数据库高效批量迁移:每日定时200万+数据分区转移
需积分: 5 128 浏览量
更新于2024-09-10
收藏 3.99MB DOCX 举报
"该文主要介绍了如何在工厂模式下高效地进行大规模数据的定期转移,通过采用数据库的分区策略,实现快速迁移200万条以上的数据,仅需10分钟。"
在处理大量数据时,高效的数据管理和迁移是至关重要的。工厂模式下每天定期转移海量数据通常涉及到数据的组织、存储和检索优化。在这个场景中,通过分区技术可以显著提高数据处理速度。
分区是一种数据库管理策略,它将大型表划分为更小、更易管理的部分,称为分区。这使得查询性能得到提升,因为可以针对特定分区执行操作,而不是遍历整个表。在SQL Server中,可以通过创建分区函数和分区方案来实现这一目标。
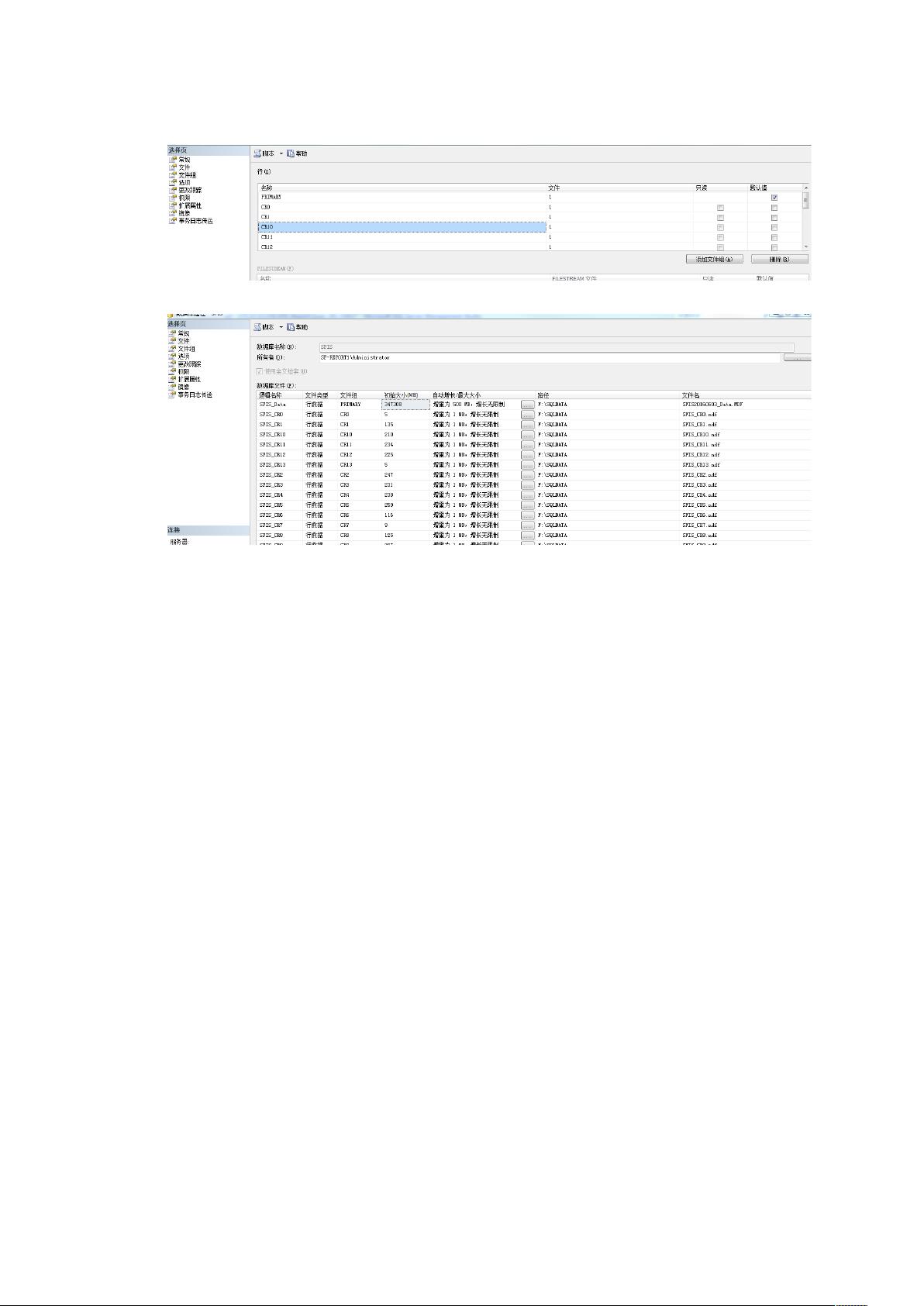
1. **创建文件组**:文件组是数据库中逻辑上的数据存储区域,可以包含一个或多个物理数据文件。在大量数据转移时,通过设置多个文件组,可以分散数据,提高I/O性能。
2. **创建文件**:数据文件是实际存储数据的地方,它们位于文件组内。增加文件数量可以提供更大的存储空间,并有助于并行处理,从而加快数据转移速度。
3. **分区函数**:分区函数定义了如何根据特定列的值将数据分配到不同的分区。在这个例子中,使用了日期时间列`operationtime`,并以一天为单位进行分区,确保每日的数据被分开存储。
```sql
CREATE PARTITION FUNCTION [DAYOrderPartitionFunction](datetime) AS RANGE RIGHT FOR VALUES
(N'2016-05-23T00:00:00.000',...);
```
上述代码创建了一个名为`DAYOrderPartitionFunction`的分区函数,它将数据按照日期范围划分,这里以每天为一个分区边界。
4. **分区方案**:分区方案则指定了如何将分区函数与文件组关联,以确定每个分区应存储在哪个文件组上。这样,当数据插入表时,会根据分区函数的规则自动分配到相应的文件组。
```sql
CREATE PARTITION SCHEME DAYOrderPartition AS PARTITION [DAYOrderPartitionFunction] TO ([CR0],...);
```
这里的`DAYOrderPartitionScheme`定义了每个分区如何映射到文件组`CR0`至`CR13`。
5. **建立分区表**:在创建分区表时,需要指定分区列,使得数据能够按照分区函数进行分布。例如:
```sql
CREATE TABLE [dbo].[sf_operation_log_day] (
[id] [bigint] IDENTITY(1,1) NOT NULL,
[sn] [varchar](20) NOT NULL,
[operationtime] [datetime] NULL CONSTRAINT [DF_sf_operation_log_operationtime_day] DEFAULT (getdate())
) ON DAYOrderPartition(operationtime);
```
这个`sf_operation_log_day`表的`operationtime`列被用来决定数据应存储在哪个分区。
6. **分区索引**:为了进一步优化查询性能,可以创建针对分区列的索引,例如创建聚集索引`IX_sf_operation_log_day_sn`,这将加速基于`sn`列的查询。
```sql
CREATE CLUSTERED INDEX IX_sf_operation_log_day_sn ON sf_operation_log_day([sn])
ON DAYOrderPartition(operationtime);
```
这样,数据不仅按照日期分区,而且通过索引使得对`sn`列的查询更加高效。
7. **导入分区数据**:最后,可以使用T-SQL语句或其他数据导入工具,将数据按日期分区插入到对应的表中。这种方法可以确保新数据按日期自动归入正确的分区,无需手动操作。
通过以上步骤,工厂模式下的大量数据转移可以实现高效、有序,并且易于维护。这种策略特别适合处理大数据量的业务系统,例如日志记录、交易数据等,可以在不影响系统运行的情况下,快速完成数据迁移和管理。
1. 建立文件组
2. 建立文件
3.分区函数
!"
#$%&'(%)($*%%+%%+%%,%%%#-#$%&'(%)($.%%+%%+%%,%%%#-#$%&'(%)(
$)%%+%%+%%,%%%#-#$%&'(%)($'%%+%%+%%,%%%#-#$%&'(%)($/%%+%%+%%,%%%#-#$%&'(
%)($0%%+%%+%%,%%%#-#$%&'(%)($1%%+%%+%%,%%%#-#$%&'(%)(*%%%+%%+%%,%%%#-
#$%&'(%)(*&%%+%%+%%,%%%#-#$%&'(%'(%&%%+%%+%%,%%%#-#$%&'(%'(
%$%%+%%+%%,%%%#-#$%&'(%'(%*%%+%%+%%,%%%#-#$%&'(%'(%.%%+%%+%%,%%%#
.,分区方案
2
%-&-$-*-.-)-'-
/-0-1-&%-&&-&$-&*
),建立分区表
3"4,567879:7;
4:&-&""-
5<=$%""-
8""
7567879:787;":
8
((分区索引
">>7567879:7;75567879:7;5
8
',导入分区数据为 567879:7; 导入数据 注意 --SET IDENTITY_INSERT [dbo].
[sf_operation_log_day] ON
(此步用于数据库大表不停机的不中断的情况下-如果服务器可以停机,可以使用如下
下载后可阅读完整内容,剩余4页未读,立即下载
123 浏览量
174 浏览量
2008-04-14 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
225 浏览量
点击了解资源详情

ocean42234111
- 粉丝: 4
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- PMSM控制和建模(FOC、SVPWM、THIPWM等)_磁场定向控制、空间矢量调制、弱磁、速度/转矩控制、电厂模型、自动校准和
- serverless-angular-user-data:ღˇ◡ˇ(ᵕ꒶̮ᵕෆ联手Anuglar,Netlify和Hasura以获得一些用户数据乐趣ღˇෆ
- 红色动态微立体创业融资计划书PPT模板
- qMedia:一个ComputerCraft程序,可用于在终端上创建动画(如Powerpoint)
- DS3232RTC:用于Maxim Integrated DS3232和DS3231实时时钟的Arduino库
- 工兵
- C-24-Box-Model
- recaptcha:[已取消] Laravel 5的reCAPTCHA验证器
- 链接5G频段wifi 显示saved,然后重复点击3次链接wifi,显示链接失败,ylog和空口抓包 抓包 8581new
- angularTools:尝试通过学习角度来做点事情
- 点击图片展开或者收起代码
- Ajax-Rails-4-AJAX-modal-form-render-JS-response-as-table-row.zip
- 简约农村三层别墅建筑设计.rar
- 魔术8球
- 蓝灰色创意公司简介PPT模板
- ESPHelper:一个使ESP8266上使用WiFi和MQTT变得容易的库
