




入门Storm:构建实时数据处理集群
下载需积分: 1 | PDF格式 | 3MB |
更新于2024-07-17
| 10 浏览量 | 举报
"Getting Started with Storm"
《Getting Started with Storm》是一本由Jonathan Leibiusky、Gabriel Eisbruch和Dario Simonassi合著的书籍,主要介绍Apache Storm这一实时大数据处理系统的入门知识。Apache Storm是一个分布式、高可靠且容错的系统,特别适合处理连续的数据流。书中详细讲解了Storm的核心概念和技术。
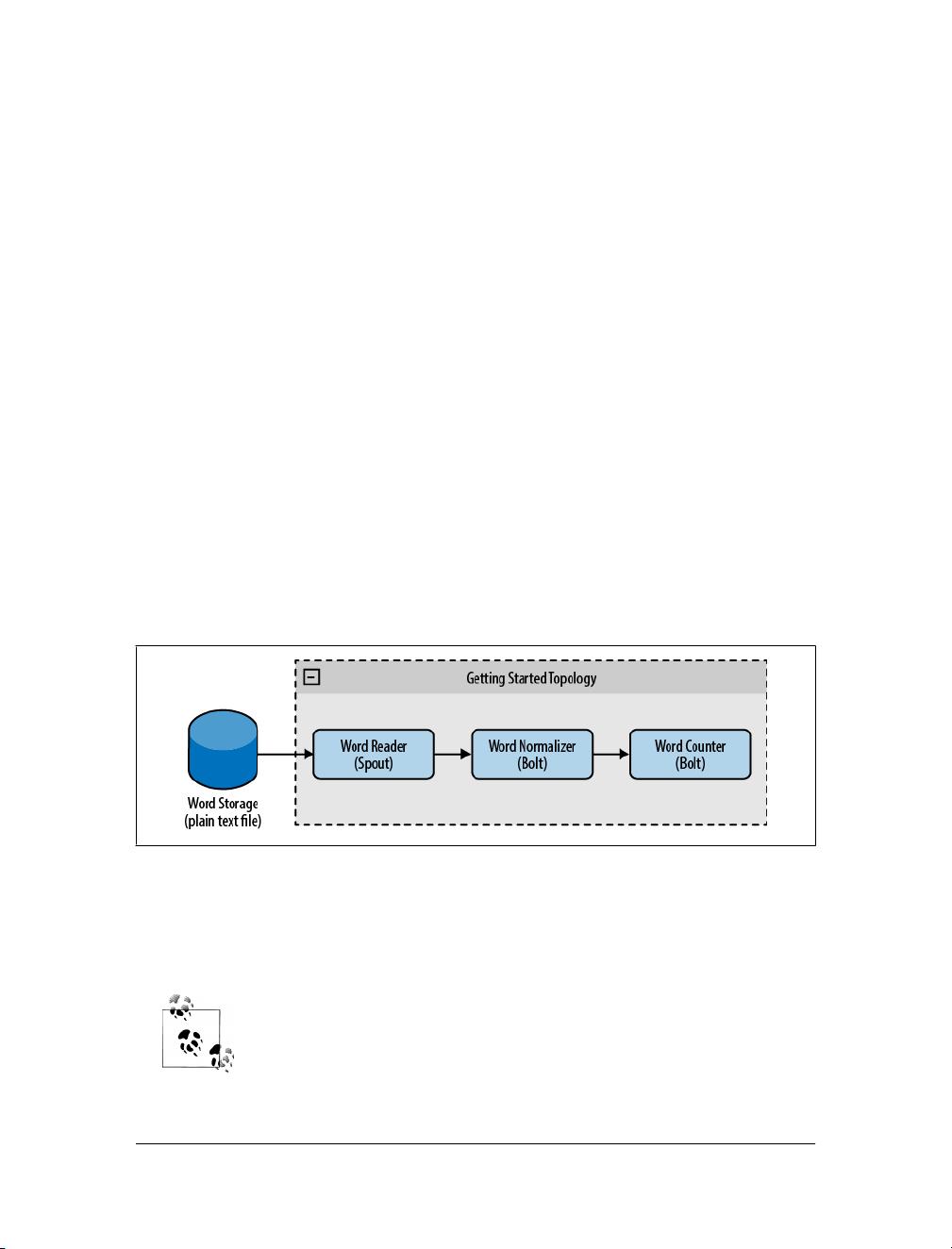
在Storm架构中,工作被分配给不同类型的组件,每个组件负责执行特定的简单处理任务。系统输入流由一个称为"spout"的组件处理。Spout接收数据并传递给名为"bolt"的组件,bolt则对数据进行转换。数据处理的过程可以理解为一系列bolt组件构成的链,每个bolt对spout提供的数据执行某种形式的转换。如果需要,bolt可以将处理后的数据存储起来,或者传递给下一个bolt继续处理。
Storm的关键特性包括:
1. **分布式**:Storm集群可以分布在全球各地的多台机器上,实现负载均衡和容错能力。
2. **可靠性**:通过确保每个消息至少被处理一次(at-least-once delivery)或精确一次(exactly-once delivery),保证数据处理的准确性。
3. **容错性**:当某个节点故障时,Storm能够自动重新分配任务,保证系统的连续运行。
Storm的工作流程通常包括以下步骤:
1. **Spout**:这是数据的来源,它可以是任何类型的数据源,如数据库、消息队列或实时传感器等。Spout将数据发布到Storm拓扑中。
2. **Bolt**:这些组件执行实际的数据处理逻辑,可以进行过滤、聚合、计算或者其他复杂的业务逻辑操作。
3. **Topology**:由spouts和bolts组成的逻辑处理图,定义了数据流的路径和处理规则。
4. **Zookeeper**:作为协调服务,管理Storm集群的状态和元数据,确保数据处理的正确性和一致性。
5. **Nimbus**:类似Hadoop的JobTracker,负责调度任务和分配工作到各个worker节点。
6. **Supervisor**:运行在每个worker节点上,接收并执行Nimbus分配的任务。
书中可能会详细讨论如何设置和配置Storm环境,创建和部署拓扑,以及监控和调试实时流处理应用程序。此外,可能还会介绍一些实际案例,展示如何利用Storm解决实际问题,如实时数据分析、社交网络分析等。
Storm的广泛应用在于实时数据分析领域,它能提供低延迟的数据处理,使得企业可以快速响应市场变化和用户行为。结合其他大数据技术(如Hadoop、Cassandra等),Storm成为了构建实时数据处理平台的重要工具。
通过学习《Getting Started with Storm》,读者可以掌握如何设计和实施高效、可靠的实时数据流处理系统,从而在大数据时代提升企业的业务效率和决策能力。

Scalable
All you need to do in order to scale is add more machines to the cluster. Storm will
reassign tasks to new machines as they become available.
Reliable
All messages are guaranteed to be processed at least once. If there are errors, mes-
sages might be processed more than once, but you’ll never lose any message.
Fast
Speed was one of the key factors driving Storm’s design.
Transactional
You can get exactly once messaging semantics for pretty much any computation.
4 | Chapter 1: Basics
www.it-ebooks.info



剩余104页未读,继续阅读
查看更多
相关推荐





lylsdu
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- VS2005 MFC控制小球躲避游戏开发教程
- AquaSetup文字捕捉工具:革新屏幕文字抓取体验
- C#中Close与Dispose方法关闭SQL数据库对比测试
- C# 2008实现数据库分组条件查询代码详解
- 深入了解ProcessHacker:高级进程管理与分析工具
- Cognizer Genius-crx插件:人工智能助手革命
- 电梯服务管理系统助力商行高效运行
- 在线任务管理插件:EFEQTI待办事项与日历组织者
- Spring集成Kafka的完整生产者与消费者配置示例
- 编译原理实验:深入理解VC词法分析技术
- Python爬虫实战教程:如何高效爬取拉勾网职位数据
- 《王巍-Swift4.0》电子书下载:iOS学习交流必备
- 探索Azkaban工作流调度器与大数据学习的集成应用
- ArcGis-10.1集成天地图Android API接口工具教程
- PowerCmd:革命性CMD增强工具
- 横河AQ7270系列仿真分析软件分享






















