MapReduce入门:HDFS操作与Java应用实践
需积分: 0 66 浏览量
更新于2024-06-18
收藏 2.55MB DOCX 举报
本文档主要介绍了大数据基础中的MapReduce技术以及如何在Hadoop分布式环境中进行操作。MapReduce是一种分布式计算模型,由Google开发,用于处理大规模数据集,通过将复杂的计算任务分解成一系列简单的子任务(Map阶段)并在多个节点上并行执行,然后通过Reduce阶段汇总结果。以下是文档中涵盖的主要知识点:
1. **Hadoop伪分布式环境搭建**:
在开始大数据操作之前,需要先搭建Hadoop的伪分布式环境,这是在单台机器上模拟分布式集群的行为,适合学习和测试。参考提供的《大数据基础作业》文档,该文档详细指导了如何配置和启动Hadoop,包括设置环境变量、启动守护进程等。
2. **HDFS(Hadoop Distributed File System)编程基础**:
- **创建目录**:通过HDFS命令行工具(如`hdfs dfs-mkdir`)在分布式文件系统中创建目录,如创建名为"zhangsan"的个人目录。
- **文件上传与管理**:在本地创建文件(如`test.txt`),然后使用`hdfs dfs-put`命令上传至指定目录,并验证文件是否已上传及显示目录内容。
- **文件下载**:通过`hdfs dfs-get`命令从HDFS下载文件,并检查下载后的文件是否存在。
- **文件删除**:使用`hdfs dfs-rm`删除HDFS上的文件,并确认文件已被删除。
3. **Java与HDFS交互**:
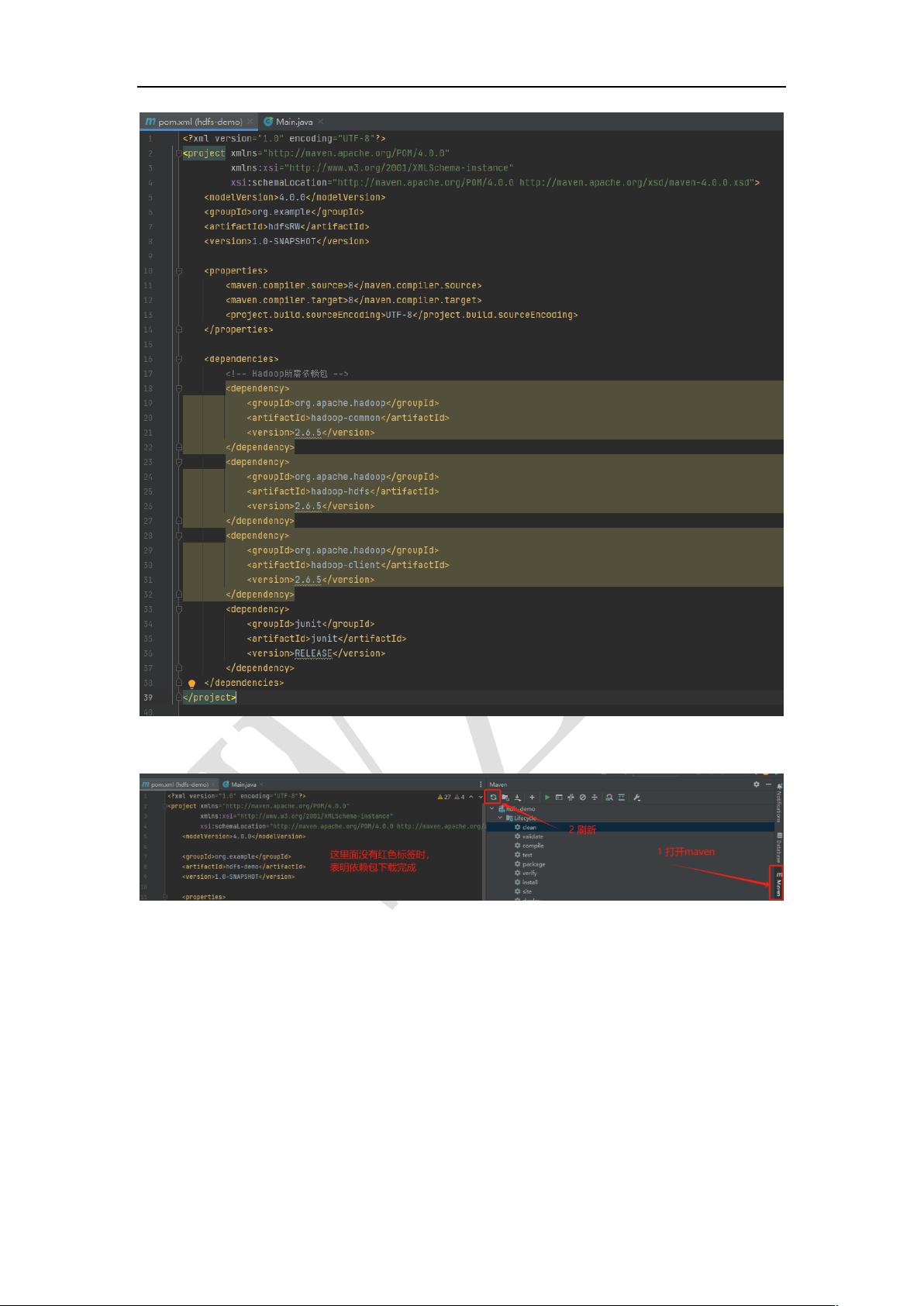
- **编写写入HDFS的Java程序**:
- 创建Java项目,更新pom.xml文件以添加Hadoop的HadoopFileSystem依赖。
- 编写`hdfsWR`类,实现将数据写入HDFS的功能,包括主类名修改和具体代码实现。
- 使用`java-jar`命令运行编译后的jar文件,并通过浏览器检查文件是否上传成功。
- **读取HDFS文件的Java程序**:
- 基于写入项目的模板,增加`hdfsRead()`函数以实现从HDFS读取文件。
- 编译并运行读取程序,观察运行结果。
4. **MapReduce编程基础概念**:
- 虽然文档没有直接提及MapReduce,但理解其原理对于大数据处理至关重要。MapReduce模型主要包括Map阶段和Reduce阶段,Map阶段对数据进行分割和预处理,而Reduce阶段则负责对中间结果进行汇总。MapReduce通常用于大规模数据的批处理,是Hadoop生态系统的核心组件之一。
通过以上内容,读者可以掌握如何在Hadoop环境下利用HDFS进行文件操作,并能够初步了解如何通过Java编程接口与HDFS交互,以及MapReduce的基本概念和使用场景。这对于深入理解大数据处理和分布式计算有着重要意义。
步骤 3:更新依赖包
剩余28页未读,继续阅读
154 浏览量
2021-09-29 上传
2024-12-14 上传
2043 浏览量
200 浏览量
2021-10-14 上传









