Django ORM 深入理解:聚合与分组查询实战
44 浏览量
更新于2024-08-31
收藏 145KB PDF 举报
"Django ORM 聚合查询和分组查询是数据库操作中的重要概念,它们帮助开发者在处理大量数据时进行高效的统计和分析。在Django中,ORM(对象关系映射)提供了简便的方式来执行这些复杂的SQL操作。本文将详细讲解如何在Django ORM中实现聚合查询和分组查询,通过具体的示例代码帮助读者理解和应用这些功能。
首先,我们来看一下涉及到的模型。在`models.py`文件中,定义了三个模型:`Publisher`(出版社)、`Book`(书籍)和`Author`(作者)。`Book`模型与`Publisher`之间存在一对多关系,而`Author`与`Book`之间存在多对多关系。这意味着一个出版社可以出版多本书,而一本书可以由多个作者共同创作。
聚合查询允许我们对数据集进行计算,如求和、平均值、最大值等。在Django ORM中,我们可以使用`aggregate()`函数来实现聚合操作。例如,如果我们想找出所有书籍的平均价格,可以这样做:
```python
from django.db.models import Avg
books = Book.objects.all()
average_price = books.aggregate(Avg('price'))['price__avg']
```
这里的`Avg('price')`告诉Django我们想要计算`price`字段的平均值。`aggregate()`方法返回一个字典,其中键是聚合函数的别名,值是实际计算出的结果。因此,`'price__avg'`就是平均价格的别名,可以通过这个键获取到结果。
分组查询则允许我们根据某个或多个字段对数据进行分类,然后对每个类别执行聚合操作。比如,如果我们想知道每个出版社出版的书籍的平均价格,可以这样写:
```python
from django.db.models import Avg, Count
publishers_with_books = Publisher.objects.annotate(
avg_book_price=Avg('book__price'),
book_count=Count('book')
)
```
这里,我们使用了`annotate()`方法,它接受一个或多个聚合表达式作为参数。`Avg('book__price')`计算每个出版社所有书籍的平均价格,`Count('book')`计算每个出版社出版的书籍数量。这将返回一个`Publisher`对象的QuerySet,每个对象都有两个额外的属性:`avg_book_price`和`book_count`。
除了`Avg`和`Count`,Django ORM还提供了其他聚合函数,如`Sum`(求和)、`Max`(最大值)、`Min`(最小值)等。这些函数可以根据需求灵活组合,以满足各种统计分析的需求。
在实际应用中,聚合查询和分组查询经常结合使用,以提供更丰富的数据分析。例如,如果我们想知道每个出版社出版的最贵书籍和最便宜书籍的平均价格差异,可以先对每个出版社的书籍进行分组,然后计算最高和最低价格的平均值之差:
```python
from django.db.models import Max, Min, Avg
price_diffs = Publisher.objects.annotate(
max_avg_book_price=Avg('book__price', filter=Q(book__price=Max('book__price'))),
min_avg_book_price=Avg('book__price', filter=Q(book__price=Min('book__price')))
).values('name').annotate(price_difference=ExpressionWrapper(F('max_avg_book_price') - F('min_avg_book_price'), output_field=FloatField()))
```
这个例子中,我们首先通过`filter`参数对`book__price`进行了过滤,然后分别计算了最高价格和最低价格书籍的平均价格。最后,通过`ExpressionWrapper`和`F`表达式计算了这两个平均值的差,并按出版社名称分组显示结果。
Django ORM的聚合查询和分组查询功能强大且易于使用,能够帮助开发者高效地处理和分析数据库中的数据,从而提高应用的性能和用户体验。通过深入理解并熟练运用这些功能,开发者可以在构建复杂的数据驱动应用时更加游刃有余。
Django ORM 聚合查询和分组查询实现详解聚合查询和分组查询实现详解
主要介绍了Django ORM 聚合查询和分组查询实现详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有
一定的参考学习价值,需要的朋友可以参考下
models.py:
from django.db import models
# 出版社
class Publisher(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=64, null=False, unique=True)
def __str__(self):
return "<Publisher object: {}>".format(self.name)
# 书籍
class Book(models.Model):
id = models.AutoField(primary_key=True)
title = models.CharField(max_length=64, null=False, unique=True)
price = models.DecimalField(max_digits=5, decimal_places=2, default=00.00) # 最长位数为 5,小数位数为 2,默认值为 00.00
publisher = models.ForeignKey(to="Publisher", null=True) # 把 null 设置为 True
def __str__(self):
return "<Book object: {}>".format(self.title)
# 作者
class Author(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=16, null=False, unique=True)
book = models.ManyToManyField(to="Book") # 多对多关联 Book 表,ORM 会自动生成第 3 张表
def __str__(self):
return "<Author object: {}>".format(self.name)
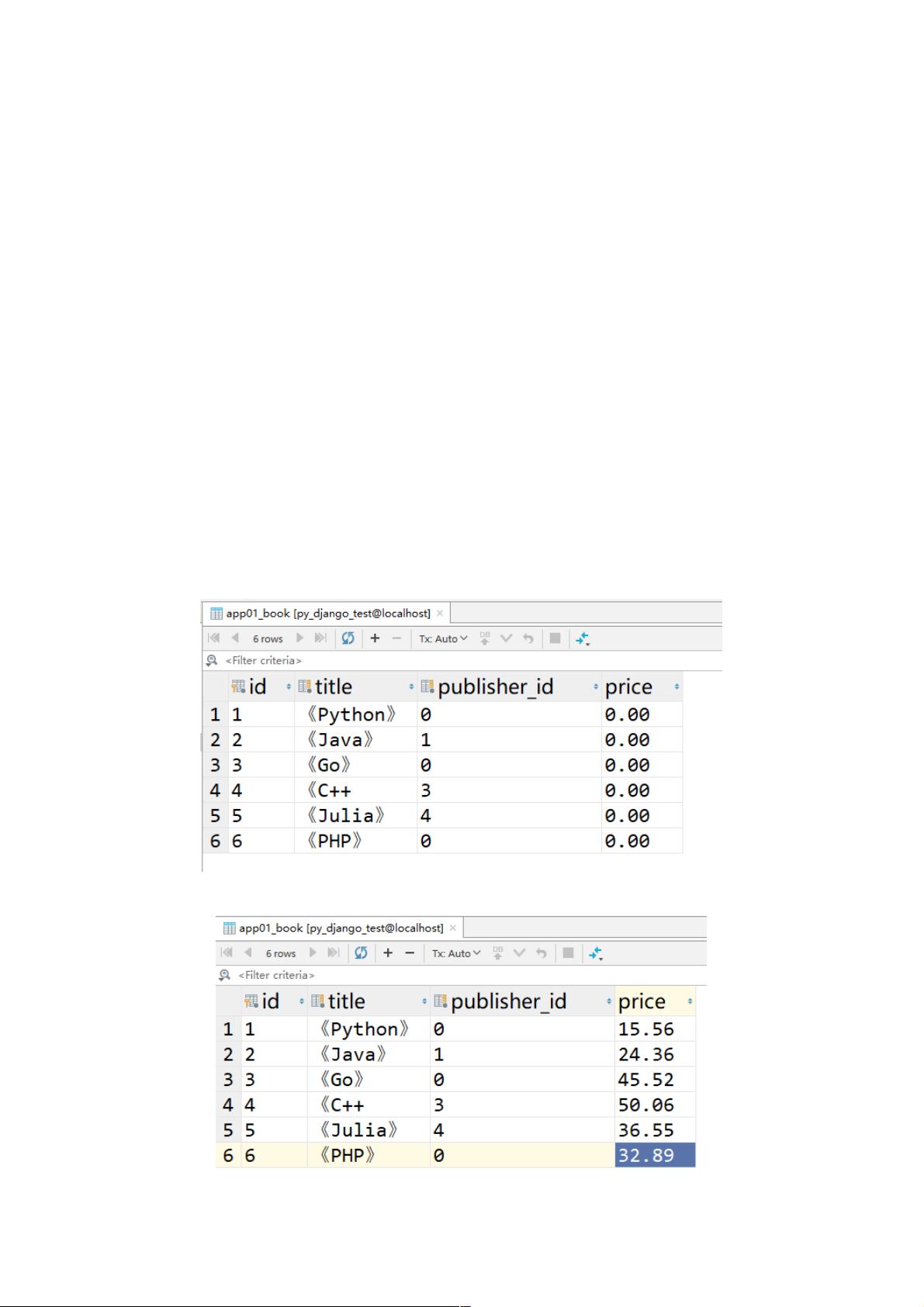
book 表:
修改 price
聚合查询:聚合查询:
aggregate():返回一个包含一些键值对的字典。
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-09-16 上传
2021-04-18 上传
2021-04-16 上传
2023-05-27 上传
2020-09-19 上传
点击了解资源详情

weixin_38504687
- 粉丝: 6
- 资源: 937
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
