"多模态大模型综述:从专家到通用助手"
 已收录资源合集
已收录资源合集
需积分: 0 62 浏览量
更新于2023-12-09
15
收藏 55.51MB PDF 举报
本报告是由微软七位华人研究员撰写的一份总结性报告,共有119页。报告主要从目前已经完善的和最前沿的多模态大模型研究方向出发,全面总结了五个具体的研究主题。这五个主题分别是视觉理解、视觉生成、统一视觉模型、LLM加持的多模态大模型和多模态agent。
报告的发起人和整体负责人是Chunyuan Li,他是微软雷德蒙德首席研究员,毕业于杜克大学,并且他的最近研究兴趣是在CV和NLP中的大规模预训练。Chunyuan Li负责了报告的开头介绍和结尾总结,以及"利用LLM训练的多模态大模型"这一章的撰写。
报告的核心作者共有四位,分别是Zhe Gan, Zhengyuan Yang, Jianwei Yang和Linjie Li。他们分别负责了剩下四个主题章节的撰写。
本报告主要介绍了多模态基础模型的发展过程,从专家模型到通用助手的转变。多模态大模型是在视觉和语言等多种模态下进行训练和生成的模型。报告提到了多个重要的研究方向和应用领域,包括图像和视频的理解和生成,统一视觉模型的构建,以及多模态智能体的发展等。
在视觉理解方面,报告介绍了通过多模态大模型实现图像和视频的语义理解、目标检测和场景理解等任务。通过训练大规模数据集和迁移学习,研究人员取得了显著的成果。
在视觉生成方面,报告介绍了使用多模态大模型生成图像和视频的方法。通过将图像生成和文本生成结合起来,研究人员能够生成具有语义和感知一致性的图像和视频内容。
在统一视觉模型方面,报告探讨了如何构建适用于多种视觉任务的统一模型。通过预训练和微调的方式,研究人员提出了一种有效的方法来提高模型的表现和泛化能力。
在LLM加持的多模态大模型方面,报告介绍了如何利用LLM(Language as a Latent Space)训练方法来提高多模态大模型的性能。通过将文本和图像进行联合训练,并将语言作为潜在空间,研究人员能够实现更好的模型性能和生成能力。
最后,报告还介绍了多模态agent的发展和应用。通过将语言、视觉和行为融合在一起,研究人员开发了多模态agent,可以在不同的任务中具有更好的理解和交互能力。
总的来说,本报告对多模态大模型的研究方向和应用领域进行了全面总结,介绍了多个重要的研究主题,并提出了一些关键的创新方法和思路。报告的撰写团队由微软的华人研究员组成,他们的工作为多模态大模型的发展和应用做出了重要贡献。

图 2.5: ImageBind(Girdhar等,2023年)提出通过利用预训练的CLIP模型,将六种模态数
据连接到一个共同的嵌入空间中, 从而实现新的紧密对齐和功能。 图片来源:Girdhar等
(2023年)。
数量通常以十亿计,而不是以百万计。以这种方式训练的视觉transformer模型的大小通
常在300M(大型)到1B(巨型)之间变化。
– 零样本预测:如图 2.4 (2)和(3)所示,通过将图像分类问题转化为检索任务,并考虑标
签背后的语义,CLIP使零样本图像分类成为可能。它还可以通过其 设计用于零样本图
像-文本检索。此外,对齐的图像-文本嵌入空间使得所有传统视觉模型都能够支持开放
词汇,并且已经激发了关于开放词汇目标检测和分割的丰富研究方向 (Li et al., 2022e;
Zhang et al., 2022b; Zou et al., 2023a; Zhang et al., 2023e)。
2.3.2 CLIP Variants
自从CLIP诞生以来,已经有大量后续研究工作致力于改进CLIP模型,如下所述。我们不
打算提供所有方法的综合文献综述,而是专注于一组选定的主题。
数 据 扩 展。 数据是CLIP训练的燃料。 例如, OpenAI的CLIP是在从Web中挖掘的4亿
个图像-文本对上训练的, 而ALIGN使用了一个包含18亿个图像-文本对的专有数据集。
在BASIC ?pham2021combined) 中, 作者仔细研究了三个维度之间的扩展情况: 批次大
小,数据大小和模型大小。然而,这些大规模数据集大多不是公开可用的,并且训练这
样的模型需要大量的计算资源。
在学 术 环 境 中, 研究 人员?li2022elevater) 推 荐 使 用 数 百万个图 像-文 本 对 进 行模型
预训练, 例如CC3M ?sharma2018conceptual), CC12M ?changpinyo2021conceptual),
YFCC ?thomee2016yfcc100m)。 公开可用的相对小规模图像-文本数据集包括SBU ?or-
donez2011im2text), RedCaps ?desai2021redcaps) 和WIT ?srinivasan2021wit)。 大规模公
开可用的图像-文本数据集包括Shutterstock ?nguyen2022quality), LAION-400M ?schuh-
mann2021laion), COYO-700M ?coyo700m)和LAION-2B ?schuhmann2022laion)等,仅
举几例。 例如, LAION-2B ?schuhmann2022laion) 已被研究人员用于研究CLIP训练的可
重现的扩展规律?cherti2023reproducible)。
有趣的是,在寻找下一代图像-文本数据集的过程中,DataComp ?gadre2023datacomp)提
出了一种不固定数据集、设计不同算法的方法,而是提议使用固定的CLIP训练方法来选
择和排名数据集。 除了为CLIP训练从Web挖掘的成对图像-文本数据外, 受Flamingo引入
的交错图像-文本数据集M3W的启发, 近期已经有一些努力收集交错图像-文本数据集,
如MMC4 ?zhu2023multimodal)和OBELISC ?laurenccon2023obelisc)等。
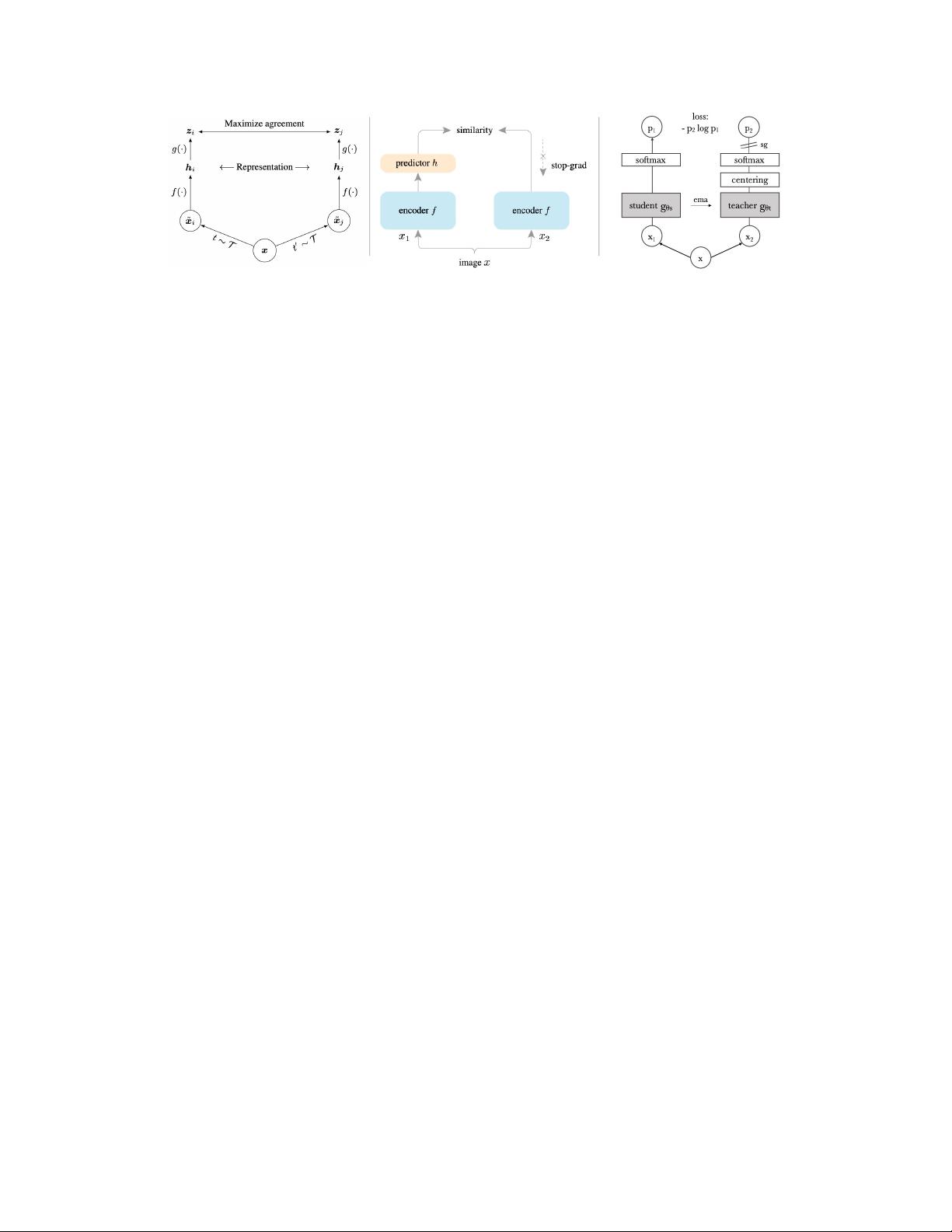
模型设计和训练方法。 CLIP 训练方面有了显著的改进。以下是一些代表性的研究。
– 图像 塔: 在图像编码器方面,FLIP (Li et al., 2023m) 提出了通过屏蔽来扩展CLIP训练的
方法。通过随机遮盖具有高遮盖比率的图像补丁,并只将可见的补丁编码,就像MAE
(He et al., 2022a)中所示,作者证明了屏蔽可以提高训练效率而不损害性能。该方法可以
16


剩余126页未读,继续阅读
855 浏览量
470 浏览量
2024-10-21 上传
496 浏览量
674 浏览量
295 浏览量

Java要加糖吗
- 粉丝: 1
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







