Kafka设计详解:高吞吐分布式消息系统
129 浏览量
更新于2024-08-27
收藏 613KB PDF 举报
Kafka是一种高性能的分布式消息系统,由LinkedIn开发并成为Apache开源项目。它以其高吞吐量、低延迟的特性,在大数据处理和日志收集等领域表现出色。Kafka的核心设计围绕以下几个关键概念:
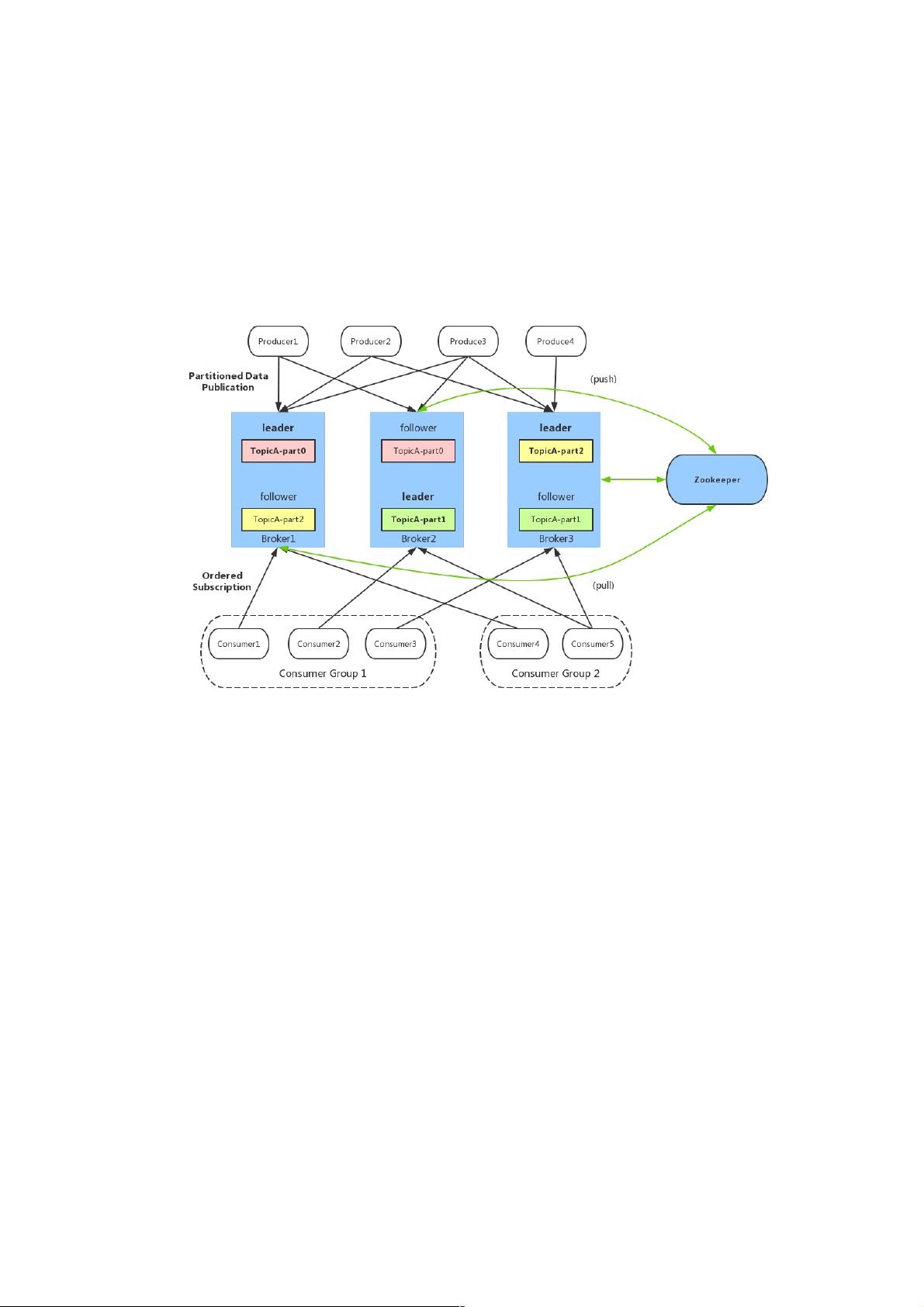
1. **Kafka架构**:
- **Broker**: Kafka服务器,扮演消息的存储和转发角色。每个broker都有多个分区(partition),每个分区对应一个独立的日志,用于持久化消息。
- **Topic**: 消息分类的抽象,Kafka通过topic组织和管理消息。消息发送到特定topic,而消费者订阅感兴趣的topic。
- **Partition**: topic的细分,每个topic可以有多个分区,提高并发处理能力和数据冗余。
- **Offset**: 用于标识消息在partition中的位置,它是消息的唯一序号,允许消费者根据需求消费从特定位置开始的序列消息。
- **Producer**: 发送消息的客户端,负责将消息发布到topic。
- **Consumer**: 接收消息的客户端,组成Consumer Group进行协同消费。
- **Zookeeper**: 作为元数据存储和协调服务,管理broker、topic和partition等配置,实现故障检测、leader选举和负载均衡。
2. **数据存储设计**:
- 数据以分区形式存储,每个分区对应一个单独的文件,文件名格式为<topic_name>-<partition_id>。
- partition内的消息由三个元素组成:offset(逻辑位置,非实际存储位置)、MessageSize(消息大小)和data(消息内容)。
- offset是消息的唯一标识符,它确保了消息的顺序性和可恢复性,即使数据丢失也能准确追踪。
Kafka的设计考虑了高效、可扩展性和可靠性。通过将数据分布在多个broker和partition上,Kafka能够处理海量数据流,同时通过Zookeeper的协调机制保持集群的稳定。这种设计使得Kafka成为现代分布式系统中不可或缺的消息传递组件,特别是在实时流处理和数据集成场景中。
Kafka设计原理设计原理
一、Kafka简介
Kafka是一种高吞吐量、分布式、基于发布/订阅的消息系统,最初由LinkedIn公司开发,使用Scala语言编写,目前是Apache
的开源项目。
跟RabbitMQ、RocketMQ等目前流行的开源消息中间件相比,Kakfa具有高吞吐、低延迟等特点,在大数据、日志收集等应用
场景下被广泛使用。
本文主要简单介绍Kafka的设计原理。
二、Kafka架构
基本概念:
broker:Kafka服务器,负责消息存储和转发
topic:消息类别,Kafka按照topic来分类消息
partition:topic的分区,一个topic可以包含多个partition,topic消息保存在各个partition上
offset:消息在日志中的位置,可以理解是消息在partition上的偏移量,也是代表该消息的唯一序号
Producer:消息生产者
Consumer:消息消费者
Consumer Group:消费者分组,每个Consumer必须属于一个group
Zookeeper:保存着集群broker、topic、partition等meta数据;另外,还负责broker故障发现,partition leader选举,负载均衡
等功能
三、Kafka设计原理
3.1 数据存储设计
partition以文件形式存储在文件系统,目录命名规则:<topic_name>-<partition_id>,例如,名为test的topic,其有3个
partition,则Kafka数据目录中有3个目录:test-0, test-1, test-2,分别存储相应partition的数据。
partition的数据文件
partition中的每条Message包含了以下三个属性:
1.offset
2.MessageSize
下载后可阅读完整内容,剩余8页未读,立即下载
2023-12-25 上传
2022-08-03 上传
2018-06-25 上传
点击了解资源详情
2021-01-27 上传
2018-03-18 上传
2022-07-09 上传
2017-04-19 上传
2022-05-07 上传

weixin_38693589
- 粉丝: 5
- 资源: 928
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
