MongoDB聚合实战:count、distinct、group与mapReduce详解
144 浏览量
更新于2024-09-01
收藏 139KB PDF 举报
MongoDB聚合是数据库操作中一项强大的功能,它提供了类似于SQL Server的几种常用聚合操作,包括count、distinct、group和mapReduce。在MongoDB中,这些操作有助于数据清洗、分析和汇总,使得处理大量非结构化数据更加高效。
1. **Count**:
Count函数是MongoDB中最基础的聚合操作,与C#中的count方法非常相似,用于计算文档数量或满足特定条件的文档数量。这是一个简单但实用的工具,可以帮助快速了解数据集的大小。
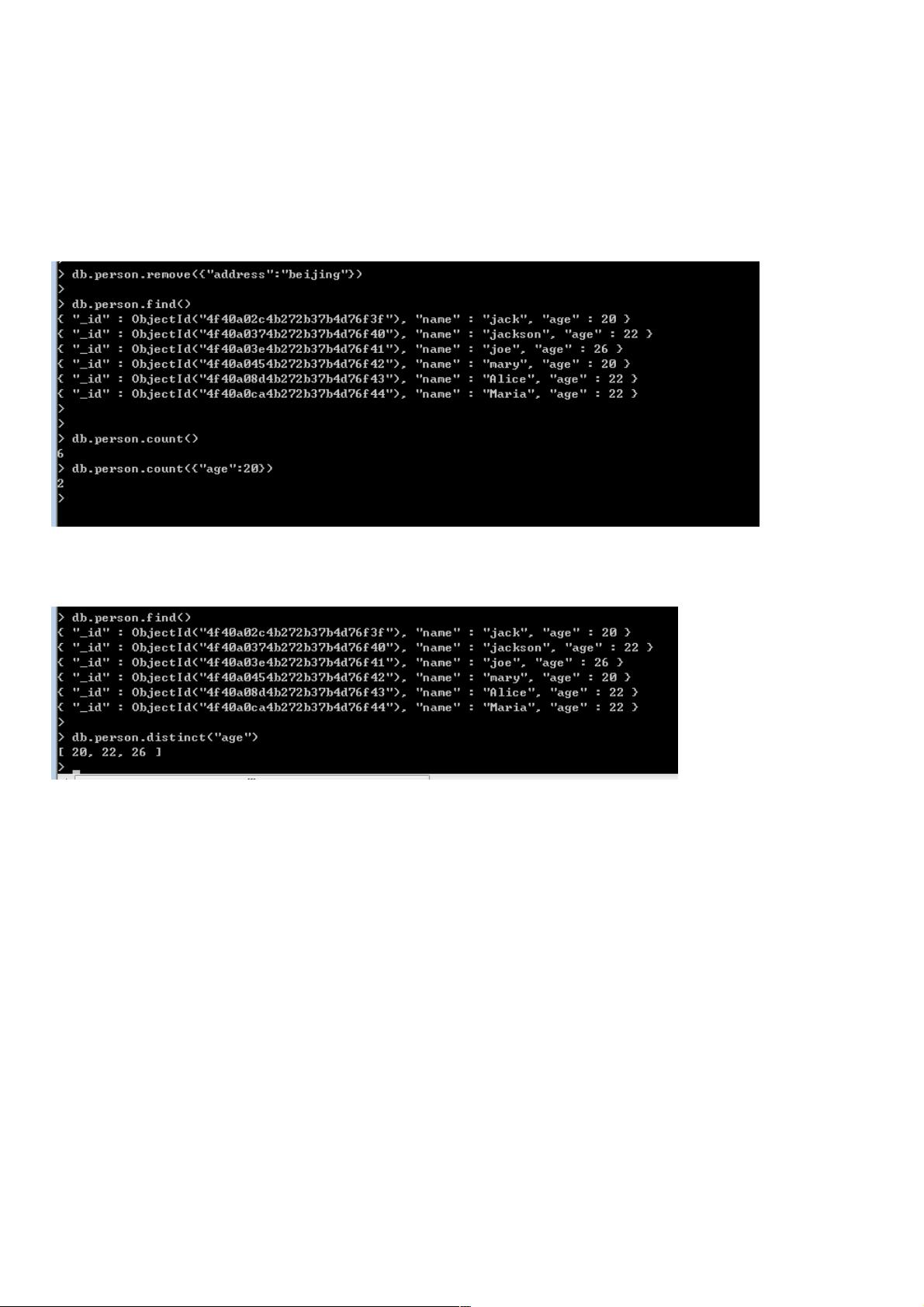
2. **Distinct**:
Distinct操作用于查找并返回集合中某个字段的唯一值,确保指定字段的值不重复。它在处理去重问题时非常有用,通常配合图示来直观展示结果。
3. **Group**:
Group是MongoDB中实现分组和汇总的关键操作。它基于指定的键(key)对文档进行分组,然后对每个分组应用一个自定义的聚合函数,如$reduce。group操作实质上构建了一个“键值对”(k-v)结构,类似于C#的Dictionary。例如,可以通过age字段分组,并计算每个年龄段的人数,还可以添加条件和finalizer函数来进一步筛选和修改结果。
- Key: 指定分组依据,如年龄(age)。
- Initial: 提供每个组的初始状态,如一个空的人员列表[],用于$reduce的第一步。
- $reduce: 是聚合的核心,接收当前文档对象和累加器对象作为参数,对文档进行处理。
4. **MapReduce**:
MapReduce是MongoDB中最复杂的聚合方法,适合分布式计算场景。它包含map和reduce两个阶段:
- Map阶段:对输入文档进行处理,生成中间结果,类似SQL的投影操作。
- Reduce阶段:对map阶段的结果进行汇总,生成最终结果,类似于SQL的聚合函数。
通过上述操作,MongoDB聚合能够帮助开发人员处理大规模数据,执行复杂的数据分析任务,提供高效的数据清洗和处理能力。理解并熟练运用这些聚合操作对于优化MongoDB应用程序性能至关重要。
mongodb聚合聚合_动力节点动力节点Java学院整理学院整理
今天跟大家分享一下mongodb中比较好玩的知识,主要包括:聚合,游标。
一:聚合一:聚合
常见的聚合操作跟sql server一样,有:count,distinct,group,mapReduce。
<1> count
count是最简单,最容易,也是最常用的聚合工具,它的使用跟我们C#里面的count使用简直一模一样。
<2> distinct
这个操作相信大家也是非常熟悉的,指定了谁,谁就不能重复,直接上图。
<3> group
在mongodb里面做group操作有点小复杂,不过大家对sql server里面的group比较熟悉的话还是一眼
能看的明白的,其实group操作本质上形成了一种“k-v”模型,就像C#中的Dictionary,好,有了这种思维,
我们来看看如何使用group。
下面举的例子就是按照age进行group操作,value为对应age的姓名。下面对这些参数介绍一下:
key: 这个就是分组的key,我们这里是对年龄分组。
initial: 每组都分享一个”初始化函数“,特别注意:是每一组,比如这个的age=20的value的list分享一个
initial函数,age=22同样也分享一个initial函数。
$reduce: 这个函数的第一个参数是当前的文档对象,第二个参数是上一次function操作的累计对象,第一次
为initial中的{”perosn“:[]}。有多少个文档, $reduce就会调用多少次。
下载后可阅读完整内容,剩余4页未读,立即下载
2020-09-09 上传
157 浏览量
2020-09-09 上传
2023-06-06 上传
2023-06-11 上传
2023-04-01 上传
2023-05-20 上传
2023-06-02 上传
2023-03-29 上传

weixin_38714761
- 粉丝: 6
- 资源: 885
 我的内容管理
展开
我的内容管理
展开







最新资源
- SIP协议中文版RFC3261
- java 程序设计教程 课后答案
- 走出ClassLoader误区
- 一种与ZigBee 802.15.4协议兼容的RF模块XBee XBee Pro及其应用
- Eclipse使用快捷键
- 基于SymbianOS C++游戏编程
- The Elements of Statistical Learning 2009年版 (高清版)
- sun-fortran 库函数参考
- 用arcgis绘制一副完整的地图
- 中文版s3c2440芯片手册第二章
- 从硬盘安装Linux操作系统
- matlab命令汇总
- JRULS在weblogic上的部署
- 英文原版J2EE官方教程
- java dom 解析 xml 实例
- ASCII码与字符转换源代码
