"大数据系列-Hive入门与实战:简介、体系结构、工作机制和应用"
80 浏览量
更新于2024-01-12
收藏 1.73MB PPTX 举报
大数据系列-Hive入门与实战
总结
本文主要介绍了Hive的基本概念、历史背景、体系结构、工作机制、应用场景、安装部署以及开发使用等方面的内容。Hive是构建在Hadoop之上的数据仓库平台,它将SQL语句转译成MapReduce作业并在Hadoop上执行。
在Hive简介部分,我们了解到Hive是一个SQL解析引擎,它将SQL语句转换成MapReduce作业来执行,同时Hive表是HDFS的一个文件目录。Hive的历史由来是Facebook于2008年将其贡献给Apache,成为开源项目。目前最新版本是hive-2.0.0。
接着,我们详细介绍了Hive的体系结构。Hive的体系结构由三个主要组件组成:Hive Client、Hive Server和Hive Metastore。Hive Client是用户用来提交HiveQL查询的工具,Hive Server是处理客户端请求的服务端组件,而Hive Metastore则用来存储表的元数据。
在Hive的工作机制部分,我们了解到当用户提交HiveQL查询时,Hive会将查询转换成一系列的MapReduce作业,并在Hadoop集群上执行。Hive利用元数据来优化查询,支持对数据进行分区和分桶,并提供了查询优化器来提高查询性能。
针对Hive的应用场景,我们介绍了Hive在大数据领域的广泛应用。Hive可以用于数据仓库、ETL(抽取、转换、加载)、日志分析、数据挖掘等工作。Hive提供了类似于SQL的查询语言,使得分析师和数据科学家能够方便地进行数据分析和挖掘。
在Hive的安装部署部分,我们给出了Hive的安装步骤和配置要点。首先,我们需要安装Hadoop和Hive的依赖包,然后配置Hadoop和Hive的相关参数。最后,我们启动Hadoop和Hive服务,并验证安装是否成功。
最后一部分是关于Hive的开发使用。我们介绍了HiveQL查询的基本语法和常用操作,包括创建表、插入数据、查询数据和修改表结构等。同时,我们也提到了Hive的一些高级功能,如用户自定义函数(UDF)、批处理导入数据和动态分区等。
总的来说,Hive作为一个构建在Hadoop之上的数据仓库平台,为开发人员和分析师提供了一个方便、快速且可扩展的数据处理和分析工具。通过对Hive的学习和实践,可以有效地处理大数据,并从中获得有价值的信息和洞察。
12
Hadoop
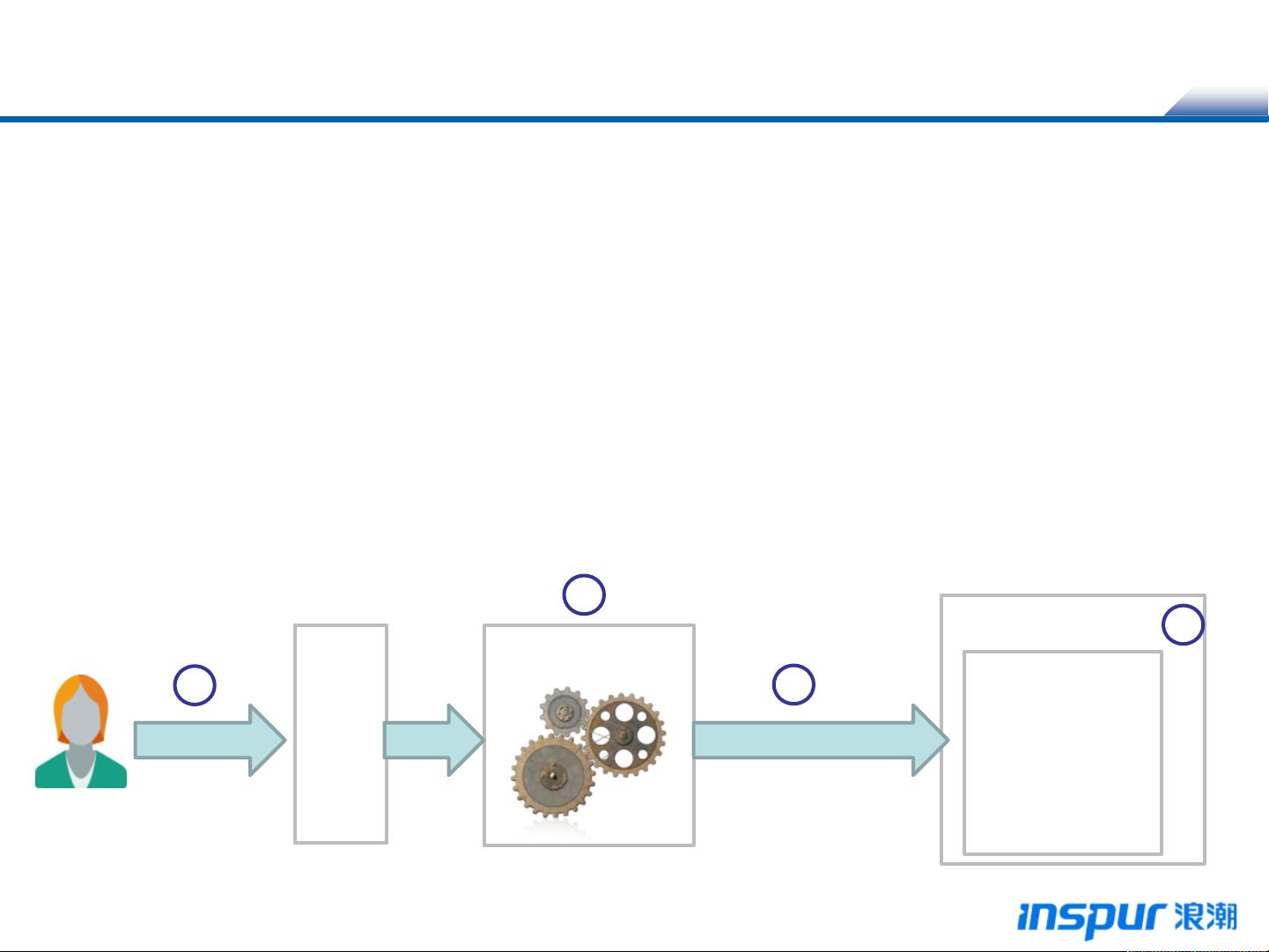
Hive的运行机制
hive
① 用户通过用户接口连接Hive,发布Hive SQL
② Hive解析查询并制定查询计划
③ Hive将查询转换成MapReduce作业
④ Hive在Hadoop上执行MapReduce作业
sql Map/Reduce
hdfs
• table1
• table2
• table3
......
用户
用户接口
1
2
3
4


剩余69页未读,继续阅读
2021-05-23 上传
2021-05-23 上传
2021-12-18 上传
2021-12-18 上传
2021-05-23 上传
2021-12-18 上传
2021-12-18 上传
2021-12-18 上传

猫一样的女子245
- 粉丝: 230
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Elasticsearch核心改进:实现Translog与索引线程分离
- 分享个人Vim与Git配置文件管理经验
- 文本动画新体验:textillate插件功能介绍
- Python图像处理库Pillow 2.5.2版本发布
- DeepClassifier:简化文本分类任务的深度学习库
- Java领域恩舒技术深度解析
- 渲染jquery-mentions的markdown-it-jquery-mention插件
- CompbuildREDUX:探索Minecraft的现实主义纹理包
- Nest框架的入门教程与部署指南
- Slack黑暗主题脚本教程:简易安装指南
- JavaScript开发进阶:探索develop-it-master项目
- SafeStbImageSharp:提升安全性与代码重构的图像处理库
- Python图像处理库Pillow 2.5.0版本发布
- mytest仓库功能测试与HTML实践
- MATLAB与Python对比分析——cw-09-jareod源代码探究
- KeyGenerator工具:自动化部署节点密钥生成
