吴恩达机器学习笔记:监督与无监督学习详解
需积分: 0 147 浏览量
更新于2024-06-17
收藏 24.11MB PDF 举报
吴恩达的机器学习课程笔记涵盖了机器学习的基础概念和发展历史。早期,Arthur Samuel(1959年)将机器学习定义为计算机在无明确指令下自我学习的能力,而Tom Mitchell(1998年)则进一步阐述为程序通过经验和反馈改进执行任务的能力。机器学习的核心分为监督学习和无监督学习两大类。
监督学习是机器学习的基石,它依赖于有标签的数据集进行训练,目标是预测未知数据的标签。常见的监督学习算法包括KNN、朴素贝叶斯、支持向量机(SVM)、决策树、随机森林和神经网络(如BP)。这些算法广泛应用于垃圾邮件分类、心脏病预测等场景,通过不断调整模型参数以提高预测准确性。
在无监督学习中,数据集没有预先提供的标签,算法需要自行发现数据的内在结构和规律。无监督学习的应用包括降维技术,如主成分分析(PCA)和独立成分分析(ICA),它们可以减少数据的复杂性,便于数据分析和可视化。聚类算法,如K均值和层次聚类,是无监督学习的重要组成部分,用于发现数据中的自然群组,帮助揭示数据的内在组织。此外,异常检测也是无监督学习的应用之一,通过识别数据集中的异常值或异常模式,可以应用于金融监控和网络安全等领域,提升系统的稳定性和安全性。
吴恩达的机器学习自做笔记强调了学习过程中理论与实践相结合的重要性,无论是监督还是无监督学习,都要求学习者理解和掌握如何有效地从数据中提取有价值的信息,并将其转化为实际问题的解决方案。

利 用 三 次 函 数 模 型 与 数 据 集 进 行 拟 合
使 用 多 元 线 性 回 归 的 方 法 , 用 假 设 函 数 来 拟 合 数 据 。
下 面 讨 论 使 用 三 次 函 数 模 型 来 拟 合 数 据 。
例 要 进 行 预 测 房 子 价 格
表 示 用 房 子 面 积 房 子 面 积 的 平 方 房 子 面 积 的 立 方 。
中 的 、 、 均 为 输 入 特 征 。
把 和 两 者 关 联 起 来
把 特 征 设 置 为 房 子 面 积 , 把 特 征 设 置 为 房 子 面 积 的 平 方 , 把 特 征 设 置 为 房 子 面 积 的 立 方
即 设 、 、
再 用 线 性 回 归 方 法 ,
就 可 以 拟 合 这 个 三 次 函 数 模 型 到 数 据 集 上
如 像 上 述 那 样 设 置 特 征 、 、
特 征 : 房 子 面 积 范 围 大 小 在 到 之 间
特 征 : 房 子 面 积 的 平 方 的 范 围 大 小 就 在 到 一 百 万 的 平 方 之 间
特 征 : 房 子 面 积 的 平 方 的 范 围 大 小 就 在 到 的 次 方 之 间
可 以 看 出 上 述 个 特 征 的 范 围 相 差 很 大 , 因 此 此 时 使 用 梯 度 下 降 法 的 话 , 那 么 运 用 特 征 缩 放 就 显 得 更 加 尤 为 重 要 了
之 前 所 述 的 二 次 函 数 模 型 拟 合 数 据 并 不 是 很 理 想 , 因 为 二 次 函 数 模 型 拟 合 数 据 到 最 终 曲 线 会 下 降 , 曲 线 会
下 降 即 意 味 着 房 子 面 积 增 加 的 情 况 下 房 子 价 格 反 而 下 降 的 情 况 , 这 是 使 用 二 次 函 数 模 型 不 理 想 的 地 方 。 因 此 采 用 三 次 函 数 模 型
来 拟 合 数 据 。 当 然 除 了 使 用 三 次 函 数 模 型 之 外 , 还 可 以 通 过 其 他 模 型 来 进 行 拟 合 。
如 : 。 表 示 求 房 子 面 积 的 平 方 根 。
表 示 预 测 的 房 子 价 格 房 子 面 积 房 子 面 积 的 平 方 根 。
那 么 该 函 数 的 曲 线 趋 势 上 升 到 一 定 程 度 之 后 便 慢 慢 变 得 平 缓 , 曲 线 最 终 也 不 会 下 降 的 , 最 多 也 只 会 缓 慢 上 升 。
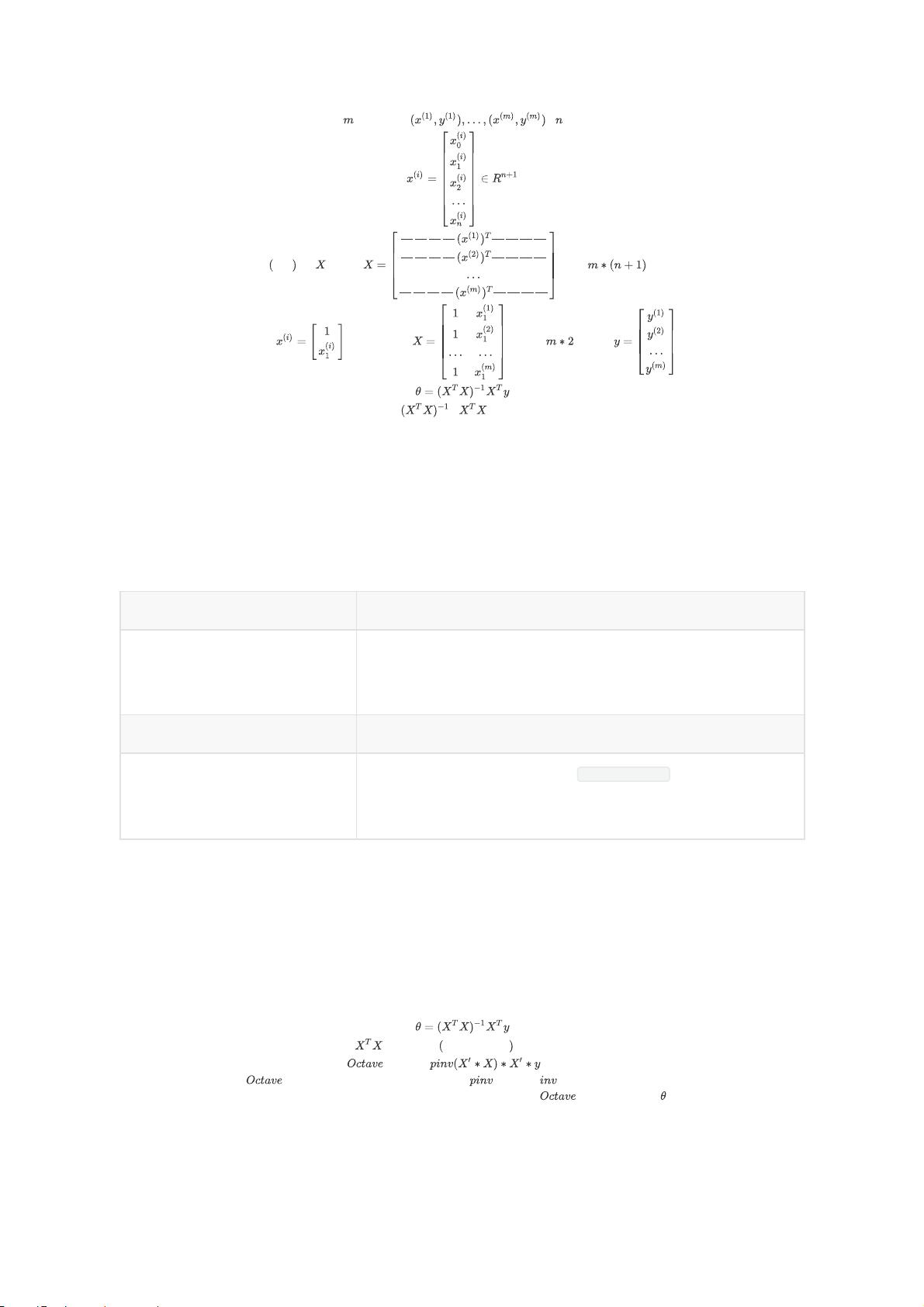
正规方程(区别于迭代方法的直接解法)
为了求出最优解θ,假如θ是个实数,我们可以求导,令导数等于0得到θ。
但是这里θ是一个N维向量,可以运用微积分的知识,分别对θ1,θ2,θ3,...,求偏导数令其为0得到最
优解。
正规方程提供了一种求θ的解析方法,不需要再像之前梯度下降算法那样运行迭代算法,而是可以直接
一次性求解θ的最优值,即只需要一步就可以得到最优值。
假 设 有 一 个 非 常 简 单 的 代 价 函 数 : ( 这 里 的 是 一 个 实 数 )
可 以 利 用 对 求 导 , 然 后 令 的 导 数 等 于 即 可 得 到 令 最 小 的 值 。
在目前所探讨的问题中,θ不是一个实数,而是一个n+1维的参数向量
对 每 一 个 都 求 偏 导 , 并 令 其 偏 导 为 , 求 对 应 的 的 值
举一个m=4的例子,构建一个矩阵X
是 一 个 维 矩 阵 , 是 一 个 维 向 量
为 训 练 样 本 数 量 , 是 特 征 变 量 数 , 其 实 是
剩余51页未读,继续阅读
2019-04-26 上传
2022-04-13 上传
2018-07-31 上传
2018-11-28 上传
2023-11-14 上传

彷徨迷离
- 粉丝: 6
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于Python和Opencv的车牌识别系统实现
- 我的代码小部件库:统计、MySQL操作与树结构功能
- React初学者入门指南:快速构建并部署你的第一个应用
- Oddish:夜潜CSGO皮肤,智能爬虫技术解析
- 利用REST HaProxy实现haproxy.cfg配置的HTTP接口化
- LeetCode用例构造实践:CMake和GoogleTest的应用
- 快速搭建vulhub靶场:简化docker-compose与vulhub-master下载
- 天秤座术语表:glossariolibras项目安装与使用指南
- 从Vercel到Firebase的全栈Amazon克隆项目指南
- ANU PK大楼Studio 1的3D声效和Ambisonic技术体验
- C#实现的鼠标事件功能演示
- 掌握DP-10:LeetCode超级掉蛋与爆破气球
- C与SDL开发的游戏如何编译至WebAssembly平台
- CastorDOC开源应用程序:文档管理功能与Alfresco集成
- LeetCode用例构造与计算机科学基础:数据结构与设计模式
- 通过travis-nightly-builder实现自动化API与Rake任务构建
