R语言入门指南:简单统计学与软件包simpleR
需积分: 9 174 浏览量
更新于2024-07-19
收藏 2.13MB PDF 举报
"《简单R:用于入门统计学的R语言指南》是John Verzani撰写的一本面向初学者的统计学教材辅助资料。该书旨在配合如Kitchens的《探索统计学》这样的基础教材,其目标并非详尽展示R的所有功能,也不是替代标准教科书,而是通过一个学期的课程,引导读者了解R在统计学入门课程中可以学习到的关键特性。
书中特别指出,这些笔记编写时考虑了R版本1.5.0或更高版本。作者选择使用等号(=)作为赋值运算符,而非传统的箭头组合<->,这是R在1.4.0版本中新增的功能。如果读者使用的R版本较旧,可能需要对部分内容进行调整。
书中涉及的数据和函数在使用前需要安装。对于Windows用户,这通常涉及下载特定的“zip”文件,并按照操作系统提供的指示进行安装。具体的步骤会因系统的不同而有所差异。此外,作者提醒读者在开始阅读前确保所需的参考资料已经准备就绪,以避免在学习过程中遇到不必要的困扰。
《简单R:用于入门统计学》是一本实用性强、易于理解的辅助材料,适合那些希望通过R语言入门统计学的初学者,它不仅提供了理论知识,还展示了如何将理论应用于实际数据分析中。通过这本书,读者可以掌握R的基本操作,以及如何利用R进行统计分析,从而为进一步深入学习R打下坚实的基础。"

Univariate Data page 12
The .25 and .75 quantiles are denoted the quartiles. The first quartile is called Q
1
, and the third quartile is called
Q
3
. (You’d think the second quartile would be called Q
2
, but use “the median” instead.) These values are in the R
function
RCodesummary. More generally, there is a quantile function which will compute any quantile between 0 and 1. To
find the quantiles mentioned above we can do
> data=c(10, 17, 18, 25, 28, 28)
> summary(data)
Min. 1st Qu. Median Mean 3rd Qu. Max.
10.00 17.25 21.50 21.00 27.25 28.00
> quantile(data,.25)
25%
17.25
> quantile(data,c(.25,.75)) # two values of p at once
25% 75%
17.25 27.25
There is a historically popular set of alternatives to the quartiles, called the hinges that are somewhat easier to
compute by hand. The median is defined as above. The lower hinge is then the median of all the data to the left of
the median, not counting this particular data point (if it is one.) The upper hinge is similarly defined. For example,
if your data is again 10, 17, 18, 25, 28, 28, then the median is 21.5, and the lower hinge is the median of 10, 17,
18 (which is 17) and the upper hinge is the median of 25,28,28 which is 28. These are available in the function
fivenum(), and later appear in the boxplot function.
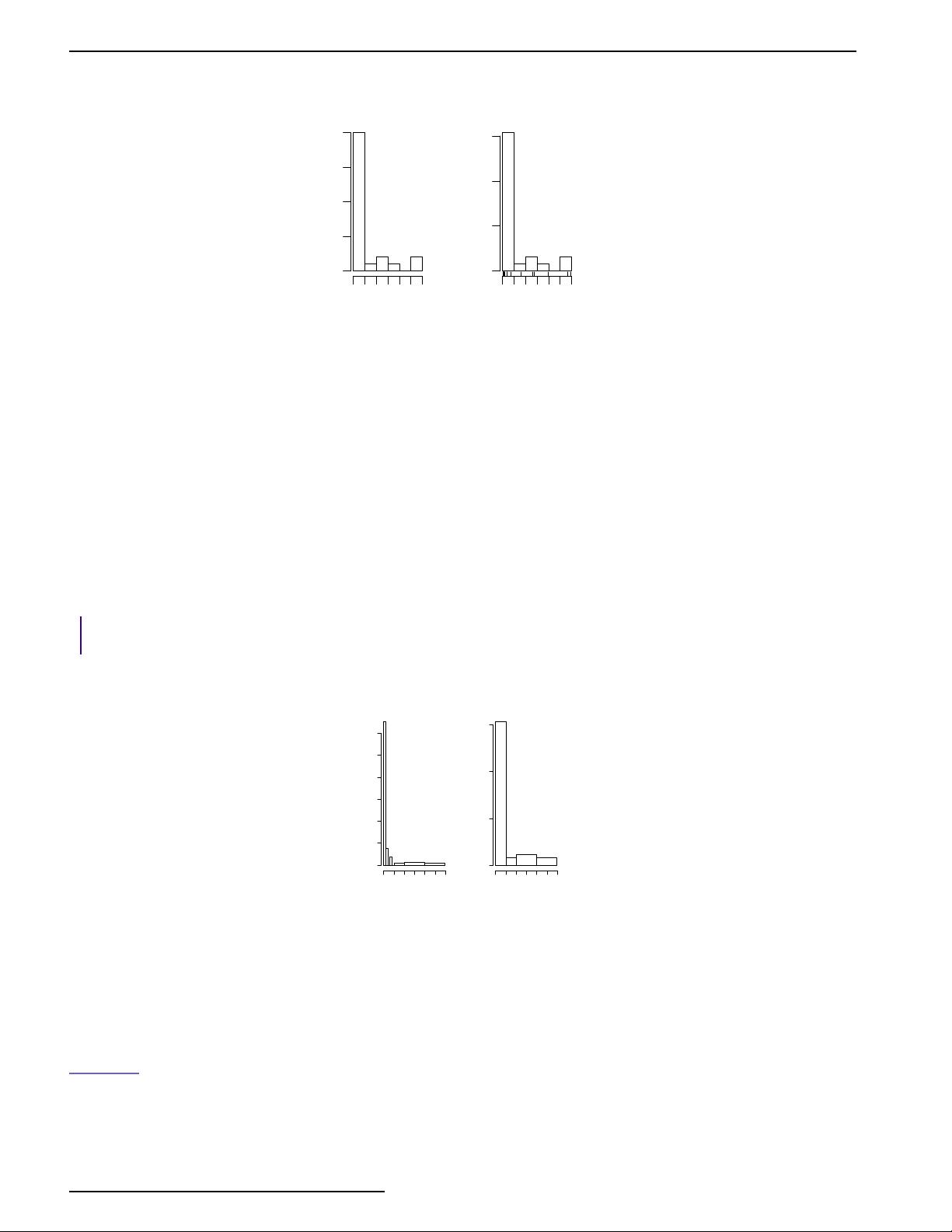
Here is an illustration with the sals data, which has n = 10. From above we should have the median at
(10+1)/2=5.5, the lower hinge at the 3rd value and the upper hinge at the 8th largest value. Whereas, the value of
Q
1
should be at the 1 + (10 − 1)(1/4) = 3.25 value. We can check that this is the case by sorting the data
> sort(sals)
[1] 0.25 0.40 1.00 2.00 3.00 4.00 5.00 8.00 12.00 50.00
> fivenum(sals) # note 1 is the 3rd value, 8 the 8th.
[1] 0.25 1.00 3.50 8.00 50.00
> summary(sals) # note 3.25 value is 1/4 way between 1 and 2
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.250 1.250 3.500 8.565 7.250 50.000
Resistant measures of center and spread
The most used measures of center and spread are the mean and standard deviation due to their relationship with
the normal distribution, but they suffer when the data has long tails, or many outliers. Various measures of center
and spread have been developed to handle this. The median is just such a resistant measure. It is oblivious to a few
arbitrarily large values. That is, is you make a measurement mistake and get 1,000,000 for the largest value instead
of 10 the median will be indifferent.
Other resistant measures are available. A common one for the center is the trimmed mean. This is useful if the
data has many outliers (like the CEO compensation, although better if the data is symmetric). We trim off a certain
percentage of the data from the top and the bottom and then take the average. To do this in R we need to tell the
mean() how much to trim.
> mean(sals,trim=1/10) # trim 1/10 off top and bottom
[1] 4.425
> mean(sals,trim=2/10)
[1] 3.833333
Notice as we trim more and more, the value of the mean gets closer to the median which is when trim=1/2. Again
notice how we used a named argument to the
mean function.
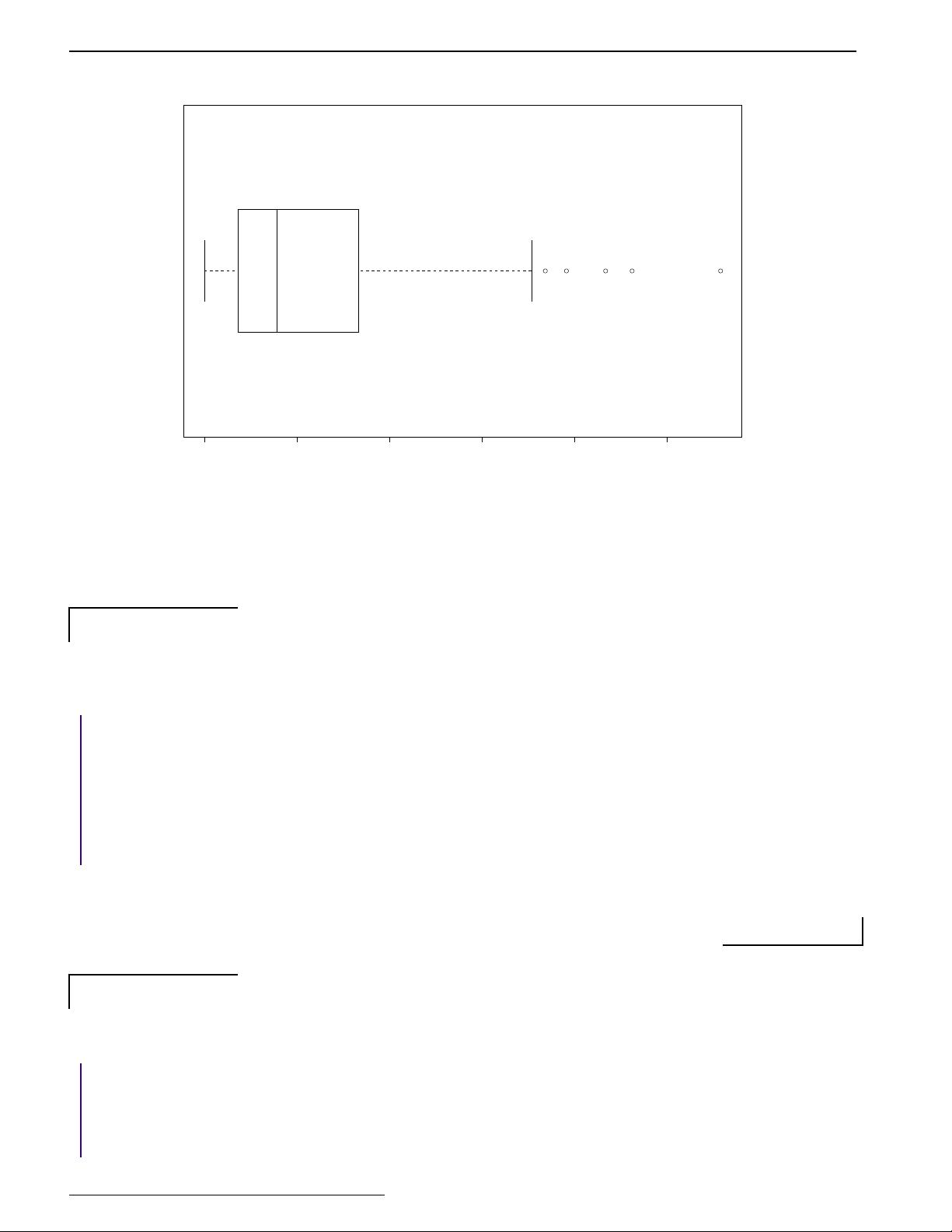
The variance and standard deviation are also sensitive to outliers. Resistant measures of spread include the IQR
and the mad.
The IQR or interquartile range is the difference of the 3rd and 1st quartile. The function
IQR calculates it for us
> IQR(sals)
[1] 6
simpleR – Using R for Introductory Statistics


剩余113页未读,继续阅读
181 浏览量
2009-04-10 上传
197 浏览量
463 浏览量
2021-05-02 上传
2021-05-26 上传
2021-05-11 上传

zhoujb123
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- CCS3.3 CSL库在多版本兼容性应用解析
- 微机室监控机:教学管理设计装置解析
- Pagina-Web-AutoLote:自动化汽车销售平台项目
- Cocos2d-x中Lua脚本的初步使用与变量访问指南
- DZ8前端模板:Bootstrap结构,适配多设备
- inet2源码工具使用教程及训练.ppt
- Python数据分析课程:Timofey Khirianov在MIPT讲授
- Java实现JTA事务控制的示例解析
- LaBSE:实现109种语言的通用句子嵌入技术
- 实现Javascript键值对集合的Map类解析
- LabView实现WebService接口的详细操作指南
- 专业太阳高度角芯片助力太阳能开发
- TensorFlow 2实现自适应梯度剪切技术AGC教程与应用
- 桶型基础独柱结构设计:带压载罐支撑平台解决方案
- LabVIEW数据库访问实例教程完整可用
- Flutter在线商店暗黑风格UI启动套件
