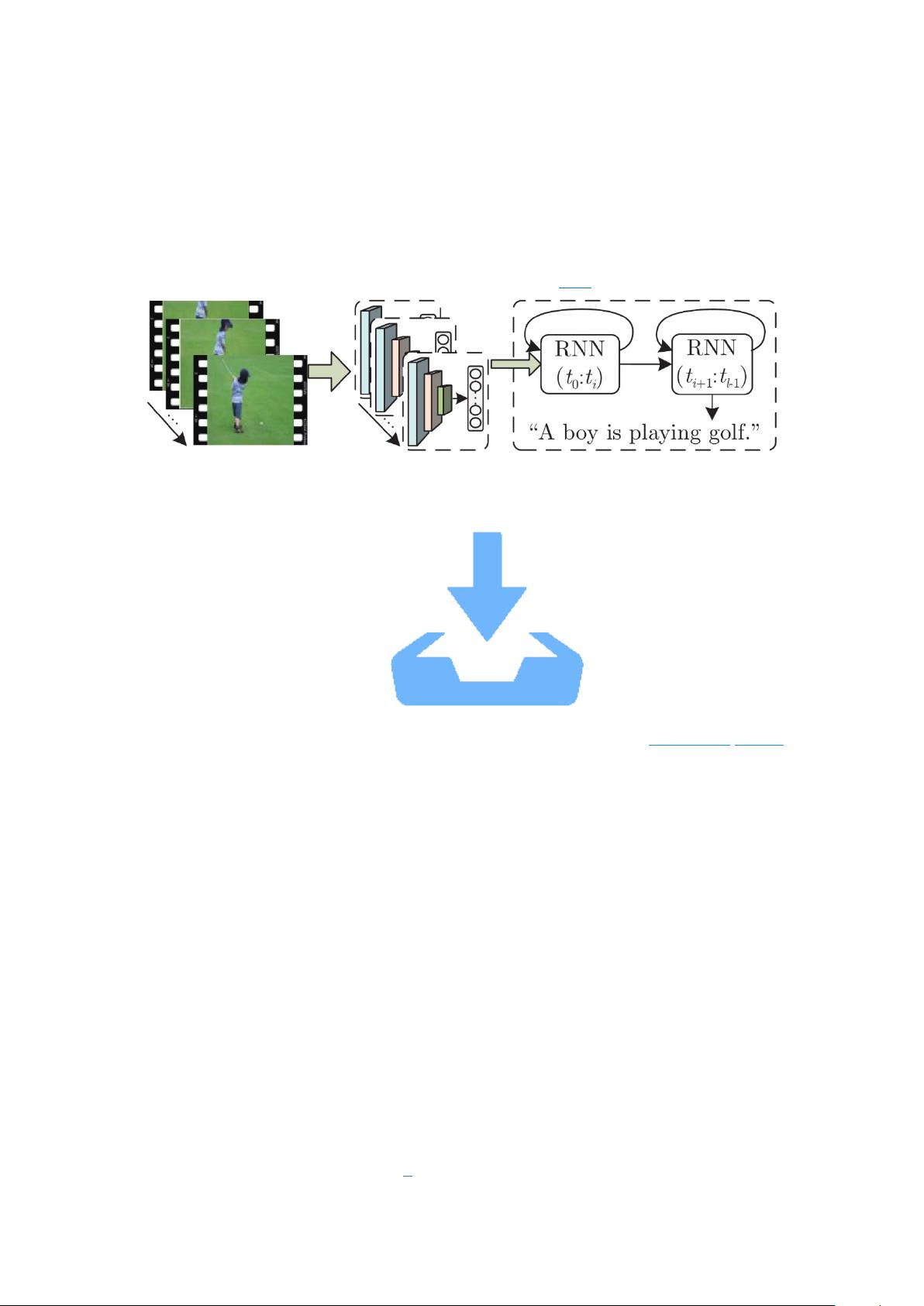
模, 设计从视频帧序列到语言词汇序列的模型框架为视频生成描述语句已逐渐成为一种新
的潮流.
序列到序列的建模方式也是起源于机器翻译, 对源语言进行特征提取的编码器和生成
目标语言的解码器使用同一个 RNN 网络, 在不同的时间步上实现各自的功能. 对于视频而
言, 其视频帧与语言具有相似的表现形式, 都具有时序特性, 因此序列到序列的建模方式应
同样适用于视频描述任务. 采用这种方法的一般模型框架如图 4 所示.
图 4 基于 RNN 序列建模的视频描述框架
Fig. 4 The RNN based framework for video captioning and description
下载: 全尺寸图片 幻灯片
2.2.1 基于 RNN 序列特征的视频简单描述
视频简单描述任务是指给定一段内容较为简单、变化相对较少的视频, 通过模型算法
对其主要内容进行高度抽象与总结, 生成句子结构、用词及语义表达都较为简单的描述语
句(一般为一段视频只生成一句话). 本节针对视频简单描述任务, 按照对视频特征的处理方
式将其分为基于视频全局特征的方法、基于视频特征选择与优化的方法及基于混合视频特
征的方法, 对相关算法与模型进行了梳理与分析.
基于视频全局特征的方法是使用 RNN 网络对视频帧序列进行建模, 将提取到的各帧
特征按顺序送入 RNN 网络中, 获取视频的时序动态特征; 然后将编码后的视觉特征送入语
言模型进行解码, 在每个时间步上逐个生成词汇, 最终组成可读的描述语句. Venugopalan
等在其设计的 S2VT (Sequence to sequence: Video to text)模型
2
中, 首先使用 DCNN 模型提
取视频帧特征和光流帧特征, 然后分别将其按顺序送入两条 LSTM 网络中, 对视频进行动
态特征编码. 所有视频帧与光流帧特征编码结束后, 模型进入解码阶段, 在每个时间步上,
将处理视频帧 LSTM 的概率输出与处理光流帧的 LSTM 概率输出进行后融合(Late fusion),
最后使用融合后的概率预测输出词汇
[32]
. 他们的工作将视觉动态特征编码与解码过程合二
剩余34页未读,继续阅读
相关推荐





罗伯特之技术屋
- 粉丝: 4558
 我的内容管理
展开
我的内容管理
展开







最新资源
- ITween插件实用教程:路径运动与应用案例
- React三纤维动态渐变背景应用程序开发指南
- 使用Office组件实现WinForm下Word文档合并功能
- RS232串口驱动:Z-TEK转接头兼容性验证
- 昆仑通态MCGS西门子CP443-1以太网驱动详解
- 同步流密码实验研究报告与实现分析
- Android高级应用开发教程与实践案例解析
- 深入解读ISO-26262汽车电子功能安全国标版
- Udemy Rails课程实践:开发财务跟踪器应用
- BIG-IP LTM配置详解及虚拟服务器管理手册
- BB FlashBack Pro 2.7.6软件深度体验分享
- Java版Google Map Api调用样例程序演示
- 探索设计工具与材料弹性特性:模量与泊松比
- JAGS-PHP:一款PHP实现的Gemini协议服务器
- 自定义线性布局WidgetDemo简易教程
- 奥迪A5双门轿跑SolidWorks模型下载
