知识图谱:关系抽取详解—从规则到深度学习
版权申诉
128 浏览量
更新于2024-06-28
收藏 3.06MB PDF 举报
本章主要探讨了知识图谱中的关键环节——关系抽取,它是知识图谱构建与信息抽取的重要组成部分。关系抽取的目标是从文本中提取实体对之间的语义关系,这在构建和补全知识库时发挥着至关重要的作用。关系抽取可以根据任务的性质被分为不同的类别:
1. **关系抽取概述**:首先介绍了关系抽取的基本概念,即从文本中识别出实体对间的关联,这些实体对可能是预先设定的,也可能是通过命名实体识别(NRE)技术自动生成的。
2. **基于Rule的关系抽取**:这种方法依赖于预设规则来匹配和识别特定模式,适用于具有明确模式或模板的情况。
3. **基于有监督的关系抽取**:这种方法需要大量的标注数据进行模型训练,通过机器学习算法对文本进行分析,学习实体间关系的特征。
4. **基于bootstrapping的关系抽取**:这是一种半监督学习策略,通过初始种子关系不断迭代扩大知识库,逐步提高抽取的准确性。
5. **基于远程监督的关系抽取**:利用现有知识库作为监督信息,即使没有直接的标注文本对,也能进行关系抽取。
6. **开放关系抽取**:强调直接从文本中抽取无固定形式的结构化关系,如OpenIE,它关注的是文本中的自由形式关系表述。
7. **关系抽取的分类**:按照关系是否预定义,关系抽取可分为关系分类(如Person-Affiliation)和开放关系抽取。前者将抽取视为分类问题,后者则更侧重于发现文本中的新关系。
8. **挑战与困难**:关系抽取面临的主要挑战包括关系隐式性(如“特朗普执掌着美国的行政大权”),关系多样性(如多种方式表达同一关系),以及缺乏高质量的训练样本。人工标注的困难也是需要克服的问题。
关系抽取作为知识图谱建设中的核心技术,其进步直接影响着知识表示的准确性和可用性,因此,研究者们持续探索和改进各种方法,以提高关系抽取的效率和准确性,这对于智能问答、信息检索等应用场景具有重要意义。
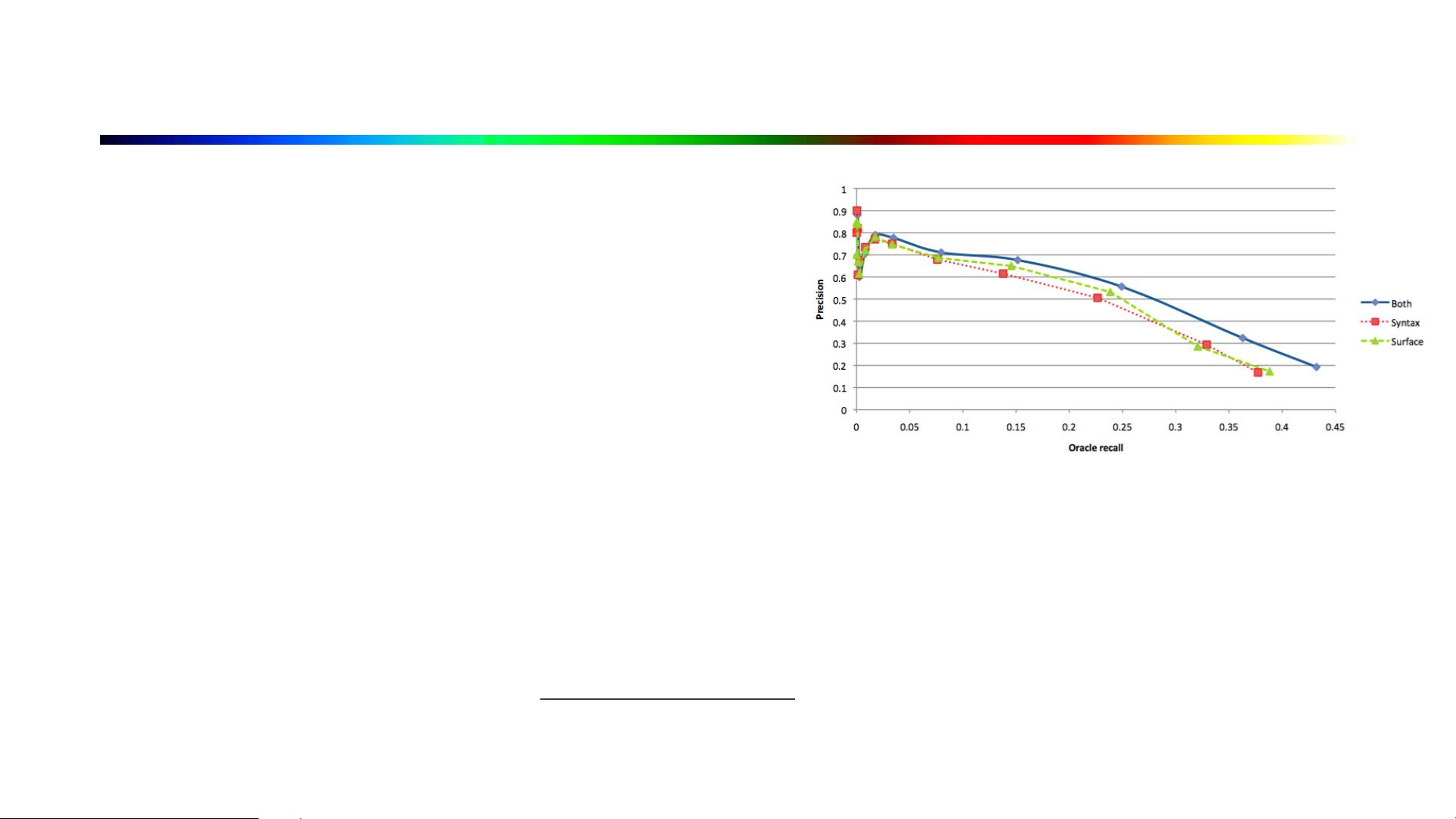
1.7 评估方法
• 自动评估(held-out evaluation)
• 比较模型预测的结果和测试集中的标准值来判断对错
• 人工评估(human evaluation)
• 通过多数投票的方法对预测的关系进行评估
• 度量标准
• 精确率(precision),准确率(accuracy)和召回率(recall)和F1值
• precision- recall曲线
2018/8/30 第 4章:关系抽取 10

剩余56页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-12-11 上传
2022-12-11 上传
2019-12-27 上传
2023-04-01 上传
2022-11-11 上传
2021-09-18 上传

每天读点书学堂
- 粉丝: 1043
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 7290d51source,c语言吃豆人源码,c语言项目
- async-lock:锁定Node.js的异步代码
- 圆圈
- xpnsqt-开源
- CSES_Problem_Set
- Crizx Stream Notifier-crx插件
- bem-detach-test
- Cinema-Room-Manager:Java项目
- 2按键加减操作_单片机C语言实例(纯C语言源代码).zip
- GREEDSNAKE,c语言库源码下载,c语言项目
- 罗德与施瓦茨 CMU200 K53 选件:罗德与施瓦茨 CMU200 K53 选件 MATLAB 仪器驱动程序-matlab开发
- Goliath:Goliath是具有用户帐户,身份验证和加密功能的ASP.NET Core 5(基于MVC)密码和秘密管理器
- 养牛365源码前端+后端
- passphrase_dice_roller:chrome扩展程序,可创建一个随机的五个单词的密码短语
- 一个简单的蓝牙应用
- 百度Android工程师面试题.zip
