HBase基础操作指南:Shell命令与实战
下载需积分: 9 | PDF格式 | 2.3MB |
更新于2024-07-17
| 41 浏览量 | 举报
"HBase基本操作.pdf"
HBase是一款基于Hadoop的分布式数据库,它提供了对大规模数据集的随机、实时读写能力。本资源详细介绍了HBase的基本操作,旨在帮助用户掌握HBase Shell命令,包括表和列族的管理、过滤器使用、时间戳和数据版本控制以及数据批量导入等关键技能。
首先,熟悉HBase操作的常用Shell命令至关重要。通过`hbaseshell`命令,用户可以进入HBase的交互式环境。在这里,可以利用`help`命令获取所有可用的命令信息,或者使用`help '命令'`来查看特定命令的详细说明。例如,`help 'create'`将展示创建表的命令用法。
创建表是HBase操作的基础,命令格式通常是`create '表名称', '列族1', '列族2'...`。列族是HBase中数据组织的基本单元,用户可以指定一个或多个列族。例如,`create 'myTable', 'cf1', 'cf2'`会创建一个名为myTable的表,包含两个列族cf1和cf2。
接着,表和族的属性操作也是重要的学习内容。用户可以使用`alter`命令修改表结构,如添加或删除列族,调整列族的配置参数。同时,HBase支持设置表的属性,如是否开启或关闭表,以及设置表为只读等。
在数据查询方面,Filter操作允许用户根据特定条件过滤结果。例如,通过使用行键、列键或时间戳的过滤器,可以精确地定位和提取所需数据。这在处理大量数据时尤为有用,提高了查询效率。
时间戳和数据版本是HBase的特色功能。每个HBase条目都有一个时间戳,表示数据的创建或更新时间。用户可以配置数据的版本数,以保留历史记录。通过这些特性,HBase实现了数据的版本控制和时间线性读取。
最后,数据批量导入是处理大数据的关键。HBase支持使用工具如`hbase bulk load`进行批量加载数据,这通常比单条插入更高效。用户需要先将数据转换为HBase兼容的格式,然后使用`put`命令或HFile格式进行批量导入。
实验环境是Ubuntu 16.04操作系统,搭配Hadoop v2.7.3和HBase v1.2.6。通过这样的实验环境,用户可以在实践中学习并掌握上述HBase操作,提升大数据处理和管理的能力。
V1.0_20180808 第 6 页 共 27 页
北京市海淀区东北旺西路8号中关村软件园36号楼3楼 电话:010-58815892 www.sugonedu.com
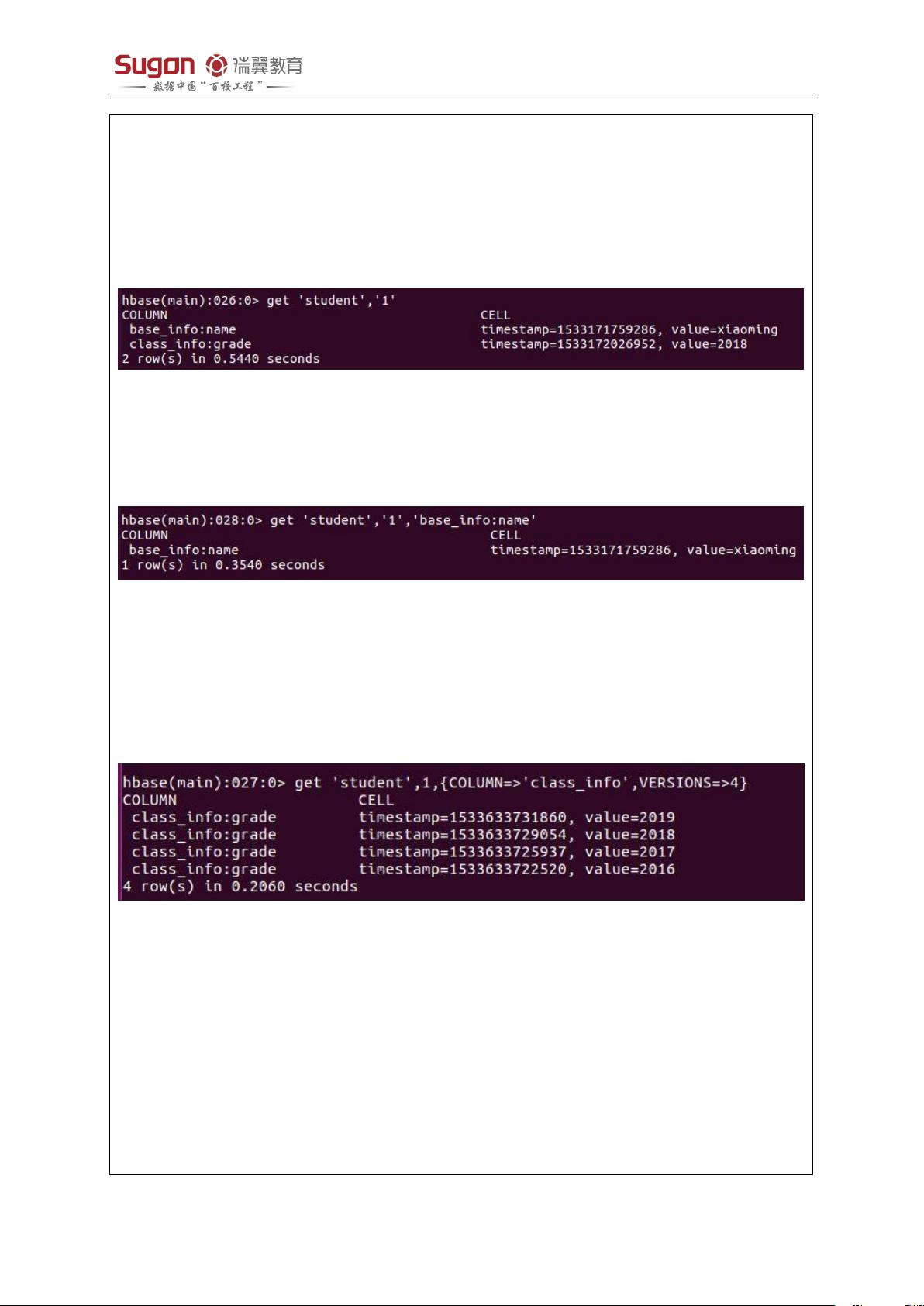
9. 获取某一行数据命令:get
命令格式 1:get '表名','行'
例如:查看表 stduent 中行 1 的数据
输入命令:get 'student','1' 按回车,显示结果如下:
命令格式 2:get '表名','行','列族:列'
例如:查看表 stduent 中行 1,列族 base_info 中列 name 的数据
输入命令:get 'student','1' , 'base_info:name' 按回车,显示结果如下:
命令格式 3:get '表名','行',{COLUMN=>'列族',VERSIONS=>版本数 n}
获取某一行的某个列族最新的 n 个版本数据。
列如:获取 student 表行 1,列族 class_info 最新 4 个版本的数据
输入命令:get 'student',1,{COLUMN=>'class_info',VERSIONS=>4}
备注:获取表数据还有很多种命令格式,请查阅帮助文档。
10. 删除制定单元格的数据命令:delete
命令格式:delete ‘表’,‘行’,‘列’,时间戳
例如:删除 student 表行 1,列族 base_info 中 name 的数据
输入命令:delete 'student','1','base_info:name',1533174244970
执行命令之前,先后利用 scan 查看表信息,结果如下
剩余26页未读,继续阅读
相关推荐




鼎上西瓜刀
- 粉丝: 173
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- ADO.NET 2.0高级编程
- 一个项目经理的经验总结(网络工程)
- 代码大全是一本成就多少程序员的书啊。
- 芯片sp3232中文介绍
- oracle9i dataguard
- 李亚非老师的神经网络教程
- 无损失”数据格式,对于500万像素的数码相机,一个RAW文件保存了500万个点的感光数据。而TIFF格式在相机内部就处理过,就好比说SONY相机以色彩艳丽著称,富士相机在人像上色彩把握很稳重等,这些都是影像处理器对色彩特别处理的结果。
- 局域网IP冲突问题的探讨
- 深入编程内幕(VC++)
- 上网速度太慢怎么办 21个全面提速技巧
- 深入浅出之正则表达式
- Weblogic管理员手册
- C++ Professional Programmer's Handbook
- MATLAB编程风格指南
- linux 进程间通信
- DHTMLandJavaScript
