Java流编程与序列化实战:文件操作与Book类应用
需积分: 10 196 浏览量
更新于2024-07-26
收藏 209KB DOC 举报
面向流的编程是Java语言中的一个重要概念,它提供了一种处理大量数据和文件操作的高效方式,尤其是在处理文本和二进制数据时。在本实验中,主要涉及的是Java流(Stream API)的运用,以及序列化(Serialization)技术的实践。
实验的主要目标是让学生深入理解Java流的工作原理和常见流的使用,包括输入流(如`FileInputStream`和`BufferedReader`)和输出流(如`FileOutputStream`和`BufferedWriter`)。同时,通过实际编程任务,学员需要掌握如何创建、检查文件夹、文件管理,以及文件的读写操作。
具体实验内容分为两个部分:
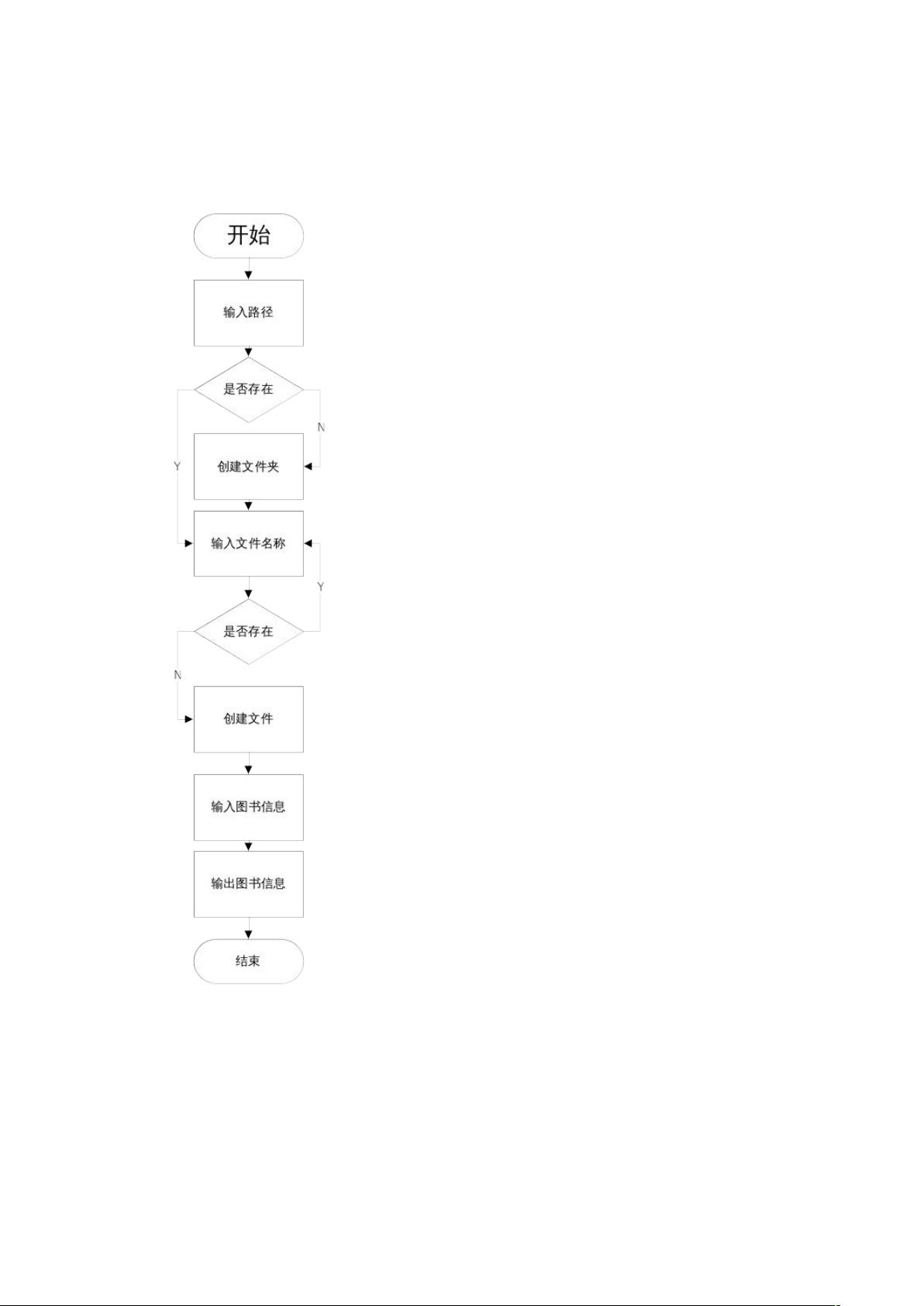
1. **基于文件流的操作**:
- 用户首先被引导输入文件路径,检查文件夹是否存在,若不存在则创建。
- 接着,用户输入文件名,确保文件名对应文件夹下不存在,避免覆盖。
- 用户录入图书信息,包括书名、出版社、价格、数量和是否教材,这些信息通过文件流以文本形式存储。
- 用户可以选择结束录入,程序读取并显示已写入文件的图书信息。
2. **基于对象流的序列化操作**:
- 在这一部分,学生需要自定义一个`Book`类,实现`Serializable`接口,用于表示图书信息。`Book`类包含属性如书名、出版社、价格、数量和教材标志。
- 使用`ObjectOutputStream`将`Book`对象写入文件,实现了对象的序列化,使得数据可以持久化保存。
- 当用户选择从文件读取时,通过`ObjectInputStream`反序列化恢复`Book`对象,然后逐行显示图书信息。
在设计思路方面,学生需考虑如何合理组织代码结构,使用流的管道操作(pipeline)来提高效率,同时利用对象流实现数据的持久性和跨进程传输。重要类`Book`的设计不仅需要遵循面向对象原则,还需要关注序列化和反序列化的兼容性。
通过这个实验,学生不仅掌握了Java流的使用,还提升了对象持久化和序列化的能力,这对于处理大数据和分布式系统至关重要。此外,他们还会了解到如何在实际项目中优雅地管理文件和数据,提升软件的可维护性和可靠性。
2、设计思路说明
剩余14页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
134 浏览量
185 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

zhangxiaoxin2
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Simple_scraper
- 行销导向式服务的认识PPT
- Elearning:在线学习
- gradle-4.10.1-all文件夹.rar
- ImageJ-Tools:核分割和比例定量
- android_magic_conch_shell:电视节目Spongebob Squarepants中的Magic Conch Shell的Android应用程序
- finiki:Finiki-以旧换新
- 井字游戏:井字游戏
- Qex Studio:从 BIM 模型创建预算-开源
- Autojs调用zxing实现扫码功能
- crud-surittec:CRUD Paraavaliaçãopela empresa Surittec
- opencv_python-3.4.4.19-cp35-cp35m-linux_armv7l.zip
- image-preloadr:将图像数组预加载到body元素底部的dom
- Praktyki2GG:Nowe repo bo tamtebyłosłabeD
- LinearAlgebra:线性代数简介的注释和python代码
- e-commerce:带有Commerce.js和Stripe.js的电子商务应用程序
