Spark Streaming服务:Kafka与YARN的集成实践
需积分: 9 164 浏览量
更新于2024-07-17
收藏 6.42MB PDF 举报
"SparkStreamingasaServicewithKafkaandYARN.pdf"
这篇文档是Jim Dowling在2017年SPARK SUMMIT上的演讲,主题为“Spark Streaming-as-a-Service with Kafka and YARN”。Jim Dowling是KTH Royal Institute of Technology的高级研究员,同时也是Logical Clocks AB的CEO。他探讨了Hadoop的发展历程,特别是如何通过YARN支持Spark Streaming,并介绍了与Kafka结合实现自助式UI服务的实践。
Hadoop的演变:
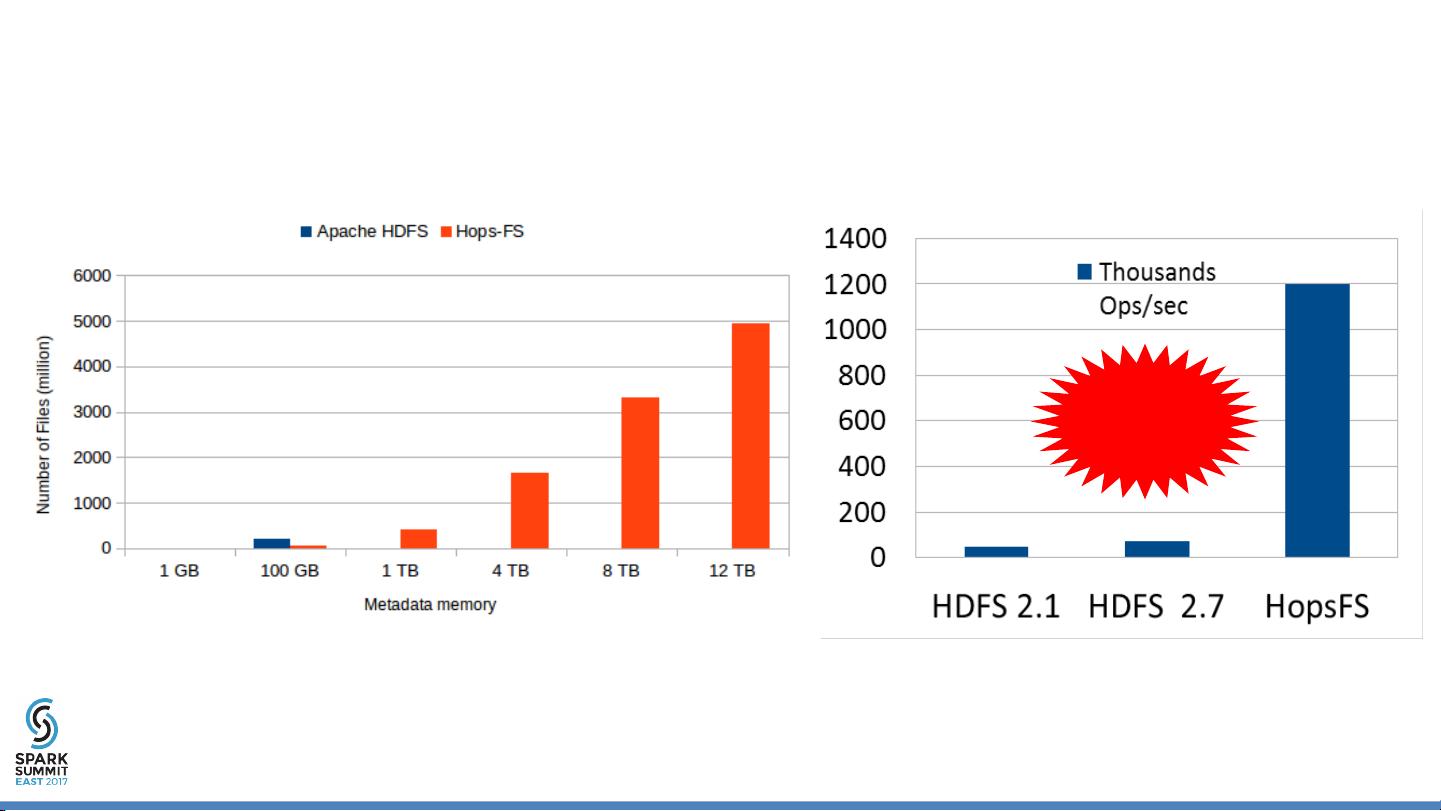
在2009年,Hadoop主要由NameNode(小型大脑)和大量的DataNodes(巨大身体)组成,负责数据存储和处理。随着时间的推移,Hadoop的架构进行了改进,通过引入外部弱一致性元数据服务来增强其"大脑"(例如,NameNodes、NDB)。这种“Google-Glass”方法提升了Hadoop的智能性,使得NameNodes的数量增加,从而实现了超过37倍的容量提升和16倍的吞吐量增长。HopsFS是基于这些改进构建的,它在Spotify工作负载上的性能提高了16倍。
Hopsworks平台:
Hopsworks是基于HopsHadoop构建的数据中心研究环境,提供Spark、Flink、Kafka、Tensorflow和Hadoop等服务。这个平台旨在为用户提供一站式的大数据处理解决方案,包括项目管理、数据集/文件管理、主题管理、作业/笔记本等。用户可以方便地创建和管理Hadoop集群,进行权限控制(ACLs),并使用Kerberos进行安全认证。通过这种方式,Hadoop的"大脑"变得更聪明,能够支持更复杂的工作负载和更多的用户需求。
Spark Streaming与Kafka和YARN的结合:
Spark Streaming是Apache Spark的一个组件,用于实时流处理。它利用DStream(Discretized Stream)的概念,将连续的数据流划分为小批处理任务。YARN(Hadoop的资源管理器)则负责调度这些任务,确保在分布式环境中有效地分配计算资源。结合Kafka,一个高吞吐量、低延迟的消息中间件,Spark Streaming可以从Kafka主题中实时消费和处理数据,同时Kafka的持久化能力保证了数据的可靠性。
Spark Streaming-as-a-Service:
通过Hopsworks平台,用户可以轻松地创建和管理Spark Streaming作业,无需关心底层的基础设施。自助式UI允许用户快速设置和监控流处理任务,极大地简化了大数据应用的开发和运维流程。这种方式使得Spark Streaming成为一种即服务(aaS)的解决方案,降低了使用门槛,提高了效率。
总结来说,这篇文档重点讲述了如何通过Hadoop的进化、YARN的资源管理以及Kafka的实时数据传输,实现Spark Streaming的高效服务化。Hopsworks平台作为这一切的载体,为大数据处理提供了便捷、智能的环境,推动了云计算领域的发展。
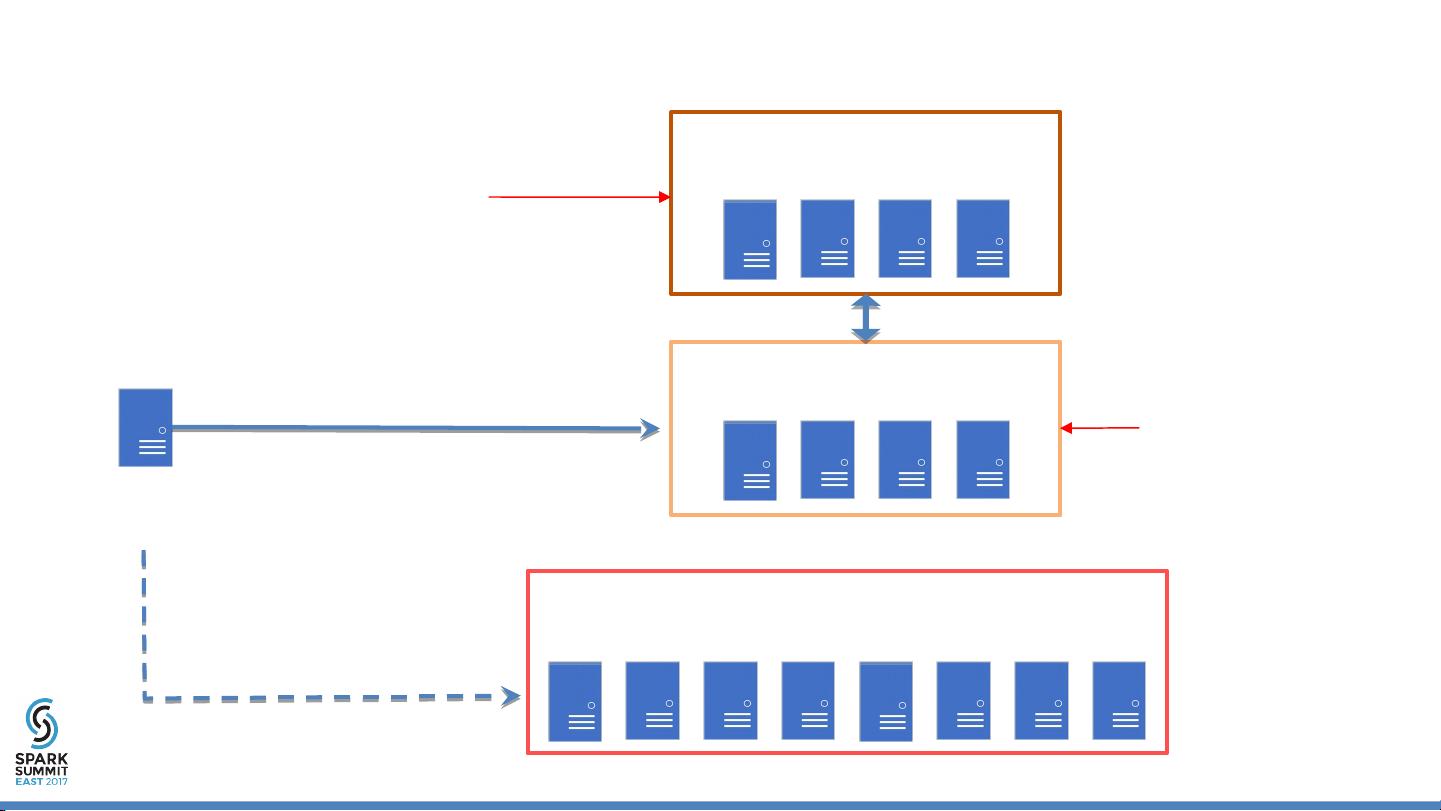
NameNodes
NDB
HDFS Client
DataNodes
>37X Capacity
>16 X
Throughput
HopsFS
剩余37页未读,继续阅读
2024-12-22 上传
2024-12-22 上传
2024-12-22 上传
2024-12-22 上传
2024-12-22 上传

weixin_38743737
- 粉丝: 376
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 编译器2
- 电子功用-多层陶瓷电子元件用介电糊的制备方法
- JLex and CUP Java based Decompiler-开源
- 管理系统系列--自动发卡系统(包含前台以及后台管理系统),对接payjs支付(无须企业认证).zip
- 整齐的块
- goit-markup-hw-03
- (课程设计)00.00-99.99 数字电子秒表(原理图、PCB、仿真电路及程序等)-电路方案
- DiskUsage.0:适用于 Android 的 DiskUsage 应用程序
- HonorLee.me:我的Hexo博客
- DZ3-卡塔琳娜·米尔伊科维奇
- 管理系统系列--智慧农业集成管理系统.zip
- 毕业设计:基于Java web的学生信息管理系统
- (资料汇总)PCF8591模块 AD/DA转换模块(原理图、测试程序、使用说明等)-电路方案
- CampaignFinancePHL:使费城的竞选财务数据更易于理解
- Week09-Day02
- JiraNodeClient:用于从Jira导出导入数据的NodeJS工具
